OpenVLA paper를 읽어 보자!
Abstract
Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption.
- 현존하는 VLA 모델들이 대부분 폐쇄형이거나 대중에게 공개되지 않았다는 문제점,
- 그리고 실제 적용을 위해서 무척 중요한 '새로운 과제를 수행할 수 있도록 효과적으로 파인튜닝'을 하기 어려웠다는 문제점,
이를 해결할 수 있다는 OpenVLA는 과연 어떤 모델일까?
(서론 생략)
2. Related work
2-1. Visually-Conditioned Language Models
먼저 VLM의 'patch-as-token' 콘셉을 간략히 언급한다. 이 콘셉으로 인해 VLM은 시각 자료와 언어 자료를 토큰으로써 동시에 처리할 수 있게 되는 단순성을 가지고, 이러한 단순성은 곧 VLM이 새롭고 다양한 목적으로 이용되는 근간이 된다.
그렇다면 OpenVLA는 어떤 VLM을 백본으로 사용했을까?
This simplicity makes it easy to repurpose existing tools for training language models at scale for VLM training. We employ these tools in our work to scale VLA training, and specifically use VLMs from Karamcheti et al.
[44] as our pretrained backbone, as they are trained from multi-resolution visual features, fusing low-level spatial information from DINOv2 [25] with higher-level semantics from SigLIP [9] to aid in visual generalization.
- DINOv2는 self-supervised learning으로 label 없이 학습된 모델로 low-level spatial information 이해
- "Low-level" = basic visual features like edges, textures, shapes, positions
- "Spatial" = where things are located, their geometric relationships
- (Good at: precise localization, understanding fine-grained details)
- SigLIP은 image-text pairs을 가지고 contrasive learning하는 모델로 higher-level semantics 이해
- "Higher-level" = conceptual understanding, what objects are
- "Semantics" = meaning (e.g., "this is a cup", "this is dangerous")
- (Good at: recognizing objects, understanding context, connecting vision to language)
위 두 가지의 vision-encoder를 모두 사용하여 여러 장점을 Fusing하고 있는 Prismatic-7B VLM을 backbone으로 사용, 이를 통해 visual generaliztion에 도움을 받았다고 밝힌다.
2-2. Generalist Robot Policies
(제한된 로봇이 제한된 과제만을 수행하는 Specialist policy와는 달리) 다양한 로봇이 다양한 과제를 수행할 수 있도록 하는 General한 robot policy 개발의 트랜드를 언급하며, 그 비교 대상으로 Octo 모델이 제시된다. Octo 역시 Generalist robot policy로서, 다양한 로봇을 컨트롤할 수 있고, 유연한 파인튜닝이 가능하다.
A key difference between these approaches and OpenVLA is the model architecture. Prior works like Octo typically compose pretrained components such as language embeddings or visual encoders with additional model components initialized from scratch [2, 5, 6], learning to “stitch” them together during the course of policy training.
가장 큰 차이점은 모델의 아키텍처라고 밝힌다. Octo와 같은 이전 모델들은 language embedding, visual encoder과 같은 여러 개의 모델 구성 요소들을 "stitch" - 그러니까 조립해서 사용하는 반면,
Unlike these works, OpenVLA adopts a more end-to-end approach, directly fine-tuning VLMs to generate robot actions by treating them as tokens in the language model vocabulary.
OpenVLA는 좀 더 end-to-end하다는 것이다. 여러 개의 구성 요소를 이어 붙이거나 조립하지 않고 그냥 VLM을 통으로 파인튜닝할 수 있고, 이를 통해 마치 언어 토큰을 생성하듯이 robot action을 생성해낸다는 것.
이러한 방식이 더 심플하고 간편한 것은 당연하고, 나아가 이전 방식에 비해 성능도 더 좋고 generalization도 더 잘 된다고 한다.
2-3. Vision-Language-Action Models
이렇게 VLM을 end-to-end하게 학습시켜 robotics에 활용하려는 OpenVLA의 방식은 기존에 이미 연구되어 "VLA" 모델로 명명되었고, VLA 모델은 크게 아래와 같은 3개의 장점을 가진다고 밝힌다.
- VLM가 이미 학습해 둔 방대한 internet-scale vision-language dataset 지식을 활용, vision과 language를 더 조화롭게 이해할 수 있다는 장점
- 예를 들어 VLM 학습 함께 구축된 인프라를 손쉽게 활용할 수 있다던지, 코드 몇 줄 바꿔서 간단하게 모델 크기를 바꿀 수 있다던지 하는, "엔지니어링 측면"에서 누릴 수 있는 장점
- 마지막으로 VLM이 발전하면 VLA도 같이 따라서 발전할 수 있는 효율성
그렇다면 기존의 VLA와 OpenVLA의 차별성은 무엇인가?
