Group Relative Policy Optimization (GRPO) 알고리즘이란?
GRPO는 딥시크가 직접 개발한 강화학습 알고리즘으로, 딥시크에서 DeepSeekMath 모델과 함께 2024년 4월에 발표한 바 있다.
GRPO는 보통 정책(policy) 모델과 동일한 크기의 크리틱(critic) 모델을 두는 전통적인 강화 학습 방식과 달리, ‘그룹 점수(group scores)’를 활용하여 기준선(baseline), 즉 상대적인 보상(Advantage)을 추정함으로써 크리틱 모델을 생략하는 기법을 의미한다. 즉, DeepSeek GRPO는 강화 학습에서 정책 모델만 학습시키고, 크리틱 모델은 생략하여 연산 비용을 획기적으로 줄였다.
그렇다면 GRPO는 정책 모델은 어떻게 학습시키는 걸까? 또, 크리틱 모델 없이 어떻게 보상을 추정하는 걸까? GRPO는 한 번에 여러 정책(policy)의 결과물(출력)을 그룹(Group)으로 뽑아낸 뒤 그 상대적인 우수성을 비교(Relative)하여 최적화(Optimization)하는 방식으로 정책 모델을 학습시키며, 규칙 기반(rule-based) 방식으로 보상을 추정한다.
본 포스팅에서는 GRPO의 수식을 최대한 깊게 파고들며 이해하고자 한다. 논문에서 분해하는 수식은 DeepSeek-R1 논문의 수식을 기본으로 하되, GRPO를 처음으로 제시한 DeepSeekMath 논문을 함께 참고하여 포스팅하였다.
참고로 GRPO는 PPO(Proximal Policy Optimization)의 변형으로, PPO에 대한 이해가 선행되어 있다면 GRPO 역시 비교적 쉽게 이해할 수 있을 것이다. 필자는 PPO를 잘 모른다. 그래서 PPO에 대한 선행 이해가 없는 상태로 GRPO만 공부하였다.
논문 1) DeepSeek-R1
- <DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning>
- https://arxiv.org/pdf/2501.12948
논문 2) DeepSeekMath (GRPO 제시한 선행 논문)
- <DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models>
- https://arxiv.org/pdf/2402.03300
논문 수식 3가지

DeepSeek-R1 논문 GRPO에서 이해해야 할 수식은 위 3개이다. 하나씩 차근 차근 파헤쳐 보자.
Specifically, for each question 𝑞, GRPO samples a group of outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺} from the old policy 𝜋𝜃𝑜𝑙𝑑 and then optimizes the policy model 𝜋𝜃 by maximizing the following objective:

논문에서는 각각의 질문 q에 대해 old policy(𝜋𝜃𝑜𝑙𝑑)로부터 G개의 아웃풋 샘플을 뽑아내고, 목적 함수를 최대화하는 방식으로 policy model(𝜋𝜃)을 최적화한다고 밝히고 있다. 이 정보를 바탕으로 (1) 수식을 이해해 보자.
1-1. 기대값

E[⋅]는 기대값(Expectation)을 의미하며, 위 기댓값 식은 아래와 같이 해석할 수 있다.
- 질문 분포 P(Q)로부터 질문 q를 선택(샘플링)하여
- 기존의 정책 모델(Old Policy) - πθold(O∣q)을 사용해
- 샘플링된 질문 q에 대한 G개의 출력을 생성할 때의 기댓값

아래쪽의 GRPO 목적함수를 계산하여 학습을 진행하게 된다.
1-2. 현재 정책(𝜋𝜃)과 참조 정책(𝜋𝜃𝑜𝑙𝑑)의 비율 𝑟𝑖
먼저 이 비율을 이해해야 한다.
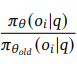
GRPO에서는 정책 모델 파라미터를 업데이트(최적화)할 때 그룹 단위를 사용한다. (그래서 이름도 Group Relative Policy Optimization)
- for each question q, 각각의 질문 q에 대해서
- GRPO samples a group of outputs {𝑜1, 𝑜2, · · · , 𝑜𝐺}, 여러 개의 아웃풋 G개를 샘플링해서 하나의 그룹으로 묶는다.
