https://arxiv.org/pdf/2408.11796

논문 요약 :
1. 원본 LLM을 Teacher Correction을 통해 파인튜닝하여 교사 모델로 사용하고
2. 또 같은 원본 LLM을 Width Pruning을 통해 경량화된 학생 모델로 사용하여
3. 두 모델의 Knowledge Distillation을 통해 학생 모델을 Retrain함으로써
큰 LLM을 가장 효과적으로 경량화할 수 있는 방법론 연구
(The Minitron Approach)
Abstract, Introduction
논문 초록과 서론의 핵심 문장은 아래와 같다.
Abstract
Structured pruning with knowledge distillation is a potent combination for obtaining small language models (SLMs) with significantly fewer training tokens and compute resources compared to training from scratch.
Knowledge distillation + Structured pruning 조합으로 경량(작은) LLM을 얻을 수 있고, 이는 training from scratch에 비교했을 때 훨씬 적은 학습 토큰과 컴퓨팅 자원만 필요로 하는 장점이 있다.
We introduce a new teacher correction phase before distillation which lets the teacher model adjust to our specific data distribution using a lightweight fine-tuning phase.
본 논문에서는 Distillation(증류) 전에 '교사 교정(teacher correction)' 이라는 새로운 단계를 도입한다. 즉, 교사 역할을 하는 모델이 학생 모델을 특정 데이터 분포에 적응할 수 있게 하는데, 그 방법으로 경량화(lightweight)된 파인 튜닝 단계를 사용한다.
We apply this strategy to compress the Mistral NeMo 12B and Llama 3.1 8B models to 8B and 4B parameters, respectively, using pruning and distillation.
이 전략을 사용해서 연구진들은 Mistral NeMo 12B와 Llama 3.1 8B 모델을 각각 8B와 4B 파라미터로 압축하는 데 성공함.
Introduction
Here, only the biggest model in the family is trained from scratch; other models are obtained by successively pruning the bigger model(s) and then performing knowledge distillation [3] to recover the accuracy of pruned models.
(이 전 문장에서는 Llama3.1 8B, 70B, 405B같이 서로 다른 파라미터 수의 LLM을 각각 따로 훈련시켜서 LLM Family를 만드는 일은 매우 비효율적이라고 언급함) - 따라서 family 전체가 아니라 그냥 제일 파라미터가 큰 모델 하나만 학습시키는 것이 좋은 대안이 될 수 있다. 작은 파라미터 모델은, 큰 파라미터 모델을 pruning한 다음, knowledge distillation을 통해 accuracy를 recover하는 방식으로 얻어낼 수 있다.
While highly effective, this line of work assumes access to the original pretraining dataset for the distillation phase. With a growing number of frontier LLMs (including open ones) being trained on private, proprietary datasets [1, 4], this assumption often fails to hold.
물론 이런 방식이 매우 효과적이긴 하다. 그런데 이 방법은, distillation 단계에서 사전 학습에 사용된 데이터에 접근이 가능하다는 전제 하에 가능한 방법이다. 하지만 최근 주목받는 대규모 언어 모델들(frontier LLMs)은 점점 더 비공개 데이터셋으로 학습되는 추세이며, 이는 오픈소스 모델들도 마찬가지이다. 이러한 추세로 인해, 기존 압축 기술의 핵심 가정(원본 데이터셋 접근 가능)이 더 이상 유효하지 않은 경우가 많아지고 있다는 것.
그래서...
본 논문에서는 원본 LLM으로부터 효과적으로 경량 모델을 만들어내는 방법을 연구하며, 이러한 방법론을 Minitron Approach라고 명명한다. 본 연구의 차별점은 아래와 같다.
- 원본 LLM을 pre-train하는 데 사용된 dataset에 접근 권한이 없는 경우에도 효과적인 Knowledge Distillation이 가능하도록 Teacher Correction이라는 새로운 단계를 도입하였고, 성과가 좋았다.
- Pruning 과정에서 사용한 효과적인 깊이 가지치기 방법을 공개한다.

논문 5pg에는 Starting model로부터 각각 어떤 모델들을 어떤 방법으로 생성했는지 간략히 표기해 두고 있다.
[1] Teacher Correction (교사 모델 준비)
기존 Knowledge Distillation의 한계점
- Pruning, Knowledge Distillation 과정에 필요한 원본 LLM의 경우 사전학습에 사용된 특정 데이터셋을 가지고 있을 것이다. 그러나 경량화를 통해 만든 새로운 모델은 원본 학습 데이터와 다른 특성을 가진 새로운 데이터셋을 다루게 될 가능성이 높다.
- 또한, 기존의 Knowledge Distillation 과정에서는 주로 원본 학습 데이터셋을 사용한다. 그러나 개인정보 보호, 저작권 등의 이유로 이러한 원본 데이터셋에 접근할 수 없는 경우가 많다.
