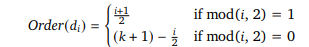RAG와 LC를 사용한 LLM의 긴 문맥 응용에 대한 가이드라인을 제공하겠다는 2024 최신 연구 논문.
최신 LLM의 max-token이 기하급수적으로 늘어나면서 Long-Context를 점점 더 잘 처리하고 있습니다. 예를 들어서 구글 Gemini 1.5의 경우 1백만 토큰까지 입력받을 수가 있고, LLama3.2 경량 모델의 경우 128K(12만8천) 토큰 입력이 가능합니다. 그래서 "RAG를 굳이 써야 될까?"라는 의문을 가진 사람도 있어요. RAG의 문제점이 많은데, 그냥 최신 LLM한테 문서를 통째로 주면 훨씬 더 일처리를 잘하니까 그렇죠. 그럼 RAG는 이제 쓸모가 없어질까?하는 의문도 들기 시작하고요.
하지만 입출력 token의 갯수에 비용이 비례하는 현재 상황에서 여전히 RAG는 cost efficiently하다는 커다란 메리트를 가지고 있고, 그래서 사람들은 연구개발을 계속하고 있습니다.
이러한 상황 속에서, 이 논문은 RAG와 Long-Context (LC) LLM을 포괄적으로 비교하여 각각의 장점을 활용할 수 있는 SELF-ROUTE라는 방법을 제안합니다.
바쁘신 분은 맨 아래 '논문 핵심 요약'만 보세요.
Abstract
We benchmark RAG and LC across various public datasets using three latest LLMs. Results reveal that when resourced sufficiently, LC consistently outperforms RAG in terms of average performance. However, RAG’s significantly lower cost remains a distinct advantage.
세 가지 최신 LLM을 사용하여 다양한 공개 데이터셋에서 RAG와 LC를 벤치마크한 결과, 충분한 자원이 있을 때 LC가 평균 성능 면에서 RAG를 일관되게 능가한다는 것을 확인, 그러나 RAG의 훨씬 낮은 비용은 여전히 독특한 이점
Based on this observation, we propose SELF-ROUTE, a simple yet effective method that routes queries to RAG or LC based on model self-reflection. SELFROUTE significantly reduces the computation cost while maintaining a comparable performance to LC.
이러한 관찰을 바탕으로, 저자들은 모델의 자체 반성을 통해 RAG나 LC로 쿼리를 라우팅하는 간단하면서도 효과적인 방법인 SELF-ROUTE를 제안. SELF-ROUTE는 계산 비용을 크게 줄이면서 LC와 유사한 성능을 유지함.
1 Introduction
Therefore, we are motivated to compare RAG and LC, evaluating both their performance and efficiency. (중략...) we find that LC consistently outperform RAG in almost all settings (when resourced sufficiently).
요즘 LLM의 max token이 기하급수적으로 늘어나면서, RAG와 Long-Context LLM을 성능과 효율성 면에서 비교하고 싶었다고 함. 그래서 비교를 해 봤더니, RAG를 쓰는 것보다, 그냥 LLM한테 통으로 문서를 줬을 때 오히려 성능이 훨씬 더 좋게 나왔다.
Despite the suboptimal performance, RAG remains relevant due to its significantly lower computational cost. In contrast to LC, RAG significantly decreases the input length to LLMs, leading to reduced costs, as LLM API pricing is typically based on the number of input tokens. Moreover, our analysis reveals that the predictions from LC and RAG are identical for over 60% of queries. For these queries, RAG can reduce cost without sacrificing performance.
그치만 RAG를 쓰면 입력 토큰이 확 줄어들기 때문에 비용 면에서 무척 효율적이라는 장점은 무시할수가 없는데, 연구를 통해 Long Context LLM과 RAG의 답변이 60%가량 일치한다는 사실을 발견했고, 연구진들은 이 정도면 RAG의 답변도 상당히 수준급이라고 생각한 모양. 이 정도면 비용 절감을 고려했을 때 RAG는 여전히 메리트 있다는 것.
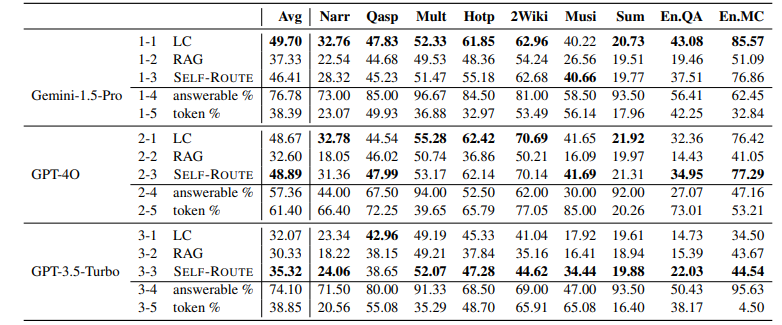
[Figure 1]을 보면 LC(Long Context LLM), RAG를 붙인 LLM, 그리고 저자들이 제안하는 Self-Route의 성능과 비용을 최신 LLM 모델별로 비교할 수가 있다. LC가 가장 비싸고 성능이 좋으며, RAG를 붙인 LLM은 싸지만 성능이 LC의 60%정도 수준이고, Self-Route는 비용이 그 중간 어디쯤에 있으며 성능은 LC에 준한다는 것.
Our analysis serves as a starting point, inspiring future improvements of RAG, and as a empirical guide for building longcontext applications using RAG and LC.
본인의 연구가 RAG의 향후 개선을 위한 출발점이자, RAG와 LC를 사용한 long-context 처리에 경험적인 가이드로서의 역할을 하기를 바란다고 함.
2 Related Work
입력 토큰 수가 많을수록 계산 비용이 기하급수적으로 증가하는 Transformer 구조의 한계 - 이를 해결하기 위해 프롬프트 압축, 모델 디스틸레이션, 단계별 모델 사용 등의 방법이 제안되어 왔음. 이후 Retrieval Augmented Generation (RAG)가 제안되었고, 최근에는 RAG의 정확성을 높이기 위해 검색 과정에 교정, 비판, 검증, 적응적 검색을 추가하는 방식이 연구됨.
Long-Context를 처리하는 LLM의 능력 평가를 위해 "LongBench", "∞Bench"와 같은 다양한 벤치마크가 제안되었으며, 이들 벤치마크는 여러 언어와 다양한 데이터셋을 포함해 긴 문맥에서의 모델 성능을 종합적으로 평가하도록 설계됨.
기존 연구에서 RAG와 LC를 비교한 결과, LC 모델이 RAG를 능가한다는 결론을 도출한 바 있음. 이 논문에서는 더 강력한 최신 LLM과 더 긴 문맥을 고려하여 다른 결과를 도출하고자 함. (Self-Route로 그 사이 절충안을 제시하는 것)
3 Benchmarking RAG versus LC
3.1 Datasets and metrics
평가 데이터
LongBench - 21개의 데이터셋으로 구성, 평균 7천 개의 단어 포함
∞Bench - 더 긴 문맥을 포함해 평균 10만 개의 토큰을 포함
연구는 영어로 된 실제 데이터를 중심으로 하고, LongBench와 ∞Bench중에서 쿼리가 포함된 데이터셋만 사용하여 총 9개의 데이터셋을 평가에 사용
평가 지표(evaluation metrics)
open-ended QA tasks - F1
multichoice QA tasks - Accuracy
summarization tasks - ROUGE
3.2 Models and Retrievers
세 가지 최신 LLM인 Gemini-1.5-Pro, GPT-4O, GPT-3.5-Turbo를 평가에 사용했으며 Retriever는 Contriever와 Dragon을 사용(청킹:300단어/top-5선택)
최신 모델을 써서 굉장히 마음에 든다
3.3 Benchmarking results
세 모델 모두에서 LC가 RAG보다 우수한 성능을 보였으며 특히 최신 모델일수록 성능 차이가 두드러졌음 - 이는 최신 LLM이 긴 문맥을 이해하는 능력이 뛰어나다는 것을 보여줌
다만, ∞Bench의 두 긴 문맥 데이터셋에서는 GPT-3.5-Turbo에서 RAG가 LC보다 우수한 성능을 보여 예외적인 결과를 보임 - 이는 이 데이터셋이 평균 147,000 단어로 이루어져 있어 모델의 최대 입력 크기를 크게 초과했기 때문
4 Self-Route
4.1 Motivation
X축은 RAG와 LC의 예측 점수 차이(𝑆_{RAG} - 𝑆_{LC})를 나타내며, 0을 기준으로 왼쪽은 LC 점수가 더 높고, 오른쪽은 RAG 점수가 더 높은 경우를 의미
그래프는 X축의 0에 상당히 집중되어 있어, 대다수의 쿼리에 대해 두 모델의 예측이 유사하게 나타난다는 것을 확인할 수 있음 - RAG and LC predictions are highly identical, for both correct and incorrect ones - 맞는 답변도 틀린 답변도 상당히 유사하다고 함
이러한 관찰을 통해 저자들은 대부분의 쿼리에 대해 비용 효율적인 RAG를 활용하고, RAG가 성능을 발휘하지 못하는 소수의 쿼리에만 LC를 적용하는 방식의 필요성을 느낌 - 이를 통해 전체 성능을 유지하면서도 계산 비용을 크게 절감할 수 있을 것으로 기대
4.2 Self-Route
SELF-ROUTE는 LLM 자체가 제공된 문맥을 통해 질문에 답할 수 있는지 스스로 반성하는 방식으로 쿼리를 라우팅 (SELF-ROUTE utilizes LLM itself to route queries based on self-reflection) - Self-Route는 아래 2단계로 작동함.
RAG-and-Route 단계
쿼리와 검색된 청크들을 LLM에 제공하고, 쿼리에 답변할 수 있는지 여부를 예측하도록 요청
만약 답변할 수 있다면, 답변을 생성
일반적인 RAG와 차이점 : LLM은 다음의 프롬프트를 통해 답변을 거부할 수 있는 옵션을 가짐 (given the option to decline answering)
“Write unanswerable if the query can not be answered based on the provided text”.
"제공된 텍스트에 기반해 쿼리를 답변할 수 없다면 'unanswerable'을 출력해라."
답변이 가능하다고 판단된 쿼리들에 대해서는 RAG 예측을 최종 답변으로 수락함
답변이 불가능하다고 판단된 쿼리들에 대해서는 두 번째 단계로 진행하여, 긴 문맥 LLM을 사용하여 최종 예측을 얻습니다. (providing the full context to the long-context LLMs to obtain the final prediction)
대부분의 쿼리는 1단계에서 해결 가능 (e.g., 82% for Gemini-1.5-Pro)
LC 예측 단계
1단계에서 "답변 불가"로 분류된 쿼리에 대해서는 긴 문맥 LLM에 전체 문맥을 제공하여 답변을 생성
4.3 Results
Table 1
모든 모델이 쿼리의 절반 이상을 RAG로 라우팅했으며, Gemini-1.5-Pro의 경우 응답 가능 비율이 81.74%에 달했음 → 이는 대부분의 쿼리를 LC 없이 RAG로 응답할 수 있음을 의미함함
높은 응답 가능 비율 덕분에 사용된 토큰 수가 크게 감소 (Table 1에서 1-5, 2-5, 3-5 token% 부분 확인)
5 Analysis
5.1 Ablations of k
RAG와 SELF-ROUTE는 쿼리 시 최상위 k개의 텍스트 청크를 검색하여 사용하는데, k 값이 증가할수록 성능이 향상되지만, 비용도 함께 증가함. 해당 연구의 경우 k=5에서 비용이 최소화 되었지만, 맡은 task와 dataset에 따라 이 부분은 직접 실험해야 할듯.
