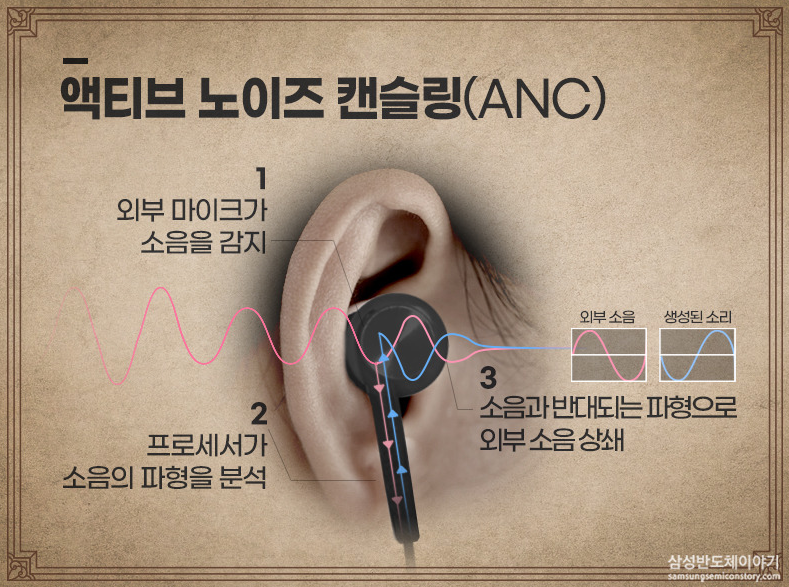
요즘 노캔기능이 대세입니다. 몇년 전까지만 해도 노캔 기능은 소니, 보스 헤드폰이 가장 인기였는데, 요즘은 에어팟과 버즈가 가장 인기가 좋은 것 같아요. 어쨌든 이 노이즈캔슬링의 원리는 생각보다 간단한데, 외부 소음과 반대되는 파형을 만들어서 더해버림으로써, 귀가 느끼는 소리가 0이 되도록 상쇄를 시켜주는 거라고 합니다.
갑자기 노캔 얘기가 왜 나왔냐 하면, 이 번에 읽은 최신 논문 DIFF트랜스포머가 이 노이즈캔슬링 원리에서 모티브를 가져왔기 때문이에요. 기존의 어탠션 맵이 1개였다면, Diff-트랜스포머는 말 그대로 어탠션 맵을 2개 만들어서 그 차이 - Difference를 계산합니다. 잘못 계산되는 Attention을 상쇄시켜줄 수 있는 역할을 한다고요.
https://arxiv.org/pdf/2410.05258

다시 말하자면, 관련 없는 Context에 어텐션이 높게 계산되는 오류를 Attention Noise로 정의하고, 이를 Cancel하기 위해 노이즈 캔슬링에서 모티브를 가져온 재밌는 최신 논문입니다. 핵심은 어텐션을 계산할 때 Q, K 벡터를 2개 그룹으로 나누고, 둘을 뺀(substract) 차이를 어텐션 맵으로 사용하는 것.
이를 통해 특히 Long-Context를 다루는 능력이 개선되었다고 하니 RAG용 모델에서 레퍼런스로 볼만합니다.
1 서론
The task is to retrieve an answer embedded in the middle of a pile of documents.
여러 개의 문서 중에서 정답이 가운데 위치했을 때 LLM이 답변을 얼마나 잘 검색하는가?를 테스트

왼쪽 - 일반 트랜스포머의 어텐션
- 맨 앞의 BOS token에 0.32
- Attention Noise는 0.18+0.34=0.52 발생
- 가운데 있는 진짜 Answer 부분에는 오직 0.03만 집중
The issue arises from non-negligible attention scores assigned to irrelevant context, which ultimately drowns out the correct answer. We term these extraneous scores as attention noise.
여기서 Attention Noise란? 정답과 관련이 없는 문서에 측정되는 어텐션 스코어를 의미 → LLM이 정답을 맞출 수 없게끔 교란하는 역할을 한다.
가운데 - Diff 트랜스포머의 어텐션
answer에 집중되는 어텐션 스코어가 0.03에서 0.31로 증가
The differential attention mechanism is proposed to cancel attention noise with differential denoising.
Differential 어텐션은 기존의 어텐션 노이즈를 상쇄시키기 위한 방법으로 제안된 새로운 트랜스포머 구조
Specifically, we partition the query and key vectors into two groups and compute two separate softmax attention maps. Then the result of subtracting these two maps is regarded as attention scores.
Q, K 벡터를 2개 그룹으로 나누고 어텐션 맵을 따로 계산한 다음 그 차이를 어텐션 스코어로 사용
The approach is analogous to noise-canceling headphones and differential amplifiers [19] in electrical engineering, where the difference between two signals cancels out common-mode noise.
노이즈 캔슬링 헤드폰에서 아이디어를 얻었다고 한다. 재밌네!
세번째 그림 - multi-needle retrieval 과제에서 정확도 차이
- Differential Transformer가 일반 트랜스포머 대비 30%p 더 높다
결과적으로…
- DIFF Transformer is highly effective in utilizing the increasing context. 롱 컨텍스트 과제에서 효율적이고
- in key information retrieval, hallucination mitigation, and in-context learning. 핵심정보 추출과 할루시네이션 줄이기, in-context learning에 효과적
- reduces outliers in model activations, which provides new opportunities for quantization. 모델 활성화에서 이상치를 줄임으로써, 양자화를 적용할 때 더 효과적일 수 있다
2장에서 더 자세히 살펴보자.
2 Differential Transformer
We take a decoder-only model as an example to describe the architecture.
연구에는 디코더 모델을 사용