Teacher Correction은 이 논문에서 새롭게 제안된 개념으로, Pruning, Knowledge Distillation과정 이전에, 원본 LLM을 새로운 데이터셋에 맞게 살짝 fine-tuning하는 것을 의미한다. 즉, 새로운 데이터셋을 사용하므로 원본 데이터셋이 아예 필요가 없다는 것.
논문의 Training Details에 따르면,
- 사전 학습과 데이터셋은
- Llama 3.1 8B와 Mistral NeMo 12B 모델은 각각 다른 독점 데이터셋으로 사전 학습되었다.
- Llama 3.1 8B 모델은 15T 토큰으로 사전 학습되었다.
- 연구팀은 Hugging Face에서 공개적으로 사용 가능한 Base 모델들을 시작점으로 사용했다.
- 모든 가지치기(pruning)와 증류(distillation) 실험에는 Nemotron-4 큐레이션된 지속 학습(CT) 데이터셋을 사용했다.
- Teacher Correction은
- 원본 Mistral NeMo 12B 또는 Llama 3.1 8B 모델을 직접 교사 모델로 사용하면 최적의 성능을 내지 못했으며, 이를 해결하기 위해 약 100B 토큰을 사용하여 두 모델에 Teacher Correction 과정을 적용했다.
- 보정 과정에서는 원본 모델 학습에 사용된 피크 학습률의 1/5, 동일한 배치 크기, 최소 학습률, 감소 스케줄을 사용했고, 120 스텝의 웜업을 적용했다.
- 보정 과정은 교사 모델 자체의 다운스트림 태스크 정확도에 미미한 영향을 미쳤으며, 일부 태스크는 개선되고 일부는 저하되었다고 한다.
논문의 Analysis에 따르면,
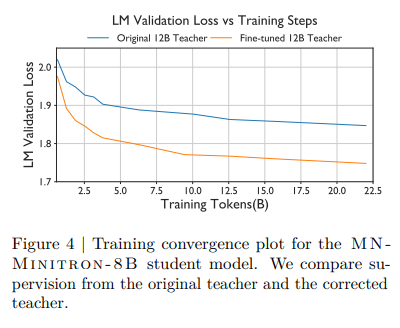
- MN-Minitron-8B 모델에 대해서 Teacher Correction을 사용한 교사모델과 / 원본 교사모델을 비교했을 때,
- 보정된 교사 모델을 사용하면 더 나은 성능을 보였다.
[2] Pruning (학생 모델 준비)
Pruning이란
Pruning이란 AI모델의 다이어트와 같다. 가지치기(Pruning) 과정에서는 각 뉴런, 어텐션 헤드, 임베딩 차원의 중요도를 계산하고, 이를 바탕으로 덜 중요한 부분을 제거한다.
본 논문에서는 연구자들은 두 가지 pruning 전략을 사용했는데,
- 깊이 가지치기: 모델의 일부 층을 완전히 제거
- 너비 가지치기: 은닉 상태, 어텐션 메커니즘, MLP 등의 차원을 줄임
논문의 Analysis에 따르면,

- 너비 가지치기가 깊이 가지치기보다 일반적으로 더 나은 성능을 보였다고 한다.
- Llama 3.1-Minitron-4B의 너비 및 깊이 가지치기 버전의 훈련 곡선을 비교했을 때, 너비 가지치기가 초기 손실이 더 낮고, 이후에도 지속적으로 깊이 가지치기 모델보다 우수한 성능을 보였다.
- 연속된 레이어 블록을 제거할 때(깊이 가지치기를 적용했을 때) LM 검증 손실이 증가하는 양상을 관찰하면, 모델의 시작과 끝 부분의 레이어가 가장 중요한 것으로 나타났다.
- 비연속적인 레이어를 제거하면(너비 가지치기를 적용하면) 더 나은 LM 검증 손실을 얻을 수 있었다.
[3] Retraining with Distillation (지식 재학습 과정)
Knowledge distillation은 한국어로는 '지식 증류'라고도 번역할 수 있다. 마치 증류를 통해 pure한 액체를 얻어 내는 것처럼, 큰 모델(선생님 모델)로부터 작은 모델(학생 모델)을 얻어내는 과정이라고 생각할 수 있다.
본 연구에서는 하나의 원본 LLM으로부터 선생님 모델과 학생 모델을 모두 얻어낸다.
- 큰 모델(선생님 모델) : Teacher Correction을 거친 교사 모델을 선생님 모델로 사용
- 작은 모델(학생 모델) : Pruning을 통해 경량화된 모델을 학생 모델로 사용
또한 본 연구에서는 Retraining with Distillation라는 표현을 쓰겠다고 명시하고 있는데,
We use the term retraining to refer to the accuracy recovery process post pruning.
Pruning에서는 가지치기(덜 중요한 부분을 제거) 이후 흔히 Recover을 하는 과정을 통해 모델의 성능을 최대한 회복하고자 시도한다.