5.3 Different retrievers
연구에서 사용한 검색기 Contriever와 Dragon 모두에 대해 일관된 결과가 나왔음
논문 핵심 요약
RAG를 쓰되, 답을 찾을 수 없는 경우에는 ‘unanswerable’이라고 답하도록 프롬프팅을 함. (1단계) ⭐
1단계에서 ‘unanswerable’을 뱉는 경우는 많지 않음. 모든 모델이 쿼리의 절반 이상을 RAG로 라우팅했으며, Gemini-1.5-Pro의 경우 응답 가능 비율이 81.74%에 달했음.
만약 unanswerable이 출력되면? 리트리버로 검색된 context가 아닌 전체 full context를 LLM에게 던짐. (2단계)
그러니까 1차적으로는 일반적인 RAG를 쓰고, RAG가 제대로 안 돌아가는 경우에만 2단계로 가는 것
요즘 LLM max token이 기하급수적으로 늘어서 이게 가능함. 확인해 보니 사실 RAG를 안 쓰는게 오히려 성능은 더 좋음. 다만 이렇게 하는 이유는 RAG를 썼을 때 input token 수가 확 줄어들면서 cost friendly하기 때문이다.
전통적인 RAG 시스템은 정보 검색기(retriever)와 생성기(generator)로 구성되며, 정보 검색기가 적절한 정보를 찾으면 생성기가 답변을 구성하는 구조로 활용되었습니다. 그래서 대부분의 이전 연구들이 보통 검색기나 생성기의 성능 향상에 각각 초점을 맞추는 경향이 있어 왔는데요. 해당 포스팅에서 리뷰할 논문은 구글 클라우드에서 발표한 2024년도 최신 연구로,LLM 기반의 RAG 시스템의 안정성을 높이기 위한 방법을 제안합니다. 기존의 기조와 다르게 리트리버나 LLM의 성능보다는, 전체 RAG 시스템을 포괄적으로 분석하면서 긴 문맥을 처리하는 LLM을 생성기로 사용하는 데서 발생하는 과제와 기회를 탐구하는 논문입니다. 원하는 task에 RAG를 직접 적용해 보신 분들께서는 공감하시겠지만,실제 프로젝트에서 아직 RAG가 원하는 만큼의 성능을 100% 보여주지는 않습니다.완벽하게 제대로 동작하지 않는 경우가 많고요.....
Long-Context와 RAG
RAG를 사용하면 retrieve하는 문서가 context로 붙으면서 입력 시퀀스가 자연스레 길어지게 됩니다. context가 길수록, 여러 개일 수록 입력하는 시퀀스의 양은 많아지겠죠. 최근 LLM들은 오픈소스 경량 모델 기준으로도 최대 입력 토큰이128K가 되는 등(예 : Llama 3.2 1B & 3B 모델의 최대 입력 토큰은 128K) 처리할 수 있는 입력량이 많아지기는 했습니다.하지만 입력이 길어져도 똑같이 좋은 퀄리티의 답변을 수행하느냐?는 별개의 문제인 것 같습니다. 실험을 해 보면 context가 길어질수록 다양한 문제점이 발생하곤 합니다. RAG를 위해 모델을 train, fine-tuinig할 때도 그렇고 Inference를 수행할 때도 그렇고요. 특히 context는 길어지는데 정작 거기에 정답이 없는 경우처럼 복잡한 상황에서는 더욱 문제가 많고는 하죠. 본 논문은 앞서 말씀드린 것처럼 LLM 기반의 RAG 시스템의 안정성을 높이기 위한 방법을 제안합니다.본 논문 리뷰 포스팅이 관련 RAG 연구에 도움이 되길 바라며, 짧은 논문 리뷰를 시작하겠습니다.
논문 keyword : "hard negatives"
[1] Abstract, Introduction 초록, 서론
LLM이 많은 양의 외부 정보를 처리하는 능력이 증가하면서 RAG 성능이 향상될 가능성이 있음 그러나 실험 결과, 긴 문맥을 처리한 많은 LLM들에게서 검색된 문서 수가 증가함에 따라 성능이 처음에는 개선되다가 일정 수준 이후로는 오히려 저하되는 경향이 나타났으며, 분석 결과 "hard negatives"라 불리는 비관련 정보가 성능 저하의 주요 원인임을 밝혀냄 (LLM의 혼란이 가중되어 발생하는 문제) 본 논문에서는 이를 해결하고 LLM 기반의 RAG 시스템의 안정성을 높이기 위한 방법을 아래와 같이 3가지로 제안함
[파인튜닝 불필요❎] Retrieval Reordering ⭐⭐⭐
[파인튜닝 필요✅] Implicit Robustness Fine-tuning ⭐⭐
[파인튜닝 필요✅] Explicit Relevance Fine-tuning ⭐
⭐은 제가 임의로 경중을 나누고자 표시했으며 논문에 기재된 것이 아닙니다.
[2] Related Work 관련 연구
전통적인 RAG 시스템은 정보 검색기(retriever)와 생성기(generator)로 구성되며, 정보 검색기가 적절한 정보를 찾으면 생성기가 답변을 구성하게 됨. 따라서 이전 연구들은 보통 검색기나 생성기의 성능 향상에 초점을 맞추는 경향이 있어 왔음. 본 논문은 전체 RAG 시스템을 포괄적으로 분석하면서 긴 문맥을 처리하는 LLM을 생성기로 사용하는 데서 발생하는 과제와 기회를 탐구함.
관련 연구에 관해서는 이 정도로만 짧게 요약하고 기타 내용은 생략하겠습니다.
[3] Challenges of Long context LLMs in RAG
3.1. The Effect of retrieved context size on RAG performance
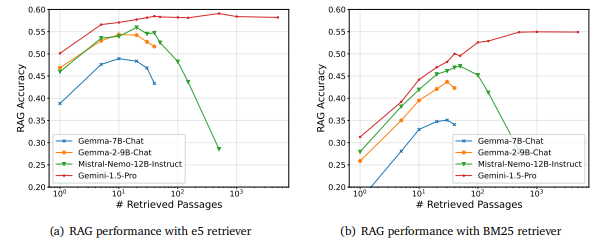
긴 문맥을 처리할 수 있는 LLM이 많은 검색된 문서를 수용할 수 있지만, 과연 이렇게 많은 정보를 포함하는 것이 항상 성능 향상으로 이어지는가? -> "아니오"
(a)와 (b)는 각각 e5와 BM25라는 두 가지 검색기를 사용, 검색된 문서 수가 증가함에 따라 여러 LLM의 성능이 어떻게 변화하는지 비교
항목
(a) e5 검색기 사용 RAG 성능
(b) BM25 검색기 사용 RAG 성능
검색기 특징
높은 리콜(Recall)을 제공하는 강력한 검색기
낮은 리콜을 제공하는 약한 검색기
성능 패턴
검색된 문서 수가 약 300개까지 증가할 때 성능이 향상되지만, 그 이후에는 성능이 하락하는 역 U자형 패턴이 나타남
검색된 문서 수가 증가함에 따라 성능이 꾸준히 향상되며, 성능 하락 구간이 거의 없음
"Hard negatives" 영향
많은 "hard negatives"로 인해 검색된 문서 수가 많아질수록 모델의 혼란이 증가하여 성능이 저하됨
"hard negatives"의 영향이 적어, 검색된 문서 수 증가가 성능 저하로 이어지지 않음
모델 간 성능 차이
모든 모델에서 Gemini-1.5-Pro가 가장 높은 성능을 보이지만, 검색된 문서 수가 많아질수록 성능 하락이 더 뚜렷하게 나타남
Gemini-1.5-Pro가 가장 높은 성능을 유지하며, 다른 모델들에 비해 검색된 문서 수 증가에 따른 성능 변화가 완만함
성능 개선 한계
검색된 문서 수가 약 300개를 넘어서면 오히려 성능이 하락하기 시작
검색된 문서 수가 많아질수록 성능이 서서히 증가하며, 성능 하락의 한계가 거의 없음
모델 추천 조합
짧은 문맥을 주로 사용하는 경우 추천
긴 문맥에서 성능 저하가 적기 때문에 다양한 문맥 길이에서 활용 가능
주요 인사이트
관련 정보가 포함되어 있어도 “hard negatives”의 존재로 인해 LLM이 정확한 답변을 생성하는 데 혼란을 줄 수 있음. 또, 더 높은 정확도와 Recall을 가진 Retriever e5가 오히려 성능 저하가 더 심각한 결과를 보임.
이는 검색 품질을 평가할 때 정확도만으로는 부족하며, 관련 없는 정보의 특성을 함께 고려해야 한다는 점을 시사
3.2. The interplay of retrieval quality and LLM capabilities
그래서 RAG의 성능 저하가 검색기의 문제인가 LLM의 문제인가? -> 둘 다의 문제입니다.
(a)와 (b)는 각각 e5와 BM25라는 두 검색기를 사용하여 검색된 문서 수가 증가함에 따라 RAG 정확도, 리콜, 정확도가 어떻게 변화하는지를 나타냄
항목
(a) e5 검색기 사용 그래프 분석
(b) BM25 검색기 사용 그래프 분석
RAG Accuracy
검색된 문서 수가 약 15개까지 증가할 때 정확도가 상승하지만, 이후에는 성능이 하락하거나 유지됨. 이는 "hard negatives"의 증가로 인해 성능이 저하되는 것을 시사
검색된 문서 수가 증가함에 따라 성능이 꾸준히 상승하거나 완만하게 변화하여, "hard negatives"의 영향을 덜 받음
리콜(Recall)
검색된 문서 수가 증가할수록 리콜이 선형적으로 상승, 더 많은 관련 정보가 검색되지만 항상 성능 향상으로 이어지지는 않음
리콜이 증가하지만 e5에 비해 완만한 속도로 증가함. 검색된 문서 수가 늘어남에 따라 관련 정보를 더 많이 포함하되, 속도가 느림
정확도(Precision)
검색된 문서 수가 증가할수록 정확도가 급격히 하락. 이는 "hard negatives"가 많이 포함되어 검색 품질이 떨어짐을 나타냄
검색된 문서 수가 늘어남에 따라 정확도가 완만하게 감소. "hard negatives"가 적게 포함되어 정확도 감소폭이 작음
모델 최적화 방향
적은 수의 문서를 검색할 때 효과적이지만, 문서 수가 많아지면 성능 저하가 발생하므로 조정이 필요
긴 문맥에서도 성능 저하가 덜 발생하여 다양한 문맥 길이에서 활용 가능
주요 인사이트
RAG 성능 저하는 검색기가 너무 많은 "hard negatives"를 포함하는 것과 LLM이 겪는 혼란이 결합하여 발생함
RAG 시스템에서 LLM 성능을 최적화하려면 검색 품질의 균형이 필요하며, 특히 "hard negatives"를 최소화하는 방향으로 검색기와 검색된 문서 수를 조정할 필요가 있음
3.3. The importance of hard negatives for long-context LLM evaluation
현재의 Long-context LLM들은 "hard negatives"에 얼마나 강인한가? -> 취약함. 사용되는 Retriever 유형에 따라 "hard negatives"의 영향이 달라지는가? -> 예.
e5 > Contriever > BM25 순으로 성능이 높은 검색기 (e5는 가장 높은 리콜)
주요 인사이트
실험 결과 Gemini-1.5-Pro가 그나마 성능 저하가 가장 덜 두드러지고 hard negatives에 대해 강한 내성을 가지고 있다고 보여짐. 그런데 이 결과는 본 논문이 구글 클라우드 연구임을 감안해서 봐야 할듯.