서론에서 정리한 대로, Q, K 벡터를 2개 그룹으로 나누고 어텐션 맵을 따로 계산한 다음 그 차이를 어텐션 스코어로 사용하는 것을 2장 수식으로도 확인할 수 있음.
λ is a learnable scalar.
DIFF Transformer에서 중요한 또 다른 요소는 λ(람다)인데, 수식에서 람다는 학습 가능한 상수값으로, 람다를 계산하는 방법은 아래와 같다.

- where λq1 , λk1 , λq2 , λk2 ∈ R d are learnable vectors, → 이 4가지는 학습 가능한 벡터값
- and λinit ∈ (0, 1) is a constant used for the initialization of λ. → 람다 init은 고정값
- We empirically find that the setting λinit = 0.8 − 0.6 × exp(−0.3 · (l − 1)) works well in practice, → 실험해보니 요 식을 쓰는 것이 괜찮았다더라(where l ∈ [1, L] represents layer index)
즉, λ는 두 Attention 맵 간의 차이를 조정하는 가중치로, 조절을 통해 Attention가 어느 정도로 차별화될지를 결정하는 상수라고 볼 수 있다.
멀티헤드 어텐션을 자세히 보면...

- h : the number of attention heads 어텐션 헤드 수
- λ : The scalar λ is shared between heads within the same layer 고정 상수값
- WO : a learnable projection matrix 학습 가능한 projection 매트릭스
- 여러 개의 어텐션 헤드는 각각 정규화를 거쳐 ConCat되고, WO와 내적곱해진 다음, Linear를 거쳐 완성됨
- 각 Attention 헤드의 출력을 정규화하는 GroupNorm을 도입하여 Attention 헤드 간의 값 차이를 조정
- Attention 헤드가 서로 다른 값을 생성할 때 GroupNorm을 적용하면, 이 값들을 유사한 범위로 맞춰 주어 학습이 더욱 안정적으로 이루어짐 - 이를 통해 DIFF Transformer는 더 일관된 성능을 발휘하고, 복잡한 문맥 내에서 안정적인 결과를 제공
The overall architecture stacks L layers, where each layer contains a multi-head differential attention module, and a feed-forward network module.
L개의 레이어를 쌓고, 각각의 레이어는 멀티헤드 differential 어텐션 모듈을 탑재하고 있는 feed-forward 방식
3장에는 실험 결과를 여러가지 나열하는데, 간략하게 요약 정리 해보도록 하겠다.
3 Experiments
3.1 Language Modeling Evaluation
- 3B 파라미터 LLM을 1T 토큰 데이터셋으로 학습해서 실험, 비교
- 비교 모델인 OpenLLaMA-v2-3B와 StableLM-base-alpha-3B-v2 역시 1T token 데이터로 학습되었음(얘네 결과는 걔네 기술 레포트에서 가져옴)
- 결과는 아래 표와 같음. DIff-3B가 성능이 더 좋다.