Existing works on VLAs either focus on training and evaluating in single robot or simulated setups [72–74, 78] and thus lack generality, or are closed and do not support efficient fine-tuning to new robot setups [1, 7, 17, 18].
기존의 VLA들은 하나의 로봇이나 환경에서 학습되고 평가되면서
- generality가 부족한 단점,
- open-source로 공개되지 않는 단점,
- 효율적인 파인 튜닝을 지원하지 않는 단점을 가지고 있다.
이어서 구글의 RT-2-X (55B) 모델이 비교 대상으로 언급된다.
However, our work differs from RT-2-X in multiple important aspects: (1) by combining a strong open VLM
backbone with a richer robot pretraining dataset, OpenVLA outperforms RT-2-X in our experiments
while being an order of magnitude smaller;
첫째, OpenVLA는 더 나은 백본 VLM에다가 robot pretraining dataset을 이용해 학습을 했다. 그래서 55B인 RT-2-X보다 더 작은 크기의 모델(7B)임에도 불구하고 성능이 더 좋다.
(2) we thoroughly investigate fine-tuning of OpenVLA models to new target setups, while RT-2-X does not investigate the fine-tuning setting;
둘째, RT-2-X와 달리 OpenVLA는 친절하게도 유저가 새로운 환경에 맞는 파인튜닝을 할 수 있도록 돕는다는 것,
(3) we are the first to demonstrate the effectiveness of modern parameter-efficient fine-tuning and quantization approaches for VLAs;
셋째, 최초로 VLA 모델을 위한 파라미터 효율적인 파인튜닝 방법과 양자화 접근 방식을 다룬다는 것,
and (4) OpenVLA is the first generalist VLA that is open-source and thus supports future research on VLA training, data mixtures, objectives, and inference.
마지막으로 두 말 필요 없이 모든 게 오픈 소스라는 점!
그럼 이제 OpenVLA 모델에 대해 조금 더 본격적으로 자세히 알아보자.
3. The OpenVLA Model
3.1 Preliminaries: Vision-Language Models
앞에서 살펴봤듯, OpenVLA는 Prismatic-7B VLM를 백본으로 사용한다.
Input image patches are passed separately through both encoders and the resulting feature vectors are concatenated channel-wise. (...중략...) shown to be helpful for improved spatial reasoning [44], which can be particularly helpful for robot control.
Prismatic-7B VLM은 2장에서 언급한 바와 같이 DinoV2, SigLIP - 2가지 vision encoder를 사용하는데, input image 패치들은 두 개의 인코더를 각각 별개로 거친 다음 생성된 결과를 channel-wise하게 붙여서(concat) 하나로 사용하게 된다.
따라서 이렇게 두 가지 인코더를 모두 사용했을 때 공간 추론 능력(spatial reasoning)이 더 향상되며, 덕분에 특히 로봇 컨트롤에 더 큰 의미가 있었다고 밝히고 있다.
3.2 OpenVLA Training Procedure
To train OpenVLA, we fine-tune a pretrained Prismatic-7B VLM backbone for robot action prediction(see Fig. 2). We formulate the action prediction problem as a “vision-language” task, where an input observation image and a natural language task instruction are mapped to a string of predicted robot actions [7].
Prismatic-7B VLM을 robot action prediction에 맞게 파인튜닝하여 OpenVLA 학습을 시키는데,
- input observation image
- natural language task instruction
이 두 가지가 예측되는 로봇 행동 string에 mapping되는 방식으로 학습이 이루어진다. 그렇다면 어떻게 VLM이 output으로 a string of predicted robot actions를 출력하게 된 걸까?

To enable the VLM’s language model backbone to predict robot actions, we represent the actions in the output space of the LLM by mapping continuous robot actions to discrete tokens used by the language model’s tokenizer.
VLM의 백본 언어모델이 robot action을 예측할 수 있도록 하기 위해서, LLM이 출력할 로봇의 행동을 (VLM이 이해할 수 있도록) represent한다. - 어떻게? by mapping! 언어 모델의 "토크나이저"를 이용해 '연속적인 로봇의 행동'을 '이산적인(discrete) 토큰'으로 맵핑시키는 것이다.
Following Brohan et al. [7], we discretize each dimension of the robot actions separately into one of 256 bins. For each action dimension, we set the bin width to uniformly divide the interval between the 1st and 99th quantile of the actions in the training data.