검색기의 유형에 따라 "hard negatives"의 영향이 다르게 나타나기 때문에 목적과 과제에 맞는 검색기 선택 중요
[4] Simple and effective training-free RAG improvement
파인튜닝 불필요❎
"Lost-in-the-middle" 현상
LLM은 입력 시퀀스의 처음과 끝 부분에 있는 정보에 더 집중하는 경향이 있으며, 중간에 있는 정보는 비교적 덜 주목하는 "lost-in-the-middle" 현상 특성을 가지고 있음 → 본 연구에서는 이를 활용하여 검색된 문서 중 높은 관련성을 가진 문서들을 입력의 앞과 뒤에 배치함으로써, 중간에 배치된 "hard negatives"의 영향을 최소화하고자 함 즉, 검색된 문서를 순서 조정하여관련성이 높은 문서를 시작과 끝에 배치하는 "Retrieval Reordering"기법을 통해 LLM이 더욱 효과적으로 중요한 정보를 처리할 수 있도록 돕는 방법을 제안함
검색된 문서를 관련성 점수를 기준으로 정렬 (d1,d2,...,dk)
높은 관련성을 가진 문서를 입력의 시작과 끝에 배치하도록 순서를 조정
구체적으로, 홀수 인덱스의 문서는 앞쪽에, 짝수 인덱스의 문서는 뒤쪽에 배치
최종 입력을 [I, d1,d3,d5,...,d4,d2,q] 형태로 구성
주요 인사이트
Retrieval reordering significantly improves RAG performance, particularly with larger numbers of retrieved passages. 검색된 문서가 많은 상황에서 특히 성능이 크게 개선됨!
즉, 검색된 문서 수가 적을 때는 효과가 미미할 수 있지만, 문서 수가 많을수록 "lost-in-the-middle" 현상과 "hard negatives"의 영향을 줄이는 데 효과적이었음
NQ와 PQA 데이터셋 모두에서 유사한 패턴을 보여, reordering 기법이 데이터셋과 모델에 상관없이 RAG 성능을 개선할 수 있는 일반적인 방법임을 확인
[5] Improving Robustness for RAG via Data-Augmented Fine-Tuning
[파인튜닝 필요✅]
5.1. Implicitly improving LLM robustness through fine-tuning
방법
모델이 불필요한 정보를 내포한 상황에서도 더 나은 성능을 발휘할 수 있도록 파인 튜닝함. 즉, "hard negatives"와 같은 관련성이 낮은 문서를 포함한 다양한 검색 컨텍스트에 LLM을 노출하여, 모델이 불필요한 정보에 대한 내성을 자연스럽게 학습 + 잡음을 인식하고 무시하는 능력을 강화
결과
불필요한 정보가 포함된 상황에서도 성능 하락이 덜하다는 점에서 "hard negatives"에 대한 내성이 향상됨
5.2. Enhancing relevance identification through reasoning augmentation
방법
추론 단계 추가: 입력 데이터를 [Instruction, Passage 1, Passage 2, ..., Passage k, Query] 형태로 제공하고, 모델은 중간 단계로 추론 단락(Reasoning Paragraph)을 생성하여 관련 문서를 식별한 후 최종 답변을 도출 - 이를 통해 모델이 관련성과 무관한 정보를 명확하게 구분하는 능력을 갖추게 됨
훈련 중에는 추론 단락의 정답 레이블이 함께 제공됨
"중간 추론"을 통해 논리적 체계를 갖추어 정보의 선별이 이루어지며, 최종적으로 답변이 생성
이 과정은 결국 두 단계의 파인튜닝을 수행하는 것과 유사함
1단계: 중간 추론 단락을 생성하여 정보의 관련성을 평가하는 능력을 키움.
2단계: 중간 추론을 바탕으로 최종 답변을 도출하여, 올바른 답변을 생성하도록 최종 파인튜닝.
결과
Explicit Relevance Fine-tuning을 통해 LLM은 노이즈와 관련 정보를 더 잘 구분, 중요 정보 분별력이 향상
[6] Data-Centric Perspectives on Fine-tuning LLMs for RAG
여긴 좀 당연한 소리 하는 파트로, 간략하게만 정리하고 넘어가겠습니다.
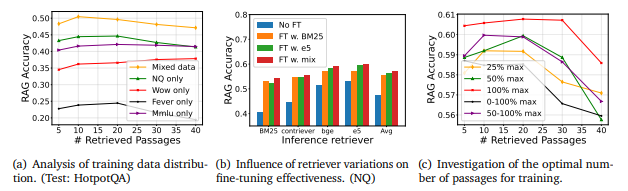
(a) 훈련 데이터 분포 분석 (Analysis of training data distribution)
여러 데이터세트(NQ, WoW, Fever, MMLU 등)를 결합한 Mixed data (혼합 데이터)로 훈련한 모델이 모든 검색 문서 수에 걸쳐 가장 높은 성능을 보임 - 단일 데이터보다 혼합 데이터를 사용한 파인튜닝이 모델의 일반화 성능을 높이는 데 더 효과적!
(b) 검색기 변화에 따른 파인튜닝 효과 (Influence of retriever variations on fine-tuning effectiveness)
서로 다른 검색기(BM25, e5, 그리고 이 둘의 혼합)를 사용해 훈련한 모델들이 다양한 검색기(BM25, Contriever, BGE, e5)를 사용할 때 얼마나 높은 정확도를 보이는지 비교 - 혼합 검색기로 파인튜닝한 모델은 모든 검색기에서 고르게 높은 성능을 보여주며, 특히 새로운 검색기(BGE)에서도 강한 적응력을 보임
(c) 최적의 훈련 문서 수 탐색 (Investigation of the optimal number of passages for training)
훈련에 사용된 문서 수의 비율(25%, 50%, 100% 등)에 따라 RAG 성능이 어떻게 달라지는가? - 최대한 많은 문서를 사용하여 파인튜닝하는 것이 RAG 성능을 일반화하고, 다양한 상황에서도 더 높은 성능을 유지하는 데 도움
[7] Conclusion
향후 연구 방향
더 정교한 위치 최적화 및 검색 순서 방법을 통해 모델의 성능을 자동으로 최적화하는 방법을 탐구
더 세분화된 다단계 추론 체인을 통한 LLM 파인튜닝을 통해 RAG 시스템의 성능을 더욱 향상시키는 방법을 연구
마무리
논문을 읽고 제가 한 생각, 배운점, 느낀점 등을 간략히 정리하면 아래와 같습니다.
Long context RAG의 경우 recall이 아주 높은 e5같은 retriever을 사용하는 것은 위험할 수 있으며, bm25같은 애들이 무난하게 작동할 수 있다. 어떤 Retriever를 선택하느냐도 항상 고민해야할 문제.
RAG를 구현할 때 retrieval reordering을 통해 hard negatives는 중간에 배치하여 LLM이 덜 주목하게 하면 모델이 Long context를 잘 처리할 수 있다.
그치만 중요한 context가 중간에 배치되어도 정확하게 답변을 출력할 수 있는 능력도 결국엔 중요하지 않을까? 파인튜닝을 하지 않기 위해 RAG가 도입되었지만 결국 완벽한 RAG는 적절한 파인튜닝이 필수적으로 요구되는듯..
또 파인튜닝을 1단계로 하지 않고 2단계로 나누어서 처음에 ‘중간 추론 단계’라는 걸 넣어주면 좋다는데 이것은 자원의 한계를 고려해서 실행해야 할 듯 하다.
포스팅 내 잘못된 정보가 있다면 댓글 남겨주시기 바라며, 이번 포스팅을 읽어주셔서 감사합니다. 지금까지 사이언티스트 수리링이었습니다 :)
Self-Reasoning이라는 프레임워크를 통해 RAG의 성능을 높이고자 연구한 논문. 2,000개의 작은 데이터셋으로 LLM 튜닝했을 때 원하는 성과가 나왔다고 한다.
핵심 포인트만 짚어서 가볍게 논문 리뷰를 해보도록 하겠다.
논문 리뷰에 앞서 내가 직접 이해하고 요약한 Self-Reasoning의 흐름은 아래와 같다.
RAG의 고질병은 무관한 문서를 검색할 경우 모델 성능이 저하될 수 있으며, 인용이 명확하지 않으면 생성된 출력의 신뢰성을 검증하기 어렵다는 데에 있다.
그래서 본 연구는 이를 해결하기 위한 Self-Reasoning이라는 새로운 프레임워크를 제안한다. 이를 통해 관련성 높은 문서를 검색하고, 문서로부터 출처를 명확하게 인용하도록 할 수 있다고 한다.
이 과정이 구체적으로는 3단계(RAP → EAP → TAP)로 나뉜다.
RAP에서는 Retrieve한 문서가 질문에 관련성이 있는지 없는지, 그 이유는 무엇인지 LLM이 생성한다.
EAP에서는 가장 관련성이 높은 문서에서 증거(Evidence)에 해당하는 근거 문장들을 찾아내고, 그 문장을 답변의 출처로 인용해도 되는 이유를 LLM이 생성한다.
TAP에서는 RAP와 EAP에서 생성한 모든 내용을 종합해서 질문에 대한 답변을 2가지 버전으로 출력하는데, 긴 버전을 Analysis, 짧은 버전을 answer라고 부른다.
이러한 Self-Reasoning이 잘 굴러가기 위해서 먼저 RAP/EAP/TAP 단계를 모두 이해하도록 LLM 파인튜닝했는데, 그 데이터는 GPT-4로 가공 후 필터링, 총 2,000개 샘플을 제작해서 사용했으며,
이게 chain구조로 된 꽤 어려운 task이기 때문에 각 단계마다 학습률을 다르게 설정하여 모델이 점진적으로 긴 추론 경로를 생성할 수 있도록 유도하는 '점진적 학습 방법'이라는 걸 적용했다.
그래서 실험을 해 보니 원하는대로 문제점이 잘 해결되더라!