- from the old policy 𝜋𝜃𝑜𝑙𝑑 이때 아웃풋은 기존에 존재하는 정책 모델 𝜋𝜃𝑜𝑙𝑑을 사용하는 것이고
- 여러 개의 질문 데이터 q마다 그룹마다 iteration을 돌면서 정책 모델을 업데이트를 하는 것
그렇다면 GRPO 목적함수에서 이 비율 𝑟𝑖를 계산하는 이유는 무엇일까?
위 비율의 분모, 분자에 들어가는 값은 각각 확률 scalar인데, 질문 q에 대한 output G개 그룹 안에서, i번째 output을 선택할 확률을 나타낸다.
- 분모에는 𝜋𝜃𝑜𝑙𝑑, 즉 예전 정책을 사용했을 때의 확률값이 들어가고
- 분자에는 𝜋𝜃, 즉 이번 회차의 새로운 정책을 사용했을 때의 확률값이 들어간다.
- 따라서 이 비율은 지난번 정책에 비했을 때, 새로운 정책이 선택될 가능성을 나타내게 된다.
- 𝑟𝑖가 1보다 클 경우, 기존 정책에 비해 새로운 정책이 특정 행동을 선택할 확률이 더 크다는 것을 의미
- 이 비율값이 1보다 작을 경우, 새로운 정책보다 기존의 정책이 특정 행동을 선택할 확률이 더 크다는 것을 의미
- 이 값이 1인 경우, 정책의 변화가 없다는 것을 의미
즉, GRPO는 위와 같은 정책(policy) 비율(ratio)을 사용함으로써, ‘정책이 업데이트될 때 특정 행동을 선택할 확률이 얼마나 달라졌는지(증가/감소 비율)’를 직접 반영할 수 있게 된다. 이 비율값의 역할에 대한 명확한 이해가 선행되어야 GRPO의 목적 함수를 최대화하기 위한 전체 알고리즘을 이해할 수 있다.
1-3. clip 함수
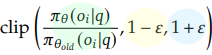
수식에서는 1-1.에서 살펴본 현재 정책과 참조 정책 사이의 비율 값에 clip을 적용한 함수를 볼 수 있다. clip 함수는 원하는 값이 너무 크거나 작아지지 않도록 특정 범위 안으로 가두어 버리는 역할을 한다.
- 초록색 : 현재 정책과 참조 정책 사이의 비율값
- 노란색 : 하한선 (만약 값이 하한선(1-ε)보다 작으면 → 하한선 값으로 변경)
- 파란색 : 상한선 (만약 값이 상한선(1+ε)보다 크면 → 상한선 값으로 변경)
𝜀 is a clipping-related hyper-parameter introduced in PPO for stabilizing training.
GRPO를 처음으로 소개한 논문 <DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models>의 4.1.1.장 "From PPO to GRPO"에서는 위와 같이 clip함수 안에 쓰인 하이퍼파라미터 𝜀가 PPO에서 사용되는 개념으로, 학습을 안정화시키는 데 사용된다고 밝히고 있다.
- 예를 들어 𝜀 = 0.2인 경우,
- 비율(초록색)이 0.8에서 1.2 사이면 그대로 유지됨
- 비율(초록색) 이 1.2를 초과하면 1.2로 잘림
- 비율(초록색) 이 0.8 미만이면 0.8로 잘림
1-4. Advantage 함수
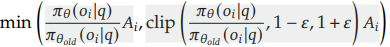
그렇다면 이제 비율 값에 각각 곱해지는 𝐴𝑖의 정체가 궁금할 차례다.
𝐴𝑖 is the advantage, computed using a group of rewards {𝑟1,𝑟2, . . . ,𝑟𝐺} corresponding to the outputs within each group
𝐴𝑖는 i번째 정책에 주어지는 advantage이며, 강화학습의 환경에서 주어지는 절대적인 보상 reward와는 조금 다른 개념으로, 실제로는 상대적인 보상, 이득을 의미한다.