Using quantiles instead of the min-max bounds Brohan et al. [7] used allows us to ignore outlier actions in the data that could otherwise drastically expand the discretization interval and reduce the effective granularity of our action discretization.
여러 개의 차원으로 구성되어 있는 robot action의 각 차원을 각각 이산화 시키는 방법에 대해서 생각해 보자.
예를 들어서, 쉽게 보일러의 온도를 조절하는 로봇이 존재한다고 생각해 보자. 이 로봇은 18°C에서 26°C까지 보일러의 온도를 조절할 수 있어야 한다. 로봇을 학습시키기 위해 나는 데이터셋 1,000개를 준비했다. 이 때 999개의 데이터셋은 (18°C, 26°C) 범위 안에 있는 정상 데이터이며, 1개의 데이터셋은 약 200°C의 이상치를 나타내고 있다고 가정하자. 만약 Min-max 방법을 이용해 데이터셋을 변환한다면 어떻게 될까? 가장 낮은 온도인 18°C부터 가장 높은 온도인 200°C까지 모든 데이터를 싸잡아서 256개의 구간으로 나누어 이산화를 하게 될 것이고, 이상치 하나로 인해서 각 구간의 크기가 너무 커지는 불상사가 일어날 것이다.
따라서 이를 막기 위해 OpenVLA는 이상치의 영향을 받지 않도록 1~99 quantile 기준 데이터를 기준으로 경계를 설정하고, 이를 256개의 구간으로 균등하게 나누어 이산화한 값을 사용한다는 것이다. 이렇게 ignore outlier actions하는 방법을 사용함으로써 action discretization의 granularity를 효과적으로 관리하는 것.
Instead, we again opt for simplicity and follow Brohan et al. [7]’s approach by simply overwriting the 256 least used tokens in the Llama tokenizer’s vocabulary (which corresponds to the last 256 tokens) with our action tokens.
이후에는 총 256개 종류의 로봇 액션이 이산화되지만, OpenVLA가 사용하는 Llama tokenizer에는 100개의 special token밖에 없기 때문에, Llama tokenizer가 가장 적게 사용하는 256개의 토큰 위에 로봇 액션을 덮어 씌우는 방식으로 간단하게 토크나이징을 한다고 밝히고 있다.
결국에는 이렇게 토큰화된 robot action을 output으로 출력할 수 있도록 OpenVLA가 학습되는 것이다. 간단하죠?
3.3 Training Data
We leverage the Open X-Embodiment dataset [1] (OpenX) as a base to curate our training dataset. ...(중략) To make training on this data practical, we apply multiple steps of data curation to the raw dataset.
학습용 데이터는 Open X-Embodiment raw dataset에 몇 단계의 curation을 거쳐 입맛에 맞게 수정해 사용했으며,
The goals of this curation are to ensure (1) a coherent input and output space across all training datasets, ..........(중략) To address (1), we follow [1, 5] and restrict our training dataset to contain only manipulation datasets with at least one 3rd person camera and use single-arm end-effector control.
먼저 a coherent(일관성 있는) input and output space across all training datasets을 위해 (generalist policy)
- manipulation(조작) 데이터셋만 사용하고,
- 제 3자처럼 전체를 관망할 수 있는 카메라를 최소 1대 두며,
- end-effector control로 작동하는 single-arm을 가진 로봇이어야 한다
와 같은 제한을 두었다고 한다.
(2) a balanced mix of embodiments, tasks, and scenes in the final training mixture. .........(중략) For (2), we leverage the data mixture weights of Octo [5] for all datasets that pass the first round of filtering.
또, balanced된 데이터셋을 갖추기 위해서는 기존의 Octo 모델이 사용했던 data mixture 비율을 활용해 사용했다고 밝혔다. 이 뒤에는 추가적인 데이터에 대한 실험 사실을 밝히며, appendix A에 Data Mixture 비율을 밝힌다.

3.4 OpenVLA Design Decisions
3.4.1. VLM Backbone.
최종 백본 모델을 선정하기까지 당연히 많은 실험을 거쳤을 것이다. 해당 파트에서는 백본 모델을 여러 가지 실험했으며, 최종적으 Prismatic VLM이 다른 모델보다 나았던 이유를 다시 한 번 반복 언급하고 있다.
3.4.2. Image Resolution
Input image resolution의 경우 (224, 224) 픽셀과 (384, 384) 픽셀 두 가지를 비교했을 때 퍼포먼스 차이는 없으면서 학습 시간이 더 효율적인 224 픽셀을 채택했다고 밝힌다.