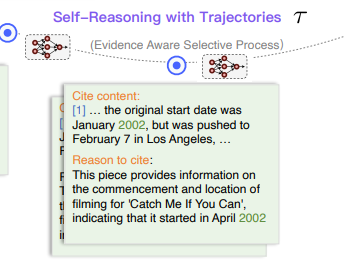
Self-Reasoning Framework
전체 프로세스를 논문 Figure 2에 해당하는 아래 도식과 함께 이해하는 것이 좋음
RAP(Relevance-Aware Process)
instructs the LLM to judge the relevance between the retrieved documents and the question
LLM이 검색된 문서와 질문의 관련성을 평가하도록 instruct
본 연구에서 top-k relevant documents를 가져오는 리트리버는 DPR()과 Contriever을 사용하였음
LLM이 직접 retrieved된 문서 D와 주어진 질문 q와의 관련성을 판단(T/F)하고, 그에 대한 이유를 생성하게 한다. 도표에 보이는 것처럼 각각 Relevant와 Relevant Reason으로 생성됨.
만약 가져온 문서중에 관련 있는 문서가 하나도 없으면, LLM이 가지고 있는 내부 지식을 바탕으로 답변하는 수밖에 없음.
4.4 데이터 생성 및 품질 관리 (Data Generation and Quality Control)에 따르면, RAP단계를 위해 GPT-4로 ground truth에 해당하는 label data를 생성했다고 한다. Relevant가 True일 때에 해당하는 Positive samples뿐만 아니라 False일 때 Relevant Reason으로 why the given documents cannot answer the question - 찾아진 문서가 왜 질문에 답할 수 없는지도 답할 수 있는 Negative samples 데이터까지 균형 있게 만들었다고 함.
EAP : Evidence-Aware Selective Process
directs the LLM to choose and cite relevant documents, and then automatically select snippets of key sentences as evidence from the cited documents
LLM이 관련 문서를 선택하고 인용할 때, 인용한document로부터 snippets of key sentences를 증거로 선택하도록 direct
즉, 검색된 문서 중에서 질문에 가장 관련이 있는 문서를 우선적으로 선택하고, "증거" 문장과 함께 해당 문장이 왜 답변에 도움이 되는지에 대한 이유를 생성하도록 유도
We define the selected sentence as evidence in our paper - 관련성 있는 문서로부터 찾아낸 질문과 관계 있는 구절을 본 논문에서는 ‘evidence’라고 부름. snippets of key sentences이라고도 함. EAP 단계에서는 그 Evidence를 찾아내도록 먼저 명령을 함. 이게 곧 도식에서 cite content에 해당.
the reason why the selected snippets can answer the question - 증거를 찾았으면, 다음 단계로는 그 증거가 왜 질문에 대한 답변이 될 수 있는지에 대한 이유를 생성하도록 함. 이는 도식에서 reason to cite에 해당.
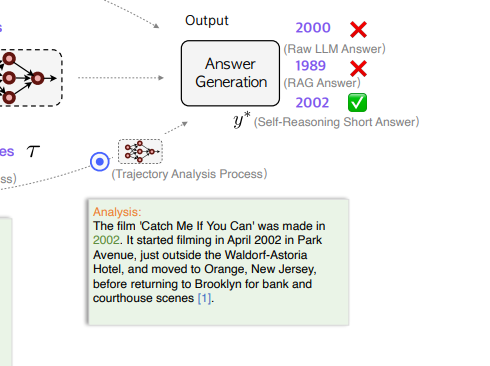
Trajectory Analysis Process, TAP (궤적 분석 프로세스)
requires the LLM to generate a concise analysis based on all gathered self-reasoning trajectories generated by previous two processes and subsequently provide the final inferred answer.
앞의 두 과정에서 생성된 자체 추론 궤적(self-reasoning trajectories)을 분석하여 최종 답변 생성
앞의 두 과정에서 생성된 관련성 및 증거 선택 정보를 기반으로 요약된 분석을 생성하고, 최종적으로 질문에 대한 답을 도출
TAP단계에서는 we ask the LLM to analyze the reasoning trajectories within itself - 지금까지 RAP, EAP 단계에서 생성한 모든 것들을 종합해서 Analysis를 최종 출력하고, and ultimately to output a concise analysis and a short answer - 최종 답변을 짧고 명확하게 도출하도록 유도함.
즉 최종 답변은 analysis와 answer, 두 가지 형태로 출력되는데,
the analysis output is defined as a longform answer - analysis를 ‘롱폼 답변'으로,
and the answer output is defined as a short-short answer - answer를 ‘숏폼 답변’으로 생각함.
마무리
실험 결과 Self-Reasoning 프레임워크는 소량의 학습 데이터(2,000개 샘플)로도 효율적인 성능을 낼 수 있음을 입증하였고
각 단계(RAP, EAP, TAP)의 개별 효과를 평가했을 때 세 가지 단계가 모두 포함된 완전한 Self-Reasoning 프레임워크가 가장 높은 성능을 나타냈다고 하는데, 특히 RAP를 제거하면 특히 사실 검증 정확도가 크게 떨어져, 관련 문서 필터링이 매우 중요함을 확인했다고 한다.
인용의 정확성과 재현율을 평가하기 위해 사람의 평가와 비교했을 때 유사한 점이 있어서 이는 Self-Reasoning이 인용의 신뢰성을 높이는 데 효과적임을 시사했다고 한다.
공식 깃허브나 코드 등이 공개되지 않아 조금 아쉽고, 실험한 모델이 좀 철 지난 모델들인 점이 또 아쉽지만, 원하는 task에 맞게 체인 형태의 논리 구조로 데이터를 가공하고 고성능의 RAG를 유도하는 아이디어 자체는 reference로 차용하기 좋은 논문인 것 같다.
pre-train된 LLM은 학습한 시점 이후의 데이터를 가지고 있지 않기때문에 outdated된 정보를 제공할 수 있으며 특히 domain-specific한 지식이 부족한 단점을 가지고 있습니다. 이를 보완하기 위해 주기적으로 LLM을 재학습시키거나 파인튜닝을 하는 방법이 고안되었지만 시간이나 비용적인 측면에서 비효율적이라는 문제점이 꾸준히 제기되어 왔습니다.
저 역시 domain-specific한 QA task를 실현하기 위해 LLM을 fine-tuning하고자 하는 시도를 하였지만 생각만큼 성능이 잘 확보되지 않으며 오히려 기존에 학습된 파라미터가 fine-tuning을 통해 망가지면서 답변 생성 성능이 저하되는 것을 여러번 경험한 바가 있습니다. 이럴 때 필요한 것이 RAG - Retrieval-Augmented Generation - 검색 증강 생성으로, LLM을 더 잘 활용하기 위해 널리 사용되고 있는 기술입니다.
RAG는 새로운 정보를 벡터 데이터베이스에 저장하고, 쿼리를 받았을때 데이터베이스에서 검색을 실행합니다. 이후 반환받은 관련 정보를 쿼리에 함께 담아 넘겨주면서 context 정보를 구체적으로 제공함으로써 기존의 문제점을 해결하고자 도모합니다.
본 포스팅에서는 RAG에 관해 처음으로 언급한 논문 <Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks>를 읽고 주요 내용을 리뷰해 보도록 하겠습니다.
Abstract
Large pre-trained language models have been shown to store factual knowledge in their parameters, and achieve state-of-the-art results when fine-tuned on downstream NLP tasks. However, their ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems. (중략)
LLM은 많은 NLP task에서 SoTA 성능을 보여주며 다양하게 활용되어 왔지만, 지식을 습득하고 조종하는 부분에 있어 여전히 많은 한계점을 가지고 있습니다. 저 역시 개인적인 목적으로 GPT4.0등을 활용할 때와 달리 프로젝트를 위해 오픈소스 LLM 등을 활용할 때 특히 그러한 한계점을 많이 체감하게 되곤 했는데요. 특히 task-specific한 구조로 인해서 knowledge-intensive한 task에 있어서는 취약한 점이 많았죠. 나아가 결정에 대한 출처를 제공하는 일, 기존의 지식을 업데이트하는 일은 여전히 미해결 연구 문제로 남아 있었다고 합니다.
We explore a general-purpose fine-tuning recipe for retrieval-augmented generation (RAG) — models which combine pre-trained parametric and non-parametric memory for language generation. We introduce RAG models where the parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever.
해당 논문에서는 2가지 종류의 knowledge를 사용하고 있습니다.
Parametric knowledge : 모델이 사전에 학습한 파라미터 정보
Non-parametric knowledge : retriever를 이용하여 외부 문서로부터 가져오는 파라미터 정보 (논문에서는 Wikipedea 활용)
그런데 논문에서 말하는 general-purpose fine-tuning recipe for RAG란 무엇일까요?
이어서 살펴보겠지만 RAG 모델의 파인튜닝은 리트리버와 생성기를 함께 엔드-투-엔드로 학습하여 모델을 최적화하는 과정을 의미합니다. 오늘날 우리가 RAG를 구현할 때는 이미 학습된 리트리버와 생성기를 LangChain과 같은 라이브러리에서 가져다 사용하기 때문에 별도의 파인튜닝 과정은 사실 필요 없습니다. 덕분에 보다 손쉽게 RAG 기능을 구현할 수 있는 것이죠. 물론 파인튜닝을 추가해서 더 고도화된 모델을 구현할 수도 있겠지만요.
We compare two RAG formulations, one which conditions on the same retrieved passages across the whole generated sequence, and another which can use different passages per token. (중략) For language generation tasks, we find that RAG models generate more specific, diverse and factual language than a state-of-the-art parametric-only seq2seq baseline.
본 논문에서는 2가지의 RAG 포뮬라를 비교 제시하는데요. 하나는 생성된 전체 시퀀스에 걸쳐 동일한 검색된 구절을 조건으로 하고, 다른 하나는 토큰당 다른 구절을 사용합니다. 이를 통해 생성 작업에 있어서 RAG 모델이 더 구체적이고 다양하며 사실에 기반한 언어를 생성한다는 사실을 발견했다고 합니다.
1 Introduction
They cannot easily expand or revise their memory, can’t straightforwardly provide insight into their predictions, and may produce “hallucinations”. (중략)
기존의 Pre-train된 neural language model들은 파라미터에 저장된 정보를 이용하여 훌륭한 답변을 생성해 내곤 하였는데요. 하지만 이러한 모델들은 기억을 쉽게 확장하거나 수정할 수 없는 단점, 예측에 대한 통찰력을 직접적으로 제공할 수 없는 단점, 그리고 가장 치명적으로 "환각(Hallucinations)"을 일으킬 수 있는 단점을 가지고 있었습니다.
The retriever (Dense Passage Retriever [26], henceforth DPR) provides latent documents conditioned on the input, and the seq2seq model (BART [32]) then conditions on these latent documents together with the input to generate the output. We marginalize the latent documents with a top-K approximation, either on a per-output basis (assuming the same document is responsible for all tokens) or a per-token basis (where different documents are responsible for different tokens). Like T5 [51] or BART, RAG can be fine-tuned on any seq2seq task, whereby both the generator and retriever are jointly learned.