즉, 본 논문에서는 knowledge Distillation 과정을 Retraining with Distillation으로 표현함으로써, Pruning 이후 recovery 목적으로 Distillation이 사용되었음을 드러내고자 하였다.
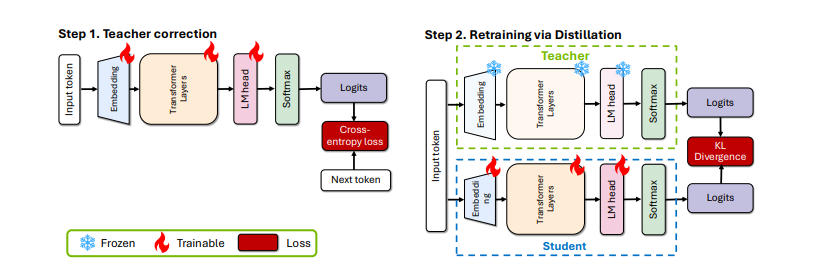
[Figure 2]에서 볼 수 있듯이, 원본 LLM을 새로운 데이터셋으로 살짝 튜닝하여 - 즉, Teacher Correction을 통해 - 선생님 모델을 준비한다. Distillation is then performed - 그 이후에 지식 전달이 수행되는데 - by minimizing KL divergence on the logits of the teacher and the pruned student model - 선생님과 학생 모델 logit의 KL divergence이 최소화 되는 방식으로 학습이 진행된다.
logit, KL divergence 이란?
- Logit은 신경망의 최종 출력층 이전의 원시 출력값으로, 아직 확률로 변환되기 전의 상태이다. KL divergence (Kullback-Leibler divergence)는 두 확률 분포 간의 차이를 측정하는 방법으로, 한 분포가 다른 분포로부터 얼마나 다른지를 나타낸다.
- 본 연구에서는 교사 모델과 학생 모델의 logit 출력을 확률 분포로 변환한 후, 이 두 분포 간의 KL divergence를 계산한다. 구체적으로는
- 교사 모델과 학생 모델의 logit 출력을 softmax 함수를 통해 확률 분포로 변환하고
- 이 두 확률 분포 간의 KL divergence를 계산하며
- 학습 과정에서 이 KL divergence를 최소화하는 방향으로 학생 모델의 파라미터를 조정한다.
이 방법을 통해 학생 모델은 교사 모델의 출력 분포를 모방하면서 지식을 전달(Retraining with Distillation)받게 된다.
논문 Evaluation 및 Insights 통합 요약
- MN-Minitron-8B 및 Llama 3.1-Minitron-4B 모델은 기존 대형 언어 모델 대비 학습 데이터 사용량을 크게 줄이면서도 뛰어난 성능을 보였다.
- MN-Minitron-8B 모델은 Mistral NeMo 12B 대비 약 40배 적은 학습 데이터(380B 토큰)를 사용하고도 동급 모델을 능가했으며, Llama 3.1-Minitron-4B 모델은 Llama 3.1 8B 대비 150배 적은 데이터(94B 토큰)로도 더 나은 성능을 기록했다.
- 특히 Width-Pruned 모델은 Depth-Pruned 모델보다 전반적으로 더 나은 정확도를 보이며, 추론 속도는 Depth-Pruned 모델이 더 빠른 것으로 나타났다.
- 모델의 최적화를 위한 Teacher Correction 과정은 새로운 데이터셋에서 distillation 효과를 극대화하는 데 필수적이며, 이를 통해 LM Validation Loss를 6% 이상 감소시켰다. 또한 Width Pruning은 Attention Heads를 유지하면서 다른 차원을 줄이는 방식으로 높은 정확도를 기록했으며, Depth Pruning은 연속적인 레이어를 제거하는 방식이 가장 효과적이었다.
- 결과적으로, 이 연구는 대규모 언어 모델을 효율적으로 축소하고 학습 데이터와 계산 리소스를 절감하면서도 높은 성능을 유지하는 방법을 제시하며, 다양한 벤치마크에서 이 방법론의 우수성을 입증했다.
마무리
본 논문은 제한된 데이터와 자원으로도 고성능 경량 모델을 효과적으로 생성할 수 있는 Pruning과 Knowledge Distillation의 실용적 접근법을 제시한다. Educational Background를 가지고 있는 내게 특히 Teacher Correction이라는 이름 명칭이 인상깊었다. 어떻게 보면 굉장히 간단한 아이디어로 효과적인 성능 개선을 이끌어냈다는 점에서 본 논문의 의의가 있을 것이고, Pruning과 Distillation을 적용하여 경량화된 모델을 생성하여 서비스하고 싶은 개발자/엔지니어들에게는 큰 가이드가 되어줄 수 있는 논문이라고 생각한다.
2025년에는 Minitron Approach를 적용한 경량화된 모델을 직접 생성해볼 기회가 있을 것으로 기대하고 있다.
끝!