3.4.3. Fine-Tuning Vision Encoder
However, we found fine-tuning the vision encoder during VLA training to be crucial for good VLA performance. We hypothesize that the pretrained vision backbone may not capture sufficient fine-grained spatial details about important parts of the scene to enable precise robotic control.
보통 기존의 VLM에서 vision encoder는 freeze하고 학습을 하는 게 국룰이라는데, 여긴 테스트 해보니까 vision encoder도 같이 파인튜닝 하는 것이 더 성능이 좋았다며, 그 이유로는 백본이 로봇 컨트롤에 충분한 수준의 높은 공간 지각 능력을 갖추지 못해서 그런 게 아닐까 가정하고 있다고 한다.
3.4.4. Training Epochs
Our final training run completes 27 epochs through its training dataset.
보통 LLM, VLM은 1~2회의 epoch으로 학습이 마무리되는 것이 일반적인데, OpenVLA는 무려 27회의 epoch에서 가장 정확도가 높았다고 한다. 굉장히 흥미돋는 포인트
3.4.5. Learning Rate
VLM pretretraining과 동일한 2e-5 사용
3.5. Infrastructure for Training and Inference
* GPT 이용해서 정리
학습 환경
- GPU: 64개 A100
- 학습 기간: 14일 (총 21,500 A100-hours)
- Batch size: 2048
추론 성능
- 메모리: 15GB (bfloat16 precision)
- 속도: ~6Hz (RTX 4090 기준)
- 최적화: Quantization으로 메모리 감소 가능 (성능 저하 없음)
4. The OpenVLA Codebase
생략
5. Experiments
OpenVLA가 powerful multi-robot control policy out of the box가 되기 위한 실험과 평가!
궁극적으로는 아래 3가지 물음에 답하는 것을 목표로 했다고 한다.
- 여러 가지 종류의 로봇, 다양한 타입의 generalization으로 평가했을 때, 이전 generalist robot policy들과 비교한 OpenVLA의 차별점은 무엇인가?
- OpenVLA는 새로운 로봇 환경과 과제에서도 효율적으로 파인튜닝될 수 있는가? 만약 그렇다면, data-efficient imitation learning(모방 학습)과 비교했을 때의 차별점은 무엇인가?
- 학습과 추론에 필요한 컴퓨팅 자원을 줄이고 접근성을 높이기 위해 OpenVLA 모델에 parameter-efficient 파인튜닝과 양자화(quantization)를 적용할 수 있는가? performance-compute 사이의 trade-offs는 어떻게 되는가?
5.1. Direct Evaluation on Multiple Robot Platforms

이전 연구에서 generalist robot policies 평가에 널리 이용된 아래 두 가지 로봇을 사용
- the WidowX robot from the BridgeData V2 evaluations (Figure 1 왼쪽 로봇)
- the mobile manipulation robot from the RT-1 and RT-2 evaluations (Figure 1 가운데 로봇, “Google robot”)
평가 항목은 아래와 같다.
- 시각적 일반화 (Visual Generalization) : 본 적 없는 배경, 방해 물체(distractors), 새로운 물체 색상이나 외형 등 시각적 변화에 대한 대응 능력
- 동작 일반화 (Motion Generalization) : 물체의 위치나 방향이 학습 데이터와 다를 때의 적응 능력
- 물리적 일반화 (Physical Generalization) : 학습 때 본 것과 다른 크기나 모양을 가진 물체를 조작하는 능력
- 의미적 일반화 (Semantic Generalization) : 학습 데이터에 없던 새로운 대상 물체, 새로운 언어 지시어, 인터넷상의 개념 등을 이해하는 능력
- 언어 그라운딩 (Language Grounding): 여러 물체가 있는 상황에서 사용자의 언어 지시어에 맞는 올바른 물체를 선택하고 조작하는 능력 (language conditioning ability in scenes with multiple objects, testing whether the policy can manipulate the correct target object, as specified in the user’s prompt.)
로봇별 세부 평가 과제는 아래와 같이 비교할 수 있다. (NotebookLM 이용하여 비교표 생성함)
|
비교 항목
|
BridgeData V2 (WidowX) 평가
|
Google Robot 평가
|
|
로봇 기종
|
WidowX 250 (6-DoF 로봇 팔, 테이블 고정형)
|
Google Robot (모바일 매니퓰레이터, RT-1/RT-2 연구에 사용됨)
|
|
평가 환경
|
장난감 주방 싱크대 (Toy Sink) 환경
|
사무실/주방 카운터 환경 (이동 가능한 플랫폼)
|
|
평가 규모
|
총 170회 (17개 과제 × 10회 시도)
|
총 60회 (12개 과제 × 5회 시도)
|
|
제어 방식
|
5Hz 비차단(Non-blocking) 제어
|
(논문에 명시된 제어 주파수 정보 없음, RT-X 모델 기반)
|
|
평가 구성
|
단일 카테고리(All OOD) 내 5가지 세부 항목 분류
|
In-Distribution (학습 데이터 분포 내) vs OOD (분포 외)로 구분
|
|
주요 평가 항목
|
1. 시각적 일반화 (Visual Gen.)