Retriever는 인풋을 받아latent documents을 제공하고, seq2seq 모델은 이러한 문서들을 묶어서 출력을 생성합니다. RAG는 잠재 문서(latent documents)들 중에서 상위 K개의 문서를 선택(top-K approximation)하여 이 문서들에 기반해 출력을 생성하는데, 이 과정은 두 가지 방식으로 이루어질 수 있습니다. 예시 질문 "팥빙수를 맛있게 만드는 방법은?"을 가지고 각각의 방법이 어떻게 사용되는지 구체화 해보도록 하겠습니다.
출력 단위로(per-output basis): 하나의 문서가 모든 토큰에 대해 사용된다고 가정.
모델이 가장 관련성 높은 문서 1개를 찾습니다. 예를 들어, 한 문서가 '팥빙수 레시피' 전체를 담고 있다고 가정합니다. 그 문서에서 얻은 모든 정보를 바탕으로 답변을 생성합니다.
답변: "팥빙수를 맛있게 만들려면, 먼저 팥을 준비하고, 얼음을 갈아 위에 얹습니다. 그 다음, 연유와 다양한 토핑을 추가합니다."
토큰 단위로(per-token basis): 각 토큰이 서로 다른 문서에 의해 지원될 수 있음.
모델이 여러 문서를 찾습니다. 만약 한 문서는 '팥 조리법'을 설명하고, 또 다른 문서는 '팥빙수 토핑 아이디어'를 제공한다면, 각 단어(토큰)를 생성할 때 가장 적절한 문서에서 해당하는 정보를 가져옵니다. 예를 들어, 첫 번째 문서에서 "팥을 준비하고" 정보를 가져오고, 두 번째 문서에서 "얼음을 갈아 얹고" 정보를 가져오며, 세 번째 문서에서 "연유와 다양한 토핑을 추가합니다" 정보를 가져옵니다.
답변: "팥을 준비하고, 얼음을 갈아 얹고, 연유와 다양한 토핑을 추가합니다.
Crucially, by using pre-trained access mechanisms, the ability to access knowledge is present without additional training.
특히 RAG 모델에서 리트리버와 생성기를 사전 학습된 상태로 사용하기 때문에 별도의 추가 학습 과정 없이도 외부 지식을 효과적으로 사용할 수 있다는 것을 강조하고 있습니다. 보통 RAG를 실현할 때 langchain같은 라이브러리에서 사전 학습된 리트리버와 생성기를 간단하게 가져다 쓰기만 하면 되는 것처럼, 무척 편리한 기능 구현이 가능한 것이 바로 RAG의 핵심이기도 하죠.
Finally, we demonstrate that the non-parametric memory can be replaced to update the models’ knowledge as the world changes.
non-parametric memory의 경우에는 업데이트가 가능하기 때문에 유지보수를 통해 최신 정보를 반영하고 정확도를 개선할 수가 있겠습니다.
2 Methods
We explore RAG models, which use the input sequence x to retrieve text documents z and use them as additional context when generating the target sequence y.
RAG 모델은 입력 시퀀스 x를 사용하여 텍스트 문서 z를 검색하고, 이를 추가 컨텍스트로 활용하여 목표 시퀀스 y를 생성합니다.
Figure 1.
Query Encoder (q(x)): 입력된 질문(query)을 벡터 형태로 인코딩합니다.
Retriever (Non-Parametric Memory): 인코딩된 질문을 기반으로 최대 내적 탐색(MIPS)을 사용하여 top-K 문서들을 찾습니다. (주어진 질문 x에 대해 상위 K개의 텍스트 구절 분포를 반환)
Document Index (d(z)): 검색된 문서들의 벡터 인덱스입니다.
Generator (Parametric Memory): 선택된 문서들(z)을 입력으로 받아 최종 출력을 생성합니다. 본 논문의 경우 seq2seq 모델(BART)을 채택하고 있습니다.
Marginalize: 여러 문서들로부터 얻은 출력을 종합하여 최종 답변(y)을 도출합니다. 다양한 문서에 대해 seq2seq 예측을 주변화(marginalize)합니다.
이처럼 RAG 모델은 질문을 인코딩하여 관련 문서를 검색하고, 이를 바탕으로 답변을 생성합니다. 그렇다면 RAG는 retriever와 generator를 어떻게 학습시켰을까요?
To train the retriever and generator end-to-end, we treat the retrieved document as a latent variable. We propose two models that marginalize over the latent documents in different ways to produce a distribution over generated text. In one approach, RAG-Sequence, the model uses the same document to predict each target token. The second approach, RAG-Token, can predict each target token based on a different document.
RAG는 retrieved된 document를 latent variable로 취급한다고 명시하고 있습니다. 본 논문에서는 이와 같은 latent document에 대해 다른 방식으로 marginalization하는 두 가지 모델을 제안합니다.
RAG-Sequence 모델 : Same document를 사용하여 each target token을 예측
RAG-Token 모델 : Different document를 사용하여 each target token을 예측
RAG-Sequence 모델
하나의 문서 z에 대해 전체 시퀀스 y의 모든 토큰 yi에 대한 확률을 계산합니다. 모든 top-K 문서에 대해 이 과정을 반복한 후, 최종 값을 주변화(marginalize)하여 계산합니다. 즉, 각 문서에 대해 시퀀스 전체를 고려하여 최종 출력을 생성합니다.
RAG-Token 모델
RAG-Token model은 RAG-Sequence와 다르게 각 토큰 yi를 생성할 때마다 모든 top-K 문서에 대해 확률을 계산하고, 그 후 주변화(marginalize)하여 최종 출력을 생성합니다. 즉, 각 토큰에 대해 개별 문서를 고려하여 출력을 생성합니다.
Retriever: DPR
앞서 언급한 바와 같이 RAG에서는 retriever𝑝𝜂(𝑧|𝑥)로 DPR을 사용합니다. DPR은 기본적으로 bi-encoder 구조 - 사전 학습된 BERT 기반 인코더를 사용하여 리트리버를 초기화하고 문서 인덱스를 구축합니다.
https://arxiv.org/pdf/2004.04906
DPR은 논문 <Dense Passage Retrieval for Open-Domain Question Answering>에서 고안한 방법으로, RAG 논문보다 1년 앞서 출간되었습니다. 나중에 기회가 되면 DPR 논문도 리뷰해 보도록 하겠습니다.
Calculating top-k(pη(·|x)), the list of k documents z with highest prior probability pη(z|x), is a Maximum Inner Product Search (MIPS) problem, which can be approximately solved in sub-linear time [23]
주어진 질문 x에 대해 가장 높은 사전 확률 pη(z∣x)을 가진 상위 K개의 문서 목록을 계산하는 것은 최대 내적 탐색(MIPS) 문제로 해결합니다. 즉, input x 에 대한 document z의 분포는 위에서 산출한 d(z) 와 q(x)의 내적 연산을 통해 계산되며, 이 내적 값이 높은 순서대로 top-k document를 골라 retrieve를 하게 되는데, 이 과정은 REALM에서 사용되었던 MIPS 알고리즘을 사용하여 효율적인(sub-linear time) 탐색을 가능하게 했다고 합니다.
Generator: BART
생성기로는 무엇을 사용해도 상관이 없으며 본 논문에서는 BART-large를 사용했다고 밝히고 있습니다.
Training
We jointly train the retriever and generator components without any direct supervision on what document should be retrieved
DPR 기반의 리트리버와 BART-large 기반의 생성기는 학습 과정에서 동시에 학습됩니다. 이때, 어떤 문서가 검색되어야 하는지에 대한 직접적인 감독 없이 진행되는 비지도 학습(unsupervised learning) 방식이 적용됩니다. 오로지 출력 시퀀스에 대한 NLL(Negative marginal Log-Likelihood)을 최소화하는 방향으로 학습되며, 리트리버 또한 이 과정에서 NLL을 최소화하는 방향으로 학습됩니다.
Decoding
앞서 살펴본 두 가지 모델 RAG-Sequence와 RAG-Token은 각각 output 산출 방법이 다르므로 token decoding 하는 과정도 달라지게 됩니다.
RAG-Token 모델 : 표준 시퀀스-투-시퀀스 생성기처럼 작동하며, 여러 문서의 확률을 합산하여 전이 확률을 계산합니다. 이를 표준 빔 디코더에 적용하여 디코딩합니다.
RAG-Sequence 모델 : 각 문서에 대해 별도의 빔 서치를 실행하고, 최종 확률을 추정하기 위해 추가적인 forward pass를 실행합니다. 이를 "Thorough Decoding"이라 하며, 효율성을 위해 추가 패스를 생략하는 "Fast Decoding"도 있습니다.
이 때, 빔 서치는 가장 가능성 높은 N개의 후보를 유지하며 다음 토큰을 생성, 이 과정을 반복해 최종 출력 시퀀스를 생성하는 디코딩 방식을 의미합니다.
출처 : https://slideplayer.com/slide/14552918/
Experiment & Result
해당 부분은 GPT4.0-Turbo를 이용하여 핵심 내용 정리 요약 후 패스하도록 하겠습니다.
Dense Passage Retriever (DPR): DPR은 dense encoding을 통해 질문과 패시지 간의 의미적 관계를 잘 파악합니다.
성능 비교: BM25와 비교한 실험에서 대부분의 데이터셋에서 DPR이 더 우수한 성능을 보였습니다.
효율성: 적은 수의 학습 예제로도 고품질의 dense retriever를 학습할 수 있습니다.
일반화 성능: 학습된 데이터셋 외에도 어느 정도 잘 작동하며, BM25보다 우월한 성능을 보입니다.
질적 분석: BM25는 키워드에 민감하고, DPR은 의미적 관계를 잘 파악합니다.
종합 성능: 대부분의 데이터셋에서 DPR이 최상의 성능을 냈습니다.
RAG의 가장 큰 장점은 parametric & non-parametric memory의 결합을 통해 보다 정확하고 다양한 정보를 생성할 수 있다는 점입니다. 이를 통해 기존의 파라미터를 대량 업데이트하거나 fine-tuning 하지 않으면서도 domain-specific한 downstream task을 잘 수행할 수 있는 모델을 구현할 수 있게 되었습니다. 특히 검색 인덱스를 간단히 교체하여 모델을 업데이트할 수 있다는 점에서 매우 효율적이고 유용한 기법이라고 할 수 있겠습니다.
본 논문을 읽기 전에 langchain을 이용하여 RAG을 이미 구현해 본 입장에서, 논문을 통해 핵심 아이디어와 학습 방안에 대해 구체화하고 더 깊이 이해할 수 있어 무척 좋은 기회였습니다. 앞으로 RAG를 다양한 응용 분야에 적용해보고, task에 따라 어떤 방식으로 알맞게 사용할 수 있는지 실험해 보는 과정을 거쳐 보고자 합니다.
Peft는 Parameter-Efficient Fine Tuning의 약자로, 말 그대로 파인튜닝을 조금 더 효율적으로 할 수 있는 방법론을 의미합니다. Peft를 실현할 수 있는 종류에는 다양한 것들이 있는데, 가장 대표적으로 사용되는 방법 중 하나로는 LoRA(로라)가 있습니다.