𝐴ˆ𝑖,𝑡 is the advantage calculated based on relative rewards of the outputs inside each group only
DeepSeekMath 논문에서도 inside each group only에서 relative하게 계산되는 reward가 advantage임을 명시하였다.
이 보상은 아래와 같은 방정식으로 구할 수 있다.
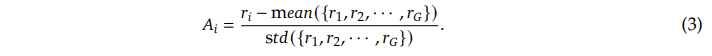
위 수식을 보면,
- 원 보상(reward 𝑟𝑖)으로부터
- 한 번의 업데이트에 사용되는 그룹(G개의 샘플)의 평균(mean) 보상값을 뺀 다음
- 여기서 평균을 빼기 때문에 평균보다 작은 𝑟𝑖를 가진 output은 음수 𝐴𝑖값을 가지게 됨!!
- 𝐴𝑖가 음수인 경우, 이는 “해당 행동(출력)이 다른 후보들에 비해 상대적으로 보상이 낮다”는 것을 의미하고
- 따라서 새로운 정책에서는 그 행동의 확률을 줄이는 방향으로 업데이트가 될 것을 시사한다.
- 여기서 평균을 빼기 때문에 평균보다 작은 𝑟𝑖를 가진 output은 음수 𝐴𝑖값을 가지게 됨!!
- 그룹(G개의 샘플)의 보상 표준편차(std)로 나누어 주어
- 보상(reward)을 상대적인 보상(Advantage)으로 정규화하여 사용하고 있음을 확인할 수 있다.
그렇다면 왜 직접적인 보상을 사용하지 않고 굳이 상대적인 보상으로 정규화하여 사용할까?
보상의 절댓값이 들쭉날쭉하거나, 극단적으로 큰/작은 샘플이 있는 등, 직접적인 보상으로 인해 학습이 불안정해질 수 있기 때문이다. 평균·표준편차 기준으로 정규화를 거친 상대적 보상 Advantage는 직접 보상 Reward보다 작은 스케일로 편차가 매우 줄어들 것이며, 그만큼 학습이 균형 잡히게 될 것이라는 것.
The reward is the source of the training signal, which decides the optimization direction of RL. To train DeepSeek-R1-Zero, we adopt a rule-based reward system that mainly consists of two types of rewards:
* Accuracy rewards : (생략)
* Format rewards : (생략)
정리하자면 딥시크는 GRPO 알고리즘을 통해 정책 모델(policy)만을 최적화하며, 보상 추정 과정에서는 딥러닝 모델을 사용하지 않는다. 대신 rule-based로 계산하는 직접 보상(Reward)을 그룹 단위로 표준화한 상대 보상(Advantage)을 사용하여 비용 효율적인 강화학습을 실현하는 것이다.
rule-based로 계산하는 Reward의 경우 논문에서 밝히는 것과 같이 Accuracy rewards와 Format rewards가 있는데, 이 부분은 pass하도록 하겠다.
1-5. min 함수
이제 정책 비율값도 이해했고, clip함수도 이해했고, Advantage도 이해했으니, min함수 전체를 보자.
이 수식에서는 (비율*𝐴𝑖), (클립한 비율*𝐴𝑖) 중에 더 작은 값(min)을 골라내고 있다. 비율 값에 상대적 보상(Advatnage)을 곱해주는 것은 어떤 의미일까? 또, 작은 것을 고르는 이유는 무엇일까?
- 정책 비율(𝑟)은 "정책이 얼마나 달라졌는가"를 나타낸다.
- 𝑟이 1보다 크면, 새 정책이 기존보다 그 행동을 더 자주 선택한다는 뜻이고,
- 1보다 작으면, 새 정책이 기존보다 그 행동을 덜 선택한다는 뜻
- Advantage는 "해당 행동이 얼마나 좋은가"를 나타낸다.