2. 동작 일반화 (Motion Gen.) 3. 물리적 일반화 (Physical Gen.) 4. 의미적 일반화 (Semantic Gen.) 5. 언어 그라운딩 (Language Grounding) |
1. 학습 분포 내 과제 (In-Distribution)
2. OOD 일반화 (배경, 물체, 지시어, 개념 등) |
|
난이도/특징
|
원래 데이터셋과 다른 위치에서 재현되어 자연스러운 분포 변화(조명, 배경 등)가 기본적으로 포함됨
|
학습 데이터에 없는 화려한 식탁보, 인터넷 사진(연예인), 새로운 물체 관계 등을 포함하여 극단적인 OOD 테스트 수행
|
|
성능 결과
|
OpenVLA가 RT-2-X(55B)를 능가 (특히 동작 및 물리적 일반화에서 우수)
|
OpenVLA와 RT-2-X가 대등한 성능 (OpenVLA 7B vs RT-2-X 55B)
|

특히 이번 장 본문에서는 7B 크기인 OpenVLA가 55B 크기인 RT-2-X보다 웃돌거나 비슷한 수준의 성능을 보이는 점을 강조하고 있다.
OpenVLA와 RT-2-X는 타 모델에 비해 모두 성능이 뛰어났는데, 두 모델이 1) 방해하는 물건이 있어도 물체에 정확히 접근한다던지, 2) 로봇의 end-effector가 목표 물체의 orientation에 잘 align한다던지, 3) 물체를 잘못 잡았을 때 다시 바로잡는다던지 등의 일을 잘 수행하는 등 성능의 퀄리티가 만족스러웠다고 한다.

특히 RT-2-X는 Figure 3에서 볼 수 있듯이 "Semantic Generalization"에서 가장 높은 점수를 기록했는데, 그 이유로 로봇 데이터만을 가지고 학습된 OpenVLA와 달리 RT-X-2가 "Internet pretraining data"를 함께 학습에 활용했기 때문이라고 추측하고 있다고.
However, OpenVLA performs comparably or better in all other task categories in both BridgeData V2 and Google robot evaluations.
어쨌든 그럼에도 불구하고 Semantic Generalization 제외하고는 전부 OpenVLA가 더 나았다고 한다.
그럼 이렇게 성능 차이가 발생한 이유는 무엇이었을까?
The performance difference can be attributed to a combination of factors: we curated a much larger training dataset for OpenVLA with 970k trajectories (vs. 350k for RT-2-X); we performed more careful cleaning of the training dataset and, e.g., filtered out all-zero actions in the Bridge dataset (see Appendix C for a detailed discussion); and OpenVLA uses a fused vision encoder that combines pretrained semantic and spatial features.
- OpenVLA는 RT-2-X보다 훨씬 방대한 양의 로봇 주행(trajectory) 데이터를 사용하여 학습
- OpenVLA: 약 **97만 개(970k)**의 궤적 사용
- RT-2-X: 약 **35만 개(350k)**의 궤적 사용
- 정교한 데이터 정제 (Careful Data Cleaning)
- 예를 들어 Bridge dataset에서 로봇 행동이 0인 데이터를 삭제하는 등
- 융합된 시각 인코더 사용 (Fused Vision Encoder)
- 여러 번 언급된 SigLIP + DINOv2 조합
요약하자면, OpenVLA는 경쟁 모델보다 더 많은 데이터를 학습했을 뿐만 아니라, 문제 상황을 미리 발견하고 데이터를 더 깨끗하게 정제했으며, 사물의 의미와 위치를 모두 잘 파악하기 위해 두 개의 시각 신경망을 합쳐서 사용했기 때문에 더 작은 모델 크기로도 더 높은 성능을 낼 수 있었다고 추측한다는 것.
5.2 Data-Efficient Adaptation to New Robot Setups
이 섹션은 OpenVLA가 사전 학습된 지식을 바탕으로, 적은 양의 데이터로 파인튜닝했을 때 새로운 로봇 하드웨어와 작업에 얼마나 잘 적응하는지 검증하는 내용.