본 포스팅에서는 LoRA의 논문 핵심 파트를 가볍게 리뷰하고, peft와 unsloth, trl 라이브러리를 이용해서 로라방식의 LLM 파인튜닝을 직접 코드로 진행해 보겠습니다.
논문
출처 : https://arxiv.org/pdf/2106.09685
LoRA는 2021년 발표된 마이크로소프트의 논문 [LoRA: Low-Rank Adaptation of Large Language Models]에서 제안한 효율적인 파인튜닝 방법입니다. 다양한 거대 모델에 적용할 수 있고, 논문에서는 언어 모델을 중심으로 설명을 합니다.
Abstract
논문의 초록에서는 다음과 같이 로라의 핵심을 짚어서 말해주고 있어요.
We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
pretrained된 모델의 weight를 freeze한다.
학습 가능한 rank-decomposition, 즉 '분해된' 행렬을 트랜스포머 구조의 각 레이어마다 하나씩 주입한다.
이를 통해 downstream 태스크를 위해 파인튜닝할 때 트레이닝할 파라미터의 수를 획기적으로 줄일 수 있다.
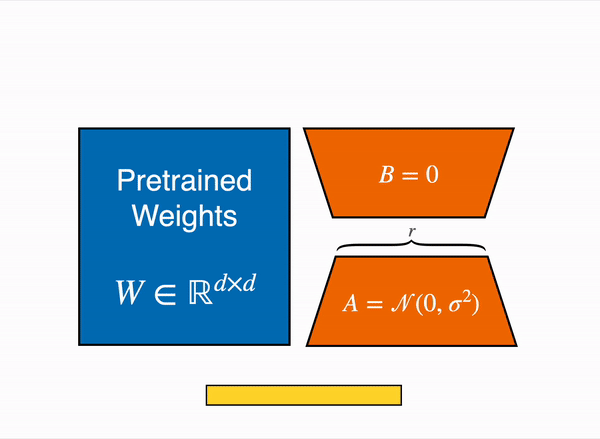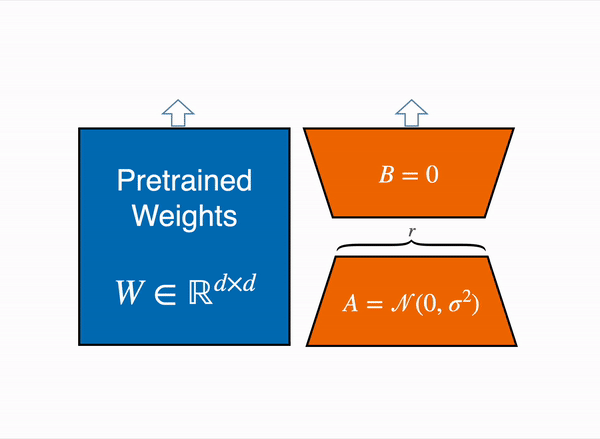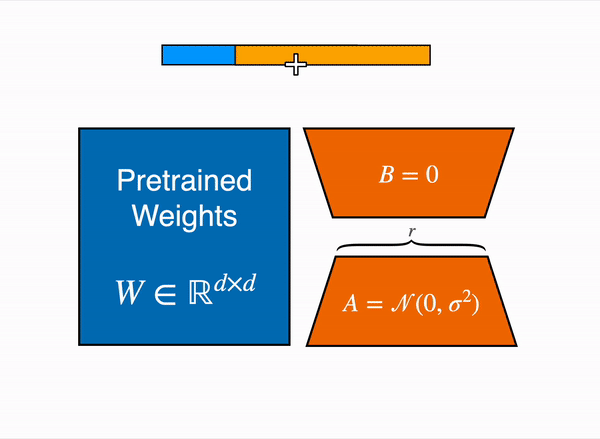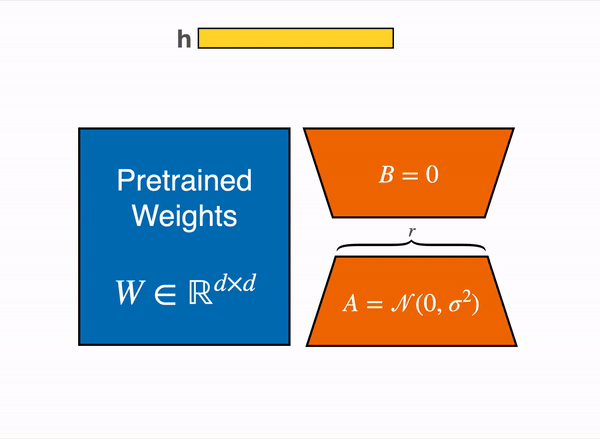
Figure 1의 그림은 다들 많이 보셨을 것이라고 생각합니다. 파란색의 Pretrained Weights는 기존의 사전학습된 모델이 가지고 있던 웨이트맵을 의미하고, LoRA는 이는 수정할 수 없도록 freeze시킵니다. 대신 벡터 내적을 수행했을 때 W와 크기가 같아지는 주황색 A, B 행렬을 만들어서 트랜스포머 레이어 사이사이에 inject - 꽂아 넞어주고, 그 A, B 행렬을 트레이닝 시킵니다.
We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”, leading to our proposed Low-Rank Adaptation (LoRA) approach. LoRA allows us to train some dense layers in a neural network indirectly by optimizing rank decomposition matrices of the dense layers’ change during adaptation instead, while keeping the pre-trained weights frozen, as shown in Figure 1.
LoRA는 기존의 웨이트맵 행렬을 분해(rank decomposition)시켜서 기존의 freeze된 웨이트맵에 더해주는 방식으로 간접적으로 업데이트 합니다. 예를 들어서 W의 크기가 (10, 10)이고 분해된 행렬 A, B의 크기는 각각 (10, 2)와 (2, 10)이라고 해 봅시다.
W의 파라미터 수는 10*10 = 100(개) 입니다.
A와 B의 파라미터 수는 각각 20개씩으로 총합 40개입니다.
LoRA를 사용하면 기존의 100개 파라미터는 freeze시키고, 대신 분해된 행렬(A, B)의 40개 파라미터만 트레이닝하면 됩니다. A, B를 행렬곱하면 (10, 10) 사이즈가 되므로 기존의 웨이트맵에 더해줄 수 있습니다. 따라서 학습시켜야 할 파라미터의 수가 full-finetuning에 비해서 줄어들게 되고, 리소스를 효율적으로 활용할 수 있습니다.
1. Introduction
논문의 서론(Introduction)에서는 아래와 같이 로라의 핵심 장점을 요약해서 말하고 있습니다.
사전 학습된 모델의 파라미터는 동결시키고, 필요한 task에 따라 A와 B만 학습시키면 되기 때문에, 사전학습된 거대 모델을 다양한 downstream에 더 잘 활용할 수 있습니다.
LoRA를 사용하면 inject한 low-rank matrices만 최적화시키면 되기 때문에 학습이 매우 효율적이고, 진입에 대한 하드웨어 장벽을 최대 3배까지 낮춰 준다고 합니다.
기존의 fully fine-tuning과 비교했을 때 inference latency(input이 들어가서 모델이 예측을 하기까지 걸리는 시간)이 없는 장점이 있습니다 - 따라서 아주 간단한 선형 구조만으로 freeze된 기존의 웨이트와 새롭게 학습시킨 웨이트를 병합할 수 있습니다.
LoRA는 prefix 기반 접근과 함께 사용될 수 있습니다.
2. Problem Statement
논문의 2장 PROBLEM STATEMENT에서는 수식과 함께 자세한 설명을 합니다.
(1) 기존의 최대우도법 목적함수
로라 기법을 적용하지 않은 full fine-tuning에서는 pre-trained된 웨이트맵을 불러와서 목적함수를 업데이트하는 최대우도법(1)을 사용합니다. 즉, 최대우도법을 이용해 모델의 전체 파라미터 Φ 를 업데이트합니다. 저자들은 이렇게 모든 파라미터를 업데이트하는 방식보다 효율적인 LoRA를 제시하는데요. LoRA를 이용해 일부분의 파라미터만 업데이트하는 목적식은 다음과 같습니다.
(2) LoRA 목적함수
기존의 model 파라미터인Φ를 이용해 forward를 진행하고 얻어지는ΔΦ(기울기)를 이용해 backpropagation을 진행할 때, LoRA의 파라미터Θ를 이용합니다. 논문에 따르면 LoRA로 업데이트하는 파라미터 Θ 의 크기인 | Θ | 가 기존의 full fine-tuning으로 업데이트하는 파라미터 Φ 의 크기인 | Φ | 의 0.01%라고 합니다. 그만큼 훨씬 효율적으로 튜닝이 가능하며, 각 downstream task마다 다른 LoRA layer를 사용할 수 있기 때문에 목적에 맞는 파인튜닝된 모델을 효율적으로 생산할 수 있는 것입니다.
허깅페이스 & LoRA
저는 논문 뿐만 아니라 라이브러리 docs 보는 것도 아주 좋아하기 때문에 - 보기 좋게 정리가 잘 되어 있어서 특히 허깅페이스 좋아합니다 - 로라와 관련된 허깅페이스 문서들을 조금 더 살펴보도록 하겠습니다.
허깅페이스의 Diffuser Docs에서는 LoRA를 a popular and lightweight training technique that significantly reduces the number of trainable parameters라고 설명하고 있습니다. 또한 논문에서 미리 살펴본 바와 같이 It works by inserting a smaller number of new weights into the model and only these are trained - 적은 수의 새로운 웨이트맵을 Insert하고, 딱 그것들만 학습시킨다는 점을 짚어주고 있습니다.
로라는 가장 처음에 언어 모델에 고안되었지만, 그 확장성과 용이성으로 인해 많은 Diffusion 모델에 사용되고 있다고 합니다. 실제로 저도 Stable Diffusion을 파인튜닝하여 text-to-image 모델을 구현하는 데 로라 기법을 사용한 경험이 있습니다.
허깅페이스의 PEFT docs 페이지의 'Adapters'에서도 LoRA에 관해 이야기하고 있습니다. 위 애니메이션은 우리가 논문에서 살펴보았던 LoRA의 행렬 분해 방식을 잘 보여주고 있습니다.
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. However, for simplicity and further parameter efficiency, LoRA is typically only applied to the attention blocks in Transformer models. The resulting number of trainable parameters in a LoRA model depends on the size of the update matrices, which is determined mainly by the rank r and the shape of the original weight matrix.
이론적으로 LoRA는 neural-network 구조를 가지는 모델의 어떤 부분에든지 적용될 수 있지만, 간소화와 파라미터 효율성을 고려하여 보통 트랜스포머 구조의 attention layer에 적용되는 것이 일반적이라고 합니다. 나중에 코드에서 다시 살펴보겠지만, 분해된 행렬의 사이즈를 정의하는 하이퍼 파라미터로는 rank r이 있습니다. Figure 1 이미지의 주황색 부분에 잘 보면 r이라고 써있습니다 :)
r의 값이 작을수록 계산은 쉽고 빠르겠지만 downstream task에 따른 디테일한 학습이 어려울 수 있고, r의 값이 클수록 디테일한 파라미터 업데이트가 가능하지만 그만큼 분해 행렬의 파라미터 수도 많아지므로 계산량이 늘어납니다. 따라서 주어진 Task에 따라 적절한 r값을 찾아내고 설정하는 것이 모델러의 중요한 임무중 하나라고 할 수 있겠습니다.
unsloth
huggingface 공식 peft docs 페이지, unsloth 공식 깃허브, 허깅페이스 블로그 글 - 총 3가지 레퍼런스를 참고하여 최신 LLaMA 3.1-8B 모델을 직접 LoRA 방식으로 파인튜닝 해보도록 하겠습니다.
