https://arxiv.org/pdf/2407.19813
Self-Reasoning이라는 프레임워크를 통해 RAG의 성능을 높이고자 연구한 논문. 2,000개의 작은 데이터셋으로 LLM 튜닝했을 때 원하는 성과가 나왔다고 한다.
핵심 포인트만 짚어서 가볍게 논문 리뷰를 해보도록 하겠다.
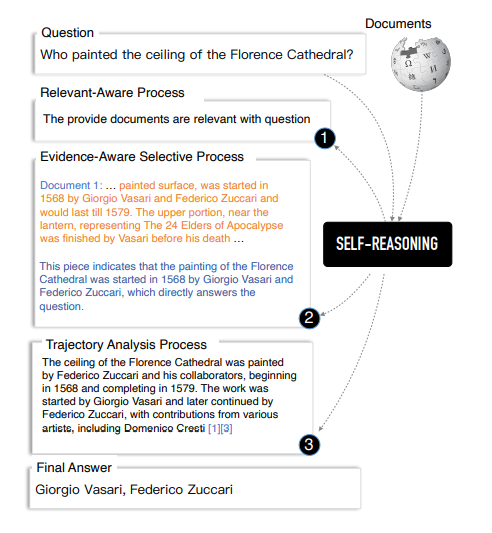
논문 리뷰에 앞서 내가 직접 이해하고 요약한 Self-Reasoning의 흐름은 아래와 같다.
- RAG의 고질병은 무관한 문서를 검색할 경우 모델 성능이 저하될 수 있으며, 인용이 명확하지 않으면 생성된 출력의 신뢰성을 검증하기 어렵다는 데에 있다.
- 그래서 본 연구는 이를 해결하기 위한 Self-Reasoning이라는 새로운 프레임워크를 제안한다. 이를 통해 관련성 높은 문서를 검색하고, 문서로부터 출처를 명확하게 인용하도록 할 수 있다고 한다.
- 이 과정이 구체적으로는 3단계(RAP → EAP → TAP)로 나뉜다.
- RAP에서는 Retrieve한 문서가 질문에 관련성이 있는지 없는지, 그 이유는 무엇인지 LLM이 생성한다.
- EAP에서는 가장 관련성이 높은 문서에서 증거(Evidence)에 해당하는 근거 문장들을 찾아내고, 그 문장을 답변의 출처로 인용해도 되는 이유를 LLM이 생성한다.
- TAP에서는 RAP와 EAP에서 생성한 모든 내용을 종합해서 질문에 대한 답변을 2가지 버전으로 출력하는데, 긴 버전을 Analysis, 짧은 버전을 answer라고 부른다.
- 이러한 Self-Reasoning이 잘 굴러가기 위해서 먼저 RAP/EAP/TAP 단계를 모두 이해하도록 LLM 파인튜닝했는데, 그 데이터는 GPT-4로 가공 후 필터링, 총 2,000개 샘플을 제작해서 사용했으며,
- 이게 chain구조로 된 꽤 어려운 task이기 때문에 각 단계마다 학습률을 다르게 설정하여 모델이 점진적으로 긴 추론 경로를 생성할 수 있도록 유도하는 '점진적 학습 방법'이라는 걸 적용했다.
- 그래서 실험을 해 보니 원하는대로 문제점이 잘 해결되더라!
Self-Reasoning Framework
전체 프로세스를 논문 Figure 2에 해당하는 아래 도식과 함께 이해하는 것이 좋음
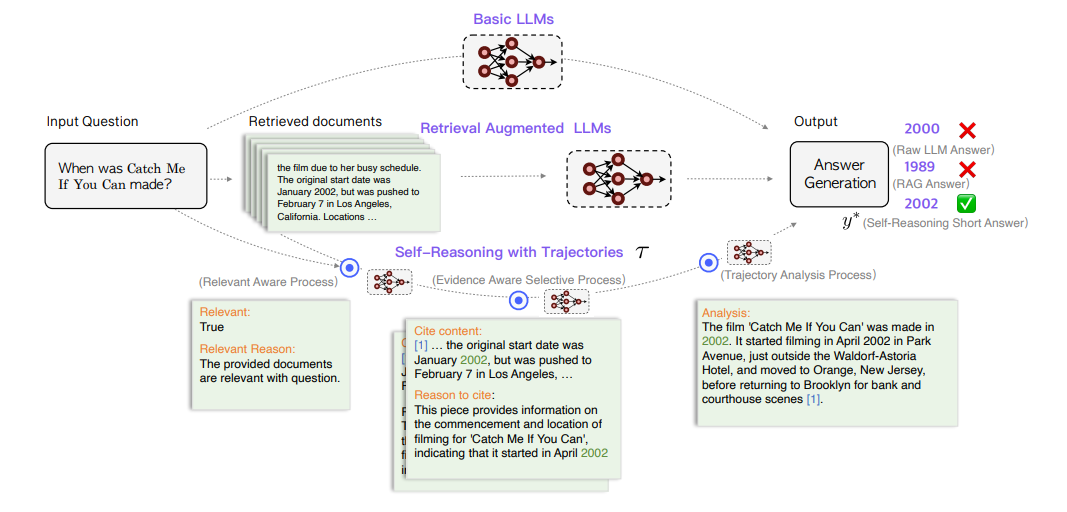
RAP(Relevance-Aware Process)
instructs the LLM to judge the relevance between the retrieved documents and the question
LLM이 검색된 문서와 질문의 관련성을 평가하도록 instruct

- 본 연구에서 top-k relevant documents를 가져오는 리트리버는 DPR()과 Contriever을 사용하였음
- LLM이 직접 retrieved된 문서 D와 주어진 질문 q와의 관련성을 판단(T/F)하고, 그에 대한 이유를 생성하게 한다. 도표에 보이는 것처럼 각각 Relevant와 Relevant Reason으로 생성됨.