3.2 Scalability Compared with Transformer
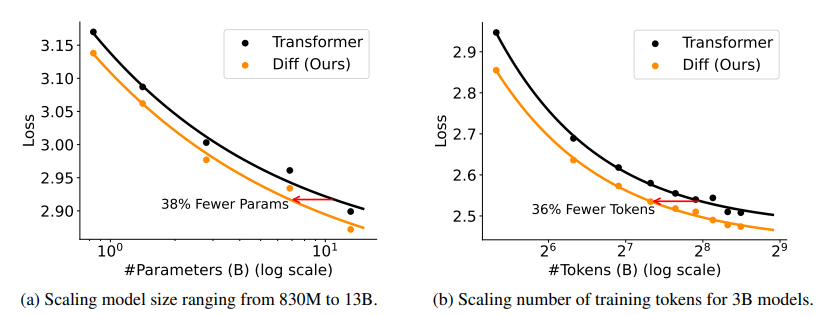
requires only about 65% of model size or training tokens to match Transformer’s performance
같은 Loss값 대비 Diff Transformer(주황색)가 더 적은 파라미터 수를 필요로 하고, 그만큼 효율적이다
3.3 Long-Context Evaluation
NLL(Negative Log-Likelihood)이란 '모델이 얼마나 잘 맞췄는지'를 '로그'와 '음수' 형태로 계산하는 함수로, 예측이 정확할수록 NLL 값은 작아지며, 부정확할수록 값이 커진다.
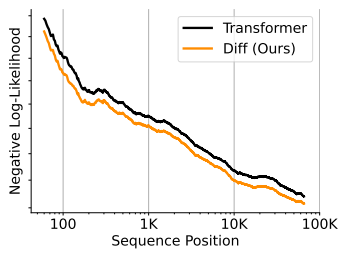
The evaluation is conducted on book data within 64K length. 평가는 64K 길이 토큰의 책 데이터로 수행, 평가 결과 DIFF Transformer(주황색)이 increasing context에 대해 더 좋은 결과
두 개의 Attention 맵 간의 차이를 계산함으로써, 긴 문맥 내에서도 중요한 정보에만 집중하게 하여 Attention noise을 줄임 - 결과적으로, DIFF Transformer는 최대 64K 토큰과 같은 매우 긴 시퀀스에서도 성능 저하 없이 문맥을 처리할 수 있었다고 함.
3.4 Key Information Retrieval
The Needle-In-A-Haystack [17] test
- is widely used to evaluate the ability to extract critical information embedded in a large context
- 큰 데이터나 문맥 내에서 중요한 정보를 추출하는 방법을 평가하는 테스트
- '바늘'은 특정 정보를 담고 있는 작은 문장이고, 이 바늘을 큰 텍스트 속에서 찾아내는 것이 과제
- https://github.com/gkamradt/LLMTest_NeedleInAHaystack/tree/main

여기서 Depth는 무엇을 의미하는가?
We compare the normalized attention scores when key information is inserted at different positions (i.e., depths) within the context.
즉, Context에서 key information이 위치한 포인트를 Depth로 표현했다
- Depth가 25~75%인 구간에서 Transformer는 Retrieval 점수가 대체로 붉고 낮은 편
- Diff Transformer는 모든 Depth에서 전반적으로 균일하고 높은 점수 분포를 보인다.
3.5 In-Context Learning
In-Context Learning은 모델이 주어진 Context를 이해하고 이를 바탕으로 답을 추론, 생성하는 능력을 의미 - 본 논문에서는 Diff-Transformer의 In-Context Learning 능력에 대해 2가지 관점에서 평가하였음
[1] Many-Shot In-Context Learning

- 실험에서는 64K 입력을 지원하는 3B 언어 모델을 사용, Transformer와 새로운 아키텍처 간의 분류 정확도를 비교
- 1-shot에서 시작하여, 샘플 수를 점차 증가시켜 총 입력 길이가 64K에 도달하도록 함
- 사용된 데이터셋은 TREC, TREC-fine, Banking-77, Clinic-150 등
- DIFF Transformer는 모든 데이터셋과 다양한 샘플 수에서 Transformer보다 일관되게 우수한 성능을 보임 - 평균 정확도 향상폭은 5.2%에서 21.6%
[2] Robustness of In-Context Learning

Given the same demonstration examples, we analyze the performance variance with order permutations.
Order permutations는 예시들의 순서를 랜덤하게 바꾸는 방법을 뜻함
Lower variance indicates greater robustness and less risk of catastrophic performance degradation.
The dash lines represent the margin between the best and worst results. Smaller margin indicates superior robustness.
- 꺾은선 그래프에서 선의 변동성이 작을수록 robust하고 risk가 적은 것을 의미함.
- 또 그래프에서 점선은 최고/최저 점수 사이의 갭을 뜻하며, 그 갭이 작을수록 Robust(강건)하다.
- Diff 트랜스포머(주황색)의 변동성이 작고 점선 사이 margin도 작은 것을 확인할 수 있다.
The results indicate that our approach is more robust for in-context learning.
우리의 연구가 더 좋다.
3.6 Contextual Hallucination Evaluation
Summarization, QA task - 입력에 올바른 사실이 포함되어 있음에도 불구하고 모델이 부정확한 출력을 생성하는 경우(Contextual Hallucination)를 평가
[1] Summarization
- 모델 출력과 실제 정답(ground-truth)를 GPT-4o에 제공
- 두 출력이 얼마나 정확한지 LLM Judge 방식으로 평가(binary)
- 출력이 정확하면 1
- 환각이 있으면 0
[2] Question-Answering
- 주어진 문맥에 대해 질문을 답하는 작업에서, DIFF Transformer와 Transformer의 환각 발생률을 비교
- DIFF Transformer는 Transformer보다 요약과 질문 응답에서 문맥적 환각을 완화하는 성능을 보였음.