Unsloth는 대형 언어 모델(LLM)들의 파인튜닝과 훈련을 가속화하고 메모리 사용을 최적화하기 위한 오픈 소스 라이브러리입니다. 특히 Llama, Mistral, Phi, Gemma 등의 LLM 모델들을 2-5배 빠르게 훈련시키고 메모리 사용량을 최대 80%까지 줄일 수 있습니다. 실제로 사용해본 결과, 지인짜 빠르고 편리합니다. 강추...
위 공식 깃허브에서 Finetune for Free 아래의 Llama 3.1 (8B) Free Notebooks 코드를 클릭하면 Colab 코드가 실행됩니다. 저는 코랩 코드를 참고하여 로컬 On-Premise GPU에서 진행하였습니다. 저처럼 로컬에서 진행하시는 경우 공식 깃허브를 참고하여 unsloth 라이브러리를 사용하기 위한 환경설정과 다운로드를 완료한 뒤에 코드를 실행하시기 바랍니다.
LoraConfig
먼저 간단하게 peft 라이브러리에서 설정할 수 있는 LoRA Configuration 하이퍼파라미터 3가지만 짚고 넘어가 보겠습니다.
r(int) — Lora attention dimension (the “rank”)
위에서 살펴본 r - rank decomposition의 r값을 설정, r이 클수록 분해 행렬의 사이즈가 커집니다.
예를 들어, 만약 원래의 파라미터 행렬이 m×n 크기라면, Am×r, B는 r×n 크기가 됩니다.
lora_alpha(int) — The alpha parameter for Lora scaling
lora_alpha는 직접적으로 로라 페이퍼 원문에서 언급된 적은 없지만 중요한 역할을 하는 하이퍼파라미터입니다. lora_alpha 파라미터는 low-rank decomposition 행렬이 기존의 고정된(weight-frozen) 모델 파라미터에 합쳐질 때, 그 비율을 결정합니다. 즉, 분해된 저차원 행렬의 영향을 원래 모델에 얼마나 반영할지를 조절하는 것이 바로 lora_alpha 파라미터입니다.
참고한 허깅페이스 블로그에서는 the strength of the applied LoRA라고 설명하고 있습니다.
lora_dropout(float) — The dropout probability for Lora layers.
unsloth 라이브러리의 FastLanguageModel 클래스를 이용하여 라마3.1-8B모델을 불러올텐데요.
load_in_4bit = False # 4비트로 양자화된 모델을 불러올 경우 True로 설정 -> 조금 더 빨라짐
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit
)
저는 load_in_4bit을 False로 설정하고 양자화되지 않은 기본 라마3.1-8B을 불러왔습니다. 코랩 T4 등의 작은 GPU로 실행하시는 경우 이 값을 True로 설정하셔서 가볍게 돌리시는 것을 추천합니다.
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 1004,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
위에서 살펴본 LoRA 관련 하이퍼파라미터들이 보입니다.
새로운 하이퍼파라미터로 use_rslora가 있는데요. RsLoRA는 LoRA 방식의 변형으로, 랭크를 안정화시키는 기법을 통해 효과적으로 파인튜닝을 할 수 있는 방법이라고 합니다. RsLoRA는 학습 과정 중에 랭크를 동적으로 조절하여 최적화하는데, 고정된 랭크를 사용하는 기존 LoRA 방식에 비해 더 나은 성능을 도출할 수 있다고 하네요. 저는 우선 False로 설정했고, 나중에 True로 변환하여 성능을 비교해보고자 하였습니다. 또한 코랩과 같은 제한된 환경에서 실행하는 경우에도 False로 설정하는것이 낫겠습니다.
또한 loftq_config의 경우 모델의 백본 가중치를 양자화하고 LoRA 계층을 초기화하는 방법을 정의한다고 합니다. 저는 모델을 로드할 때 load_in_4bit을 False로 두어 양자화되지 않은 기본 모델을 로드했으며, loftq_config 역시 None으로 설정하여 모델의 백본 가중치를 양자화하지 않는 것으로 설정하였습니다.
from datasets import load_dataset
dataset = load_dataset("ruslanmv/ai-medical-chatbot", split = "train")
prompt = """You are a professional medical doctor. Based on the below context, generate answer for the question.
### Description:
{}
### Patient:
{}
### Doctor:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["Description"]
inputs = examples["Patient"]
outputs = examples["Doctor"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
dataset = dataset.train_test_split(test_size=0.01)
dataset_train = dataset['train']
dataset_test = dataset['test']
dataset_train = dataset_train.map(formatting_prompts_func, batched = True,)
dataset_test = dataset_test.map(formatting_prompts_func, batched = True,)
저는 허깅페이스에서 medical chatbot QA task용으로 준비된 데이터셋을 사용해서 위와같이 전처리과정을 거쳤습니다. train 데이터는 총 254,346개이며 test 데이터는 총 2,570개가 있습니다.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset_train,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
num_train_epochs = 1,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 1004,
output_dir = "outputs",
),
)
다음으로 trl 라이브러리의 SFTTrainer 클래스를 사용해서 superfised fine tuning(SFT)을 진행합니다.
per_device_train_batch_size: 각 디바이스(예: GPU)당 훈련에 사용할 배치 크기- 모델이 한 번의 훈련 스텝에서 처리할 데이터 샘플의 수를 의미. 크기가 클수록 더 많은 메모리가 필요하며, 일반적으로 크기가 클수록 더 나은 일반화 성능을 제공함.
gradient_accumulation_steps: 그래디언트 누적 단계의 수
warmup_steps: 학습률이 선형적으로 증가하는 워밍업 스텝 수 - 모델이 학습 초반에 너무 큰 학습률로 인해 불안정해지는 것을 방지하는 역할. 초기에는 낮은 학습률로 시작하여 점진적으로 증가시키도록 함.
is_bfloat16_supported()
is_bfloat16_supported() : Unsloth 라이브러리에서 제공하는 함수 - 현재 사용 중인 하드웨어가 bfloat16(Brain Floating Point 16) 정밀도를 지원하는지 여부를 확인하는 역할
bfloat16이 지원되는 경우, 이를 사용하여 메모리 사용량을 줄이고 훈련 속도를 높이는 것이 가능 (지원되지 않는 경우, fp16 또는 fp32를 사용)
fp16과 bf16은 상호 배타적인 설정으로 동시에 사용할 수 없음
logging_steps : 로그를 기록할 스텝 간격
optim : 사용할 옵티마이저의 종류 ("adamw_8bit"는 AdamW 옵티마이저를 8비트 정밀도로 사용하여 메모리 효율성을 높이고 계산 비용을 줄임)
weight_decay : 가중치 감쇠(L2 정규화) 계수 (모델의 복잡성을 줄이고 과적합을 방지하기 위해 가중치 값을 점진적으로 감소시키는 역할)
def inference_i(i):
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
question = dataset_test[i]['Description']
inputs = tokenizer(
[
prompt.format(
"Answer the question truthfully, you are a medical professional.", # instruction
question, # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 1024, use_cache = True)
tokenizer.batch_decode(outputs)
predict = tokenizer.batch_decode(outputs)[0].split("###")[-1]
truth = dataset_test[i]['Doctor']
print("-----------------------")
print(f"question : {question}")
print("-----------------------")
print(f"inference : {predict}")
print("-----------------------")
print(f"label answer : {truth}")
print("-----------------------")
return question, predict, truth
위와 같이 dataset_test의 i번째 데이터에 대해 inference를 수행할 수 있는 함수를 직접 작성했구요.
question, predict, truth = inference_i(0)
요런식으로 실행하면 question, inference 결과, 기존의 label answer값을 확인할 수 있습니다.
question : High BP, have consistent cough with chest pain, traces of blood in phlegm. Normal chest x-ray, on BP medicines.Cause?
[데이터셋의 답변 예시] label answer : Hello there, In addition to the possibilities of asthma, chest infection which have been ruled out by X Ray etc, another possibility is GERD(gastro esophageal reflux disease/gastritis). You might need to take a course of pantoprazole/omeprazole , if that is the case. It is possible that the stress(you said you were worried about your brother's son) could have caused GERD/gastritis.
1. I would advise you to have frequent small meals. 2. Avoid spicy,deep fried,fatty food and carbonated beverages. 3.Do relaxation exercises/meditation. 4. Avoid sleeping/lying down immediately after a meal. Wait for 2 hours before lying down after a meal. 5.Avoid smoking/alcohol. Hope this helps.
Please let me know if you need any further advise. Regards, Dr.Divya Kuttikrishnan
위와 같은 질문을 던졌을 때, 파인튜닝한 llama3.1-8B모델은 아래와 같이 답변했습니다.
Hello, Thanks for writing to us. Chest pain with cough is very serious and needs to be investigated. Chest X-ray is a very basic investigation and needs to be followed by a CT scan of the chest. CT scan is a very important investigation and will help in identifying the cause of the chest pain. If the CT scan is normal, then you need to get an ECG and echocardiogram done. These will help in identifying the cause of the chest pain. I hope this helps. Take care. Regards, Dr. Rakesh Kumar, General & Family Physician
데이터셋의 예시 답변과 비교하면 풍부함이 조금 떨어지긴 하나, medical QA로서의 의무는 어느정도 수행하고 있다고 평가할 수 있을 것 같습니다. 그렇다면 파인튜닝을 하나도 거치지 않은 기본 llama3.1-8B모델은 같은 질문에 대해서 어떻게 대답할까요?
ollama를 통해 터미널로 QA를 실행해본 모습
medical QA datset으로 파인튜닝한 모델에 비하면 기본 모델은 medical QA보다는 LLM스러운 조금 더 일반적이고 풍부한 대답을 보여주는 것 같습니다. 솔직히 파인튜닝 안한게 더 나아보입니다. 인삿말이나 마무리말 정도는 프롬프팅으로도 충분히 구현할 수 있으니까요. 파인튜닝이 반드시 성공적으로 끝나는 것은 아니다-라는 좋은 예시가 되겠습니다...(ㅋㅋㅋㅋ)
파인튜닝을 통해 기본 백본 모델보다 나은 결과를 도출하기 위해서는 하이퍼파라미터 튜닝과 최적화 과정을 거쳐야 할 것으로 생각되구요. 또 제가 의학 전문가가 아니다보니 퀄리티 측면에서 무엇이 더 낫다고 평하기 조금 애매한 부분이 있어서, 실제 프로젝트에서는 도메인 관련한 전문가와의 협업이 필수적으로 요구될 것으로 생각됩니다.