We test a simple fine-tuning recipe for the OpenVLA model: full fine-tuning of all model parameters, using small datasets with 10–150 demonstrations of a target task ...(중략).... We test on setups with different control frequencies to test OpenVLA’s applicability to a range of use cases.
먼저 소규모 데이터를 이용해서 OpenVLA를 full fine-tuning한 뒤, 새로운 로봇에 얼마나 잘 적응하는지를 테스트한다.
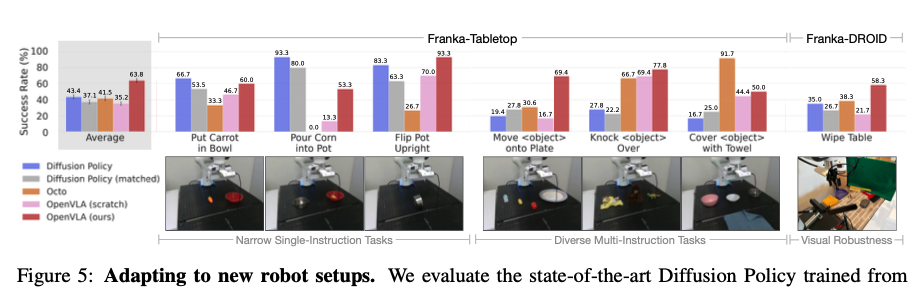
성능 검증을 위해 현재 데이터 효율성이 가장 높은 모방 학습 방법인 Diffusion Policy와, 파인 튜닝이 가능한 또 다른 generalist policy인 Octo와 비교 실험을 진행한다. 여기서 보이는 Diffusion Policy (matched)란 OpenVLA와 입출력 형태를 동일하게 맞춘 버전을 의미한다. 비교 결과를 정리하면 아래와 같다.
- 단순 작업에서의 Diffusion Policy 강세: "당근을 그릇에 넣기"와 같이 지시어가 하나뿐인 좁은 범위의 작업(narrow single-instruction tasks)에서는 Diffusion Policy가 OpenVLA나 Octo와 대등하거나 더 나은 성능을 보임
- 복잡한 언어 작업에서의 generalist policy 우위: 하지만 여러 물체가 섞여 있어 언어적 조건화(language conditioning)가 필요한 다양한 미세 조정 작업에서는 OpenVLA처럼 사전 학습된 generalist policy가 더 우수한 성능
- 대규모 사전 학습의 효과
- OpenVLA 모델 : Prismatic VLM → OpenX 로봇 데이터 970k로 학습 → 소규모 타겟 데이터 파인튜닝
- OpenVLA (scratch) 모델 : Prismatic VLM (인터넷 데이터로 사전학습된 VLM) →
OpenX 생략→ 소규모 타겟 데이터 파인튜닝 - OpenVLA scratch의 낮은 성능을 보였고, 이는 곧 OpenX 데이터셋을 통한 사전 학습이 언어 그라운딩이 중요한 작업에 모델이 더 잘 적응하도록 도왔음을 암시
사실 Open X-Embodiment로 학습하는 단계를 제거하면 성능이 떨어질 것은 좀 당연한 것 아닌가 싶어서 이 부분의 성과는 좀 과장되어 보이기는 한다. 어쨌던 결과적으로 OpenVLA가 가장 높은 평균 성능을 기록했을 뿐만 아니라, 모든 테스트 작업에서 50% 이상의 성공률을 달성한 유일한 모델로서, 다양한 언어 지시 작업의 강력한 기본 선택지(default option)임이 확인되었다는 의미가 있다고 강조하고 싶은 것 같다.
For narrower but highly dexterous tasks, Diffusion Policy still shows smoother and more precise trajectories; incorporating action chunking and temporal smoothing, as implemented in Diffusion Policy, may help OpenVLA attain the same level of dexterity and may be a promising direction for future work (see Section 6 for a detailed discussion of current limitations).
그런데 좁은 범위의 고숙련도 작업에서는 여전히 Diffusion Policy가 더 부드럽고 정밀한 궤적을 보여주었다고 한다. 정교한 동작 제어에는 아직 한계가 있는 모양이다. 향후 OpenVLA에도 액션 청킹(action chunking) 등을 도입하여 이를 개선할 필요가 있다고.
이 부분에서 Diffusion Policy에 대한 관심이 생겨서 추후 논문을 찾아 읽어보기로 했다.
5.3 Parameter-Efficient Fine-Tuning
해당 섹션에서 비교하고 있는 파인튜닝 전략들을 표로 정리하면 아래와 같다.
| 전략 | 설명 |
| Full FT | 모든 weights 업데이트 |
| Last layer only | Transformer backbone 마지막 레이어 + token embedding matrix만 |
| Frozen vision | Vision encoder 동결, 나머지 fine-tune |
| Sandwich | Vision encoder + token embedding + last layer만 fine-tune |
| LoRA | 모든 linear layer에 low-rank adaptation 적용 (r=32, 64) |
그 결과는 Table 1에 정리되어 있다.