- 가 양수(>0)이면, 평균보다 더 좋은(이득이 큰) 행동이었고,
- 가 음수(<0)이면, 평균보다 덜 좋은(이득이 작은) 행동이라는 의미
- 비율(𝑟)과 Advantage(𝐴)를 곱해주는 이유는 정책이 바뀌었을 때 그 바뀐 정도가 실제로 그 행동의 이득(Advantage)에 부합하는지를 평가하기 위함이다.
- 만약 𝐴t (더 좋은 행동)이면, πθ가 그 행동을 더 많이(= 비율 > 1) 선택하도록 장려하는 것이 이득
- 만약 𝐴t <0 (덜 좋은 행동)이면, πθ가 그 행동을 덜(= 비율 < 1) 선택하도록 장려하는 것이 이득
- 즉, 두 값을 곱함으로써 “얼마나 행동 확률을 조정했는지(rtr_t)”가 “그 행동이 좋은 정도(𝐴t)”와 합치되는가를 보상 함수로 삼고, 이를 최적화하려고 하는 것.
또, 앞에서 살펴본 '비율'값이 (1-ε, 1+ε) 값에서 크게 벗어나며 심하게 요동치는 상황을 상상해 보자. 비율 값이 크게 요동친다는 것은 한 번의 업데이트에서 정책이 아주 급격하게 변한다는 것을 의미할 것이다. 이는 곧 불안정한 학습이라는 위험 요소를 의미한다. 따라서 GPRO는 이를 방지하기 위해 아래와 같은 장치를 도입한다.
- clip을 통해 비율 자체를 특정 범위 안으로 가두어 버리면, 𝐴𝑖를 곱하면서 너무 크게 보상하거나 과하게 불이익을 주게 되는 상황을 방지할 수 있고, 현재 정책이 이전 정책에서 과도하게 멀어지지 않게 된다.
- 그러나 clip만 쓴다면 너무 과도하게 업데이트를 억눌러 버릴 수가 있다. 따라서 1)클리핑한 항과 2)클리핑하지 않은 원래 항 두 값을 모두 계산하고, 그 중 더 작은(더 보수적인) 값을 목적함수로 채택(min)한다.
- 즉, ^너무 큰 이득^을 보려고 하면 -> min을 통해 클리핑된 항이 선택되며 실제 학습을 주도하게 되고, ^적당한 범위 안에서 이득을 보는 경우라면 클리핑 없는 항이 그대로 반영^되어 업데이트를 확실히 진행할 수 있게 하는 구조인 것.
이러한 알고리즘을 통해 정책 모델이 학습 도중에 업데이트되는 크기를 제한함으로써 안정적인 학습을 유도할 수 있게 된 것.
2-1. Kullback-Leibler Divergence (KL-Divergence)

KL 발산(KL-Divergence)은 ‘두 확률분포 간의 차이(얼마나 다른지)’를 나타내는 척도이다. GRPO와 같은 PPO계열의 강화학습 알고리즘에서 GRPO에서 KL-Divergence는 패널티의 개념으로 사용된다.
And different from the KL penalty term used in (2), we estimate the KL divergence with the following unbiased estimator (Schulman, 2020), which is guaranteed to be positive.
DeepSeekMath 논문에서도 KL penalty라는 표현을 명시하며 KL Divergence가 패널티의 목적으로 사용됐음을 밝히고 있는데, 또한 이 값은 guaranteed to be positive - 반드시 양수값을 가진다고 한다.
KL Divergence값이 양수임을 강조하는 이유는 무엇일까?
먼저, KL 발산은 두 확률분포가 얼마나 다른가?를 나타내는 대표적인 지표이다.
- 이 KL 발산값이 클수록, 두 정책 모델이 다른 것이고,
- 이 KL 발산값이 작을수록, 두 정책 모델이 비슷한 것이다.
그렇다면 KL-Divergence를 왜 사용하고, 이것이 어떻게 패널티의 역할을 하는가?