결론적으로, DIFF Transformer는 Transformer보다 문맥적 환각을 줄이고, 주의 깊게 관련 정보를 다룰 수 있어 성능이 개선되었음을 시사
3.7 Activation Outliers Analysis
LLM 발생할 수 있는 활성화 이상치(activation outliers) 현상과 그 영향
- Activation Outliers : 모델 내부의 활성화 값 중에서 일반적인 값들에 비해 극단적으로 큰 값을 의미하는데, 이러한 이상치는 모델 양자화(quantization) 과정에서 문제를 일으킬 수 있음(이상치가 크면 양자화가 어려워질 수 있음)
- DIFF Transformer는 활성화 값의 크기를 조절하여, 양자화 과정에서 더 낮은 비트폭(bit-width)을 사용할 수 있게 함.
Table 5는 Transformer 모델과 DIFF Transformer 모델에서 활성화 값의 통계를 나타낸다.
- 여기서 분석되는 두 가지 유형의 활성화는 어텐션 로짓(Attention Logits)과 히든 상태(Hidden States)
- 어텐션 로짓은 모델의 어텐션 메커니즘에서 계산된 값들로, 각 토큰 간의 상호작용 정도를 나타냄
- 히든 상태는 모델의 중간 레이어에서 계산된 출력 값으로, 모델이 입력을 어떻게 처리하고 있는지를 보여줌
Table 5의 결과와 같이, DIFF Transformer는 활성화 값의 크기를 줄이는데 도움을 줌. 즉, 상위 큰 활성화 값들이 Transformer 모델에 비해 상대적으로 더 작아지기 때문에, 모델을 저비트로 양자화할 수 있는 가능성이 커짐. 이로 인해 모델의 효율성과 메모리 사용량이 개선될 수 있음.

3.8 Ablation Studies
"Ablation Studies"는 모델의 특정 부분을 "제거(ablate)"하거나 "변경"하여 성능 차이를 비교하는 방법 - 이 실험을 통해 연구자는 모델 설계에서 어떤 부분이 중요한지, 어떤 설정이 성능에 영향을 주는지 파악할 수 있음. 간단 요약하면
- 실험에서 DIFF Transformer는 Transformer와 비교해 더 낮은 전반적인 손실과 세부 손실을 보이는 강점을 보임
- DIFF Transformer의 주요 개선점은 differential attention 메커니즘에 있으며, 설정이나 정규화 모듈의 차이보다는 이 메커니즘에 의한 성능 향상이 주요한 원인이었음.
- GroupNorm은 DIFF Transformer에서 특히 중요한 역할을 함 - 여러 헤드의 통계 차이를 정상화
- λ 초기화 전략에 대해 실험한 결과, 초기화 값에 따른 성능 차이는 미미하며, 모델은 초기화 값에 대해 강건한 성능을 유지
4 Conclusion
저자들은 DIFF Transformer가 관련 있는 문맥에 집중하고 노이즈를 차단하는 차별화된 어텐션 메커니즘을 도입하여, Transformer보다 확장성, 긴 문맥 처리, 중요한 정보 검색, 환각 완화, 문맥 내 학습, 그리고 활성화 이상값 감소 등에서 우수한 성능을 보였다고 자부심을 보이며 논문을 마무리하고 있음.
연구에서는 특히 Attention Noise를 줄이는 것이 중요하다는 점을 강조하며, DIFF Transformer는 FlashAttention을 통해 쉽게 구현할 수 있다는 점도 강조함.
마무리
Diff attention의 매커니즘에 대해서 좀더 상세하게 알고 싶다면, 논문 14페이지부터 기록된 Pseudo code와 다양한 하이퍼파라미터 값, 실험 결과 등을 참고하면 좋을 것으로 보입니다.
https://github.com/microsoft/unilm/tree/master/Diff-Transformer

특히 깃허브 코드도 함께 친절하게 공개하고 있는데요. ReadMe에 위와 같이 Diff Transformer의 아키텍처에 대한 가이드라인을 이미지로 작성해 두기도 했습니다.
저 역시 주말에 시간을 내어 코드를 뜯어보고 -> 트랜스포머에서 어떤 점이 바뀌어 코드로 반영되었는지 확인해 보고자 합니다. 시간이 허락한다면 이 또한 블로그 포스팅으로 남겨 보겠습니다.
본 연구에서 읽어본 DIFF Transformer가 향후 LLM의 기초 아키텍처로 자리잡을 수 있을지 앞으로 동향을 눈여겨 살펴봐야 겠습니다.
감사합니다.