이 실험에서 가장 중요한 발견은 vision encoder의 적응이 VLA 성능에 핵심적이라는 점이다. Last layer only나 frozen vision 전략은 성능이 크게 하락했는데, 이는 target scene에 맞게 visual feature를 적응시키는 것이 필수적임을 시사한다. 즉, 통상적인 VLM 연구에서는 vision encoder를 freeze하는 것이 일반적으로 더 좋은 성능을 보임에도 불구하고, VLA에서는 정반대의 결과가 나타난 것이다.
Sandwich fine-tuning은 모델의 양 끝단, 즉 입력 쪽의 vision encoder와 token embedding matrix, 출력 쪽의 last layer만 fine-tune하고 중간의 LLM backbone은 freeze하는 방식이다. 마치 샌드위치처럼! 이 방식은 vision encoder를 fine-tune하면서도 LLM backbone은 건드리지 않아 메모리를 절약할 수 있다는 장점이 있다. 실제로 frozen vision보다 더 나은 성능을 보였으나, LoRA에는 미치지 못했다.
전체 파라미터의 1.4%만 학습하고도 Full fine-tuning과 거의 동등한 성능(68.2% vs 69.7%)을 보인 점에 있어서, 결과적으로 LoRA가 성능과 효율성 측면에서 최적의 trade-off를 달성한 것으로 보인다. 또한 LoRA rank는 성능에 큰 영향을 미치지 않아 r=32와 r=64가 동일한 결과를 보였으며 따라서 저자들은 기본값으로 r=32를 권장한다고 밝혔다.
5.4 Memory-Efficient Inference via Quantization
OpenVLA는 7B 파라미터의 대규모 모델이기 때문에, 학습과 추론 모두에서 상당한 컴퓨팅 자원을 요구한다. 논문에서는 이러한 문제를 해결하기 위해 parameter-efficient fine-tuning과 quantization 기법을 체계적으로 검증하였다.
In this section, we test whether we can further reduce the required memory for policy inference and broaden accessibility of VLA policies, by using modern quantization techniques developed for serving LLMs [27, 88].
OpenVLA는 7B 파라미터 모델로, Octo(<100M)보다 inference 시 메모리 소모가 훨씬 크다. 기본적으로 bfloat16 precision으로 저장하면 16GB GPU에서 서빙이 가능하지만, 여기서 더 추가적인 메모리 절감을 위해 8-bit와 4-bit quantization의 효과를 검증하겠다고 말한다.

실험 결과, 4-bit quantization은 bfloat16과 동등한 성능(71.9% vs 71.3%)을 유지하면서 메모리를 58% 절감(16.8GB → 7.0GB)하였다. 반면 8-bit quantization은 58.1%로 성능이 크게 저하되었다.
그 이유는 무엇일까? 부록 <D.4 Additional Quantized Inference Experiments: Disentangling Policy Performance and Model Inference Speed> 부분을 확인해 보자.
(..중략..) and we hypothesized that the reduction in performance was caused by lower model inference speed from the operations used in 8-bit quantization.
흥미롭게도 int8의 성능 저하 원인이 inference 속도 저하에 있다는 가설을 세운다.
Specifically, we evaluate OpenVLA again with the three different levels of precision listed above, but now with blocking control. In other words, each action is fully executed on the robot before the next one is predicted by the policy and executed by the controller.
blocking control을 적용한 실험은 각 action이 완전히 실행된 후 다음 action을 예측하도록 한다. (기존의 실험은 로봇이 action을 실행하는 동안 다음 action을 예측)
필자의 가설인 "int8 성능 저하는 precision 손실이 아니라 느린 inference 속도 때문이다"를 검증하려면 inference 속도의 영향을 제거해야 한다. Blocking control을 사용하면 bfloat16, int8, int4 모두 동일한 시스템 dynamics에서 평가되므로, 순수하게 action prediction 품질만 비교할 수 있다.
결과 Table 11과 논문 본문의 실험 결과를 비교해 표로 정리하면 다음과 같다.
| Precision | Non-blocking (본문) | Blocking (부록) |
| bfloat16 | 71.3% | 70.0% |
| int8 | 58.1% | 74.4% |
| int4 | 71.9% | 68.8% |
Blocking control에서는 세 precision 모두 동등한 성능을 보였다. 가설 검증이 완료된 것이다. 즉, int8의 성능 저하 원인이 precision 손실이 아니라 inference 속도 저하라는 것이다.