- πθold(o∣q) - 이전 단계에서 학습된 정책 모델(Old Policy)의 확률 분포를 의미
- πref(o∣q) - 참조 모델(Reference Policy)의 확률 분포를 의미
- 예를 들어, DeepSeek-R1-Zero에 사용된 reference policy는 DeepSeek-V3-Base 모델이 된다.

GRPO 전체 수식을 보면 min값에 KL-Divergence에 하이퍼파라미터 β를 곱해서 빼 주고 있다.
- 두 정책 모델 차이가 클수록(KL 발산값이 클수록) 감점이 많다
- 따라서 결과가 maximize되기 위해서는 KL-Divergence가 낮은 쪽으로 최적화가 진행될 것임을 예상할 수 있다.
- 결국 결론은 안정적인 학습을 추구하는 것
이제 논문에서 guaranteed to be positive라며 KL Divergence가 반드시 양수임을 강조한 이유를 알 수 있다. KL Divergence가 패널티이기 때문이다. 그 값이 양수여야 뺐을 때 감점의 역할을 할 수 있기 때문이다. (KL Divergence는 이론적으로 양수여야 하지만 이상현상에 따라 음수가 되는 경우도 있다고 한다. 그래서 Schulman의 식을 사용하며 반드시 양수인 점을 강조한 것으로 생각된다. 또한 KL Divergence 값에 곱해지는 하이퍼파라미터 β역시 양수값이어야 한다.)
3. 종합

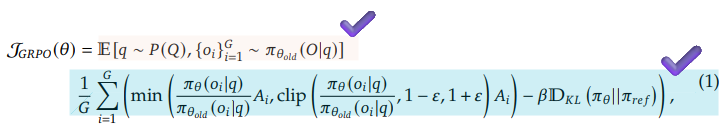
종합하자면, GRPO는
- 클리핑과 상대적 보상, 패널티를 통해 학습의 안전성을 높이고
- Group Relative Advantage Estimation을 통해 계산을 효율적으로 수행하는 강화학습의 방법으로,
- PPO와는 정책 업데이트 방식 및 샘플링 전략에서 차이가 있으며, 클리핑 기법을 활용한 안정적인 학습이라는 공통점을 가진다.
4. Pseudo code
마지막으로, DeepSeekMath 논문의 14pg Pseudo code를 통해 GRPO 알고리즘에 대한 최종 정리를 하며 글을 마무리 하겠다.

- Input : 초기 정책 모델, reward 계산 함수(rule-based), 하이퍼파라미터 𝜀, 𝛽, 𝜇
- 학습 루프를 I번 실행할 건데
- 현재 정책 모델 𝜋𝜃은 참조 모델 𝜋𝑟𝑒𝑓에서 시작을 하자 (R1의 경우 참조 모델이 V3-Base)
- 미니 배치 학습 루프를 M번 실행행을 할 건데
- 데이터셋 𝐷에서 미니배치 𝐷𝑏를 샘플링을 해가지고
- 이전 정책 모델 𝜋𝜃𝑜𝑙𝑑를 현재 모델 𝜋𝜃로 업데이트하자.
- 이 때, 각 질문 q에 대해 정책 모델 𝜋𝜃를 사용하여 G개의 출력(output)을 샘플링할 거고
- 보상 함수𝑟𝜑를 실행하여 각 샘플 output 𝑜𝑖에 대한 reward 값을 계산하는데
- 이 reward를 통해 상대적 Advantage A를 추정한다.
- 이 GRPO 최적화 루프를 𝜇번 실행한다.
- GRPO 목적 함수(Equation 21)를 최대화하여 정책 모델 𝜋𝜃를 업데이트하는 것.
- 학습된 정책 모델 𝜋𝜃를 replay mechanism을 통해 지속적으로 훈련하여 업데이트한다.
- 학습 루프를 I번 실행할 건데
- Output : 최적화된 정책 모델 𝜋𝜃
본 포스팅이
GRPO 수식을 이해하고자 하는
많은 영혼들에게 도움이 되었길 바라며...
peace out *-_-*