- 만약 가져온 문서중에 관련 있는 문서가 하나도 없으면, LLM이 가지고 있는 내부 지식을 바탕으로 답변하는 수밖에 없음.
4.4 데이터 생성 및 품질 관리 (Data Generation and Quality Control)에 따르면, RAP단계를 위해 GPT-4로 ground truth에 해당하는 label data를 생성했다고 한다. Relevant가 True일 때에 해당하는 Positive samples뿐만 아니라 False일 때 Relevant Reason으로 why the given documents cannot answer the question - 찾아진 문서가 왜 질문에 답할 수 없는지도 답할 수 있는 Negative samples 데이터까지 균형 있게 만들었다고 함.
EAP : Evidence-Aware Selective Process
directs the LLM to choose and cite relevant documents, and then automatically select snippets of key sentences as evidence from the cited documents
LLM이 관련 문서를 선택하고 인용할 때, 인용한document로부터 snippets of key sentences를 증거로 선택하도록 direct
즉, 검색된 문서 중에서 질문에 가장 관련이 있는 문서를 우선적으로 선택하고, "증거" 문장과 함께 해당 문장이 왜 답변에 도움이 되는지에 대한 이유를 생성하도록 유도
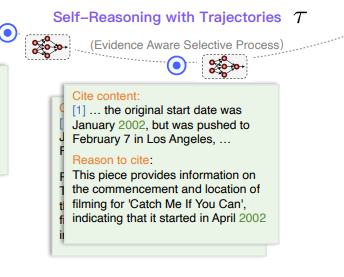
- We define the selected sentence as evidence in our paper - 관련성 있는 문서로부터 찾아낸 질문과 관계 있는 구절을 본 논문에서는 ‘evidence’라고 부름. snippets of key sentences이라고도 함. EAP 단계에서는 그 Evidence를 찾아내도록 먼저 명령을 함. 이게 곧 도식에서 cite content에 해당.
- the reason why the selected snippets can answer the question - 증거를 찾았으면, 다음 단계로는 그 증거가 왜 질문에 대한 답변이 될 수 있는지에 대한 이유를 생성하도록 함. 이는 도식에서 reason to cite에 해당.
Trajectory Analysis Process, TAP (궤적 분석 프로세스)
requires the LLM to generate a concise analysis based on all gathered self-reasoning trajectories generated by previous two processes and subsequently provide the final inferred answer.
앞의 두 과정에서 생성된 자체 추론 궤적(self-reasoning trajectories)을 분석하여 최종 답변 생성
앞의 두 과정에서 생성된 관련성 및 증거 선택 정보를 기반으로 요약된 분석을 생성하고, 최종적으로 질문에 대한 답을 도출
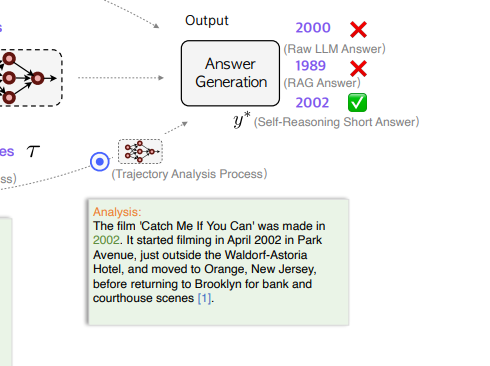
- TAP단계에서는 we ask the LLM to analyze the reasoning trajectories within itself - 지금까지 RAP, EAP 단계에서 생성한 모든 것들을 종합해서 Analysis를 최종 출력하고, and ultimately to output a concise analysis and a short answer - 최종 답변을 짧고 명확하게 도출하도록 유도함.
- 즉 최종 답변은 analysis와 answer, 두 가지 형태로 출력되는데,
- the analysis output is defined as a longform answer - analysis를 ‘롱폼 답변'으로,
- and the answer output is defined as a short-short answer - answer를 ‘숏폼 답변’으로 생각함.
마무리
실험 결과 Self-Reasoning 프레임워크는 소량의 학습 데이터(2,000개 샘플)로도 효율적인 성능을 낼 수 있음을 입증하였고
각 단계(RAP, EAP, TAP)의 개별 효과를 평가했을 때 세 가지 단계가 모두 포함된 완전한 Self-Reasoning 프레임워크가 가장 높은 성능을 나타냈다고 하는데, 특히 RAP를 제거하면 특히 사실 검증 정확도가 크게 떨어져, 관련 문서 필터링이 매우 중요함을 확인했다고 한다.
인용의 정확성과 재현율을 평가하기 위해 사람의 평가와 비교했을 때 유사한 점이 있어서 이는 Self-Reasoning이 인용의 신뢰성을 높이는 데 효과적임을 시사했다고 한다.
공식 깃허브나 코드 등이 공개되지 않아 조금 아쉽고, 실험한 모델이 좀 철 지난 모델들인 점이 또 아쉽지만, 원하는 task에 맞게 체인 형태의 논리 구조로 데이터를 가공하고 고성능의 RAG를 유도하는 아이디어 자체는 reference로 차용하기 좋은 논문인 것 같다.
끝!