즉 int8의 낮은 성능은 quantization으로 인한 정보 손실이 아니라, 느린 inference 속도가 로봇 제어 dynamics를 변화시켰기 때문이며, 실제 action prediction 품질 자체는 bfloat16와 int8이 동등하다는 것인데.. 무척 흥미로운 실험 결과였다!!!!!! 또, int4는 왜 속도 저하가 발생하지 않았을까?와 같은 의문이 생겼다.
5.4장 본문에 그 이유가 조금은 설명이 되어 있었다.
4-bit inference achieves higher throughput, since reduced GPU memory transfer compensates for the quantization overhead.
메모리 전송량과 연산 사이의 trade-off로 인한 모양이다. 즉, int8보다 더 압축된 int4는 오버헤드를 충분히 상쇄하면서도 빠른 메모리 전송량이 가능해진 것이 아닐까...
6. Discussion and Limitations
(Claude Opus 4.5를 이용해 정리)
Discussion
OpenVLA는 7B 파라미터의 오픈소스 vision-language-action 모델로, cross-embodiment 로봇 제어에서 state-of-the-art 성능을 달성했다. 특히 parameter-efficient fine-tuning을 통해 새로운 로봇 환경에 효과적으로 적응할 수 있음을 보였다.
Limitations
① 단일 이미지 입력만 지원 현재 OpenVLA는 single-image observation만 처리할 수 있다. 실제 로봇 환경은 multiple camera, proprioceptive input, observation history 등 다양한 sensory input을 활용하는데, 이를 지원하지 못하는 것은 중요한 한계이다.
② 추론 속도의 한계 ALOHA(50Hz)와 같은 고주파 제어 환경에서는 현재의 추론 속도가 부족하다. Action chunking이나 speculative decoding 등의 최적화 기법이 필요하며, 이를 통해 더 정밀한 bi-manual manipulation task로 확장할 수 있을 것이다.
③ 신뢰성 부족 대부분의 task에서 90% 미만의 성공률을 보여, 실제 배포를 위해서는 신뢰성 개선이 필요하다.
④ 미탐구 설계 질문들 컴퓨팅 한계로 인해 다음과 같은 중요한 질문들이 아직 탐구되지 않았다: base VLM 크기가 VLA 성능에 미치는 영향, 로봇 데이터와 인터넷 vision-language 데이터의 co-training 효과, VLA에 최적화된 visual feature 등. 저자들은 OpenVLA의 오픈소스 공개가 커뮤니티의 공동 연구를 통해 이러한 질문들을 해결하는 데 기여하길 기대한다.
마무리
내가 아직 Diffusion Policy에 대해 문외한이어서 그런 것일 수도 있는는데, 본 논문에서 Diffusion Policy와의 비교 실험 부분이 기억에 남는다. Diffusion Policy는 narrow single-instruction task에서 강점을 보이고, OpenVLA는 language grounding이 필요한 multi-instruction task에서 우위를 보였는데, 이는 만능 솔루션보다 task에 맞는 적절한 도구 선택이 중요함을 시사한다고 생각한다. 이어서 Diffusion Policyd에 관련된 논문을 읽어 봐야겠다.
Quantization 실험 부분도 부록과 함께 이어 읽으니 흥미로웠다. int8이 int4보다 precision은 높은데 오히려 성능이 낮았고, 그 원인이 precision 손실이 아니라 inference 속도로 인한 시스템 dynamics 변화였다는 점이 인상적이다. 로봇 제어처럼 실시간 closed-loop system에서는 모델 속도까지도 시스템의 일부로서 큰 영향을 미칠 수 있다는 중요한 교훈을 배웠다. LLM과는 다르구나!!!!!!
정리 끝!
'Data Science > DL 딥러닝' 카테고리의 다른 글
| 논문 리뷰 | CLIP-RT(2025) (4) | 2025.06.06 |
|---|---|
| DeepSeek 정복기 [3] 딥시크 V3에 대한 기본적인 이해 (1) | 2025.02.18 |
| 논문 리뷰 | RAGAS: Automated Evaluation of Retrieval Augmented Generation(2023) - RAG 평가 프레임워크 (1) | 2025.01.03 |
| 논문 리뷰 | LLM Pruning and Distillation in Practice: The Minitron Approach(2024) - 엔비디아 (4) | 2024.12.30 |
| 논문 리뷰 | DIFFERENTIAL TRANSFORMER(2024) - 마이크로소프트 (2) | 2024.12.04 |