파인튜닝을 통해 downstream task에 적용할 수 있는 더 나은 모델을 만드는 과정은 제가 지금 구축하고 있는 실제 LLM 프로젝트에서 조금더 고민해보는것으로 하고, 본 포스팅은 이정도로 마무리를 하겠습니다 :-) 본 포스팅을 통해 LoRA, Peft, Unsloth를 통한 효율적인 파라미터 튜닝 방법에 대해 고찰해볼 수 있는 좋은 기회였습니다.
추출한 내용을 langchain을 이용해서 split, 임베딩하여 벡터화한 다음 Chroma 벡터 저장소에 저장합니다.
벡터 저장소에서 질문에 해당하는 내용을 검색하여 context로 준비합니다.
Ollama라이브러리를 이용해서LLaMA3 모델에게 질문과 context를 프롬프트로 제공하고 답변을 받습니다.
모든 과정을 gradio와 연동하여 GUI로 실행할 수 있도록 설정했습니다.
1. 환경설정 및 라이브러리 준비
먼저 새로운 콘다 환경을 만들고 해당 환경 안에서 프로젝트를 진행하도록 하겠습니다.
conda create -n ragchatbot python=3.11 -y # 환경 생성
conda activate ragchatbot # 활성화
필요한 라이브러리를 설치 후 임포트합니다.
# 설치 (터미널에서 실행)
pip install pdfplumber pytesseract ollama gradio langchain
# 임포트
import gradio as gr
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollama
import pdfplumber
import pytesseract
from PIL import Image
2. 텍스트 추출, 임베딩, chroma에 저장
텍스트 추출, 임베딩, 벡터 데이터베이스 저장에 필요한 2가지 함수를 작성하겠습니다.
# PDF page에서 텍스트 추출하는 함수 작성
def extract_text_with_ocr(page):
text = page.extract_text()
if not text: # 만약 추출할 텍스트가 없다면
# PDF page를 이미지로 변환
image = page.to_image()
# 이미지에서 OCR 재실행하여 텍스트 추출
text = pytesseract.image_to_string(image)
return text
# PDF 파일을 열어서 extract_text_with_ocr 함수 실행 -> 벡터 데이터베이스에 저장하는 함수 작성
def load_and_retrieve_docs(file):
text = ""
try:
with pdfplumber.open(file) as pdf:
for page in pdf.pages:
page_text = extract_text_with_ocr(page)
# 페이지에서 추출한 텍스트가 있을 때마다 text에 누적해서 저장
if page_text:
text += page_text
except Exception as e:
return f"Error reading PDF file: {e}"
# 만약 추출한 텍스트가 하나도 없는 경우 아래와 같은 메세지 출력하고 함수 종료
if not text:
return "No text found in the PDF file."
# 추출한 텍스트가 있는 경우
docs = [Document(page_content=text)]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
return vectorstore.as_retriever()
extract_text_with_ocr
본 함수는 pdf 개별 페이지를 Input으로 받아서 페이지 내의 텍스트를 추출, 반환하는 함수입니다.
텍스트 추출에는 pdfplumber 라이브러리의 extract_text() 함수를 사용했습니다. 만약 페이지 내에서 추출할 텍스트가 없는 경우 pdfplumber 라이브러리의 to_image() 함수를 사용해서 pdf파일을 pdfplumber가 핸들할 수 있는 PageImageobject객체화(이미지화)합니다. 이후 해당 이미지에서 pytesseract의 image_to_string() 함수를 사용해서 이미지로부터 텍스트를 추출하도록 했습니다.
완성된 text를 langchain의 Document 객체로 만든 다음, RecursiveCharacterTextSplitter 객체를 생성한 뒤 만들어 둔 Document 객체를 집어넣어 적당히 청킹을 해주었습니다. 이후청킹이 완료된 텍스트들을 벡터화하기 위한 OllamaEmbeddings 객체를 생성해 주었습니다.
langchain에 연동된 Chroma 라이브러리를 불러온 다음, from_documents() 함수를 이용해 Chroma에 load를 해 줍니다. 이 때, 저장할 텍스트 청킹 객체와 임베딩 객체를 지정해 주어 무엇을 어떻게 임베딩하여 저장할지를 지정해주면 자동으로 임베딩을 실행하면서 vectorstore에 저장을 완료하기 때문에 사용이 매우 간편합니다.
마지막으로 load_and_retrieve_docs 함수는 결과값으로 vectorstore에 as_retriever() 함수를 적용한 객체를 반환합니다.
참고로 docs에 따르면 llama3 기본 모델보다chatqa 모델이 대화형 QA와 RAG 기능을 훨씬 잘 수행한다 - excels at conversational question answering (QA) and retrieval-augmented generation (RAG) - 라고 기재가 되어 있어서 처음에는 LLaMA3-chatqa모델을 선택하였는데, 실험 결과 LLaMA3-chatqa보다 기본 LLaMA3 모델이 더 답변이 정상적으로 생성되는 것을 확인할 수 있었습니다. 그 이유에 대해서는 좀더 살펴봐야 할 것 같아요.
# 리스트 안의 모든 document 객체 내용을 추출해서 string으로 이어붙여 반환
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Function that defines the RAG chain
def rag_chain(file, question):
retriever = load_and_retrieve_docs(file)
if isinstance(retriever, str): # 리턴받은 값이 string인 경우 에러를 의미하므로 함수 중단
return retriever
retrieved_docs = retriever.get_relevant_documents(question) # Use get_relevant_documents method
formatted_context = format_docs(retrieved_docs)
formatted_prompt = f"Question: {question}\n\nContext: {formatted_context}"
response = ollama.chat(model='llama3',
messages=[
{"role": "system",
"content": "You are a helpful assistant. Check the pdf content and answer the question."
},
{"role": "user", "content": formatted_prompt}])
return response['message']['content']
rag_chain
위에서 작성했던 load_and_retrieve_docs 함수는 pdf 내용을 저장해 둔 vectorstore에 as_retriever() 함수를 적용한 객체를 반환합니다. 먼저 이 객체에 retriever라는 이름을 할당한 다음, 만약 retriever의 객체 타입이 string인 경우 에러 메세지(추출한 텍스트 없을 때)가 리턴된 것을 의미하므로 해당 에러를 프린트하면서 함수를 종료합니다.
docs에 따르면 get_relevant_documents() 함수는 주어진 쿼리(질문)에 가장 관련성이 높은 문서를 벡터 저장소에서 검색하는 기능을 합니다. 예를 들어 제가 lloco_paper.pdf 파일로 테스트를 했을 때, RecursiveCharacterTextSplitters를 이용해서 split한 document 객체는 총 55개였고, 그 중에서 검색을 통해 반환하는 document 객체는 항상 4개인 것으로 확인이 되었습니다. 이 수치를 변경할 수 있는지는 나중에 확인을 해 보도록 하겠습니다.
반환받은 document 객체 리스트인 retrieved_docs를 format_docs 함수를 이용해서 하나의 string으로 변환하고, 해당 string은 prompt의 context로 주어지게 됩니다.
ollama 라이브러리의 chat() 함수를 이용해서 LLaMA 3 모델에 question과 context를 제공하고, 답변(response)을 받습니다. chat
만약 답변을 한국어로 받고 싶은 경우 messages의 context 안에 Generate your answer in Korean 등과 같이 한국어로 답변을 내놓으라는 한 문장을 추가해서 프롬프팅을 해 주시면 됩니다.
4. Gradio GUI 인터페이스 할당
# Gradio interface
iface = gr.Interface(
fn=rag_chain,
inputs=["file", "text"],
outputs="text",
title="[LLAMA 3] RAG 검색 활용 챗봇 시스템",
description="PDF파일을 업로드하고 질문을 입력하면 답변을 생성해 드립니다. (영어로!)"
)
# app 실행
iface.launch()
주피터 파일로 실행하는 경우 바로 인터페이스가 보이실 것이고, 만약 .py파일로 실행하신다면 아래와 같이 할당되는 로컬 URL 주소로 접속을 하시면 인터페이스를 확인하실 수 있습니다.
본 논문 리뷰는 BERT 원문을 직접 읽고 버트의 핵심 아이디어와 구조에 대해서 살펴봅니다. 구체적인 실험과 학습 결과, 성능 지표 등에 대한 리뷰는 생략하는 점 양해 바랍니다.
초록 Abstract
트랜스포머의 인코더는 Recurrent(순차) 구조 없이 입력을 '통으로' 받습니다. 따라서 입력 시퀀스의 각 위치에서 왼쪽, 오른쪽 양방향(Bidirectional) 문맥을 모두 고려할 수 있습니다.
이와 반대로 디코더는 마스킹을 통해 현재 시점까지의 토큰들만을 참조하는 단방향(unidirectional)으로 작동합니다.
BERT는 Bidirectional Encoder Representations from Transformers의 약자로, 이름에서도 알 수 있듯트랜스포머의 '인코더'에만 집중한 모델입니다. 따라서 양방향(Bidirectional) 문맥을 고려하여 언어를 잘 이해하도록 학습(pre-train)이 되었습니다.
이 때 BERT의 R(Representation)은 무슨 의미일까요? NLP 태스크에서 자주 언급되는 Word Representation은 인간의 언어를 다차원 벡터로 표현하여 컴퓨터가 이해할 수 있게 하는 작업이나 그 결과물을 의미합니다. BERT의 R(Representation) 역시 입력된 단어나 문장의 의미를 벡터 형태로 표현하여 모델이 해당 언어의 문맥과 의미를 이해할 수 있도록 하는 작업을 포함합니다. 본 포스팅에서는 따로 '표현'이라는 한국어로 직역하지 않고 그대로 reperesentation으로 표기할 것임을 미리 밝히겠습니다.
BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inferences, without substantial task-specific modifications.
초록에서는 BERT가 모든 레이어에서 deep한 bidirectional representations을 학습하기 위해 고안되었으며, 사전 학습이 완료된 BERT 모델에 딱 1개의 output layer만 추가해서 파인튜닝이 가능할 정도로 '파인튜닝이 쉽고 용이하다'고 강조하고 있습니다. 이를 통해 QA(Question-Answering)이나 Langue Inferences과 같은 다양한 작업을 수행할 수 있는 것이죠 :-)
1 서론 Introduction
There are two existing strategies for applying pre-trained language representations to downstream tasks: feature-based and fine-tuning. .... (중략) they use unidirectional language models to learn general language representations. We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches.
사전 학습된 언어 representation을 다운스트림 작업에 적용하는 두 가지 기존 전략으로는 특징(feature-based) 기반 접근법과 파인튜닝 접근법이 있습니다.
딥러닝에서 다운스트림 태스크(downstream tasks)는 특히 사전 학습(pre-trained)된 모델에 Transfer Learning/Fine Tuning을 통해 수행하고자 하는 구체적인 하위 작업을 뜻합니다. 예를 들어, 자연어 처리 분야에서는 텍스트 분류, 감정 분석, 명명된 개체 인식(NER), 질문 응답(QA) 등이 다운스트림 작업에 해당할 수 있겠죠.
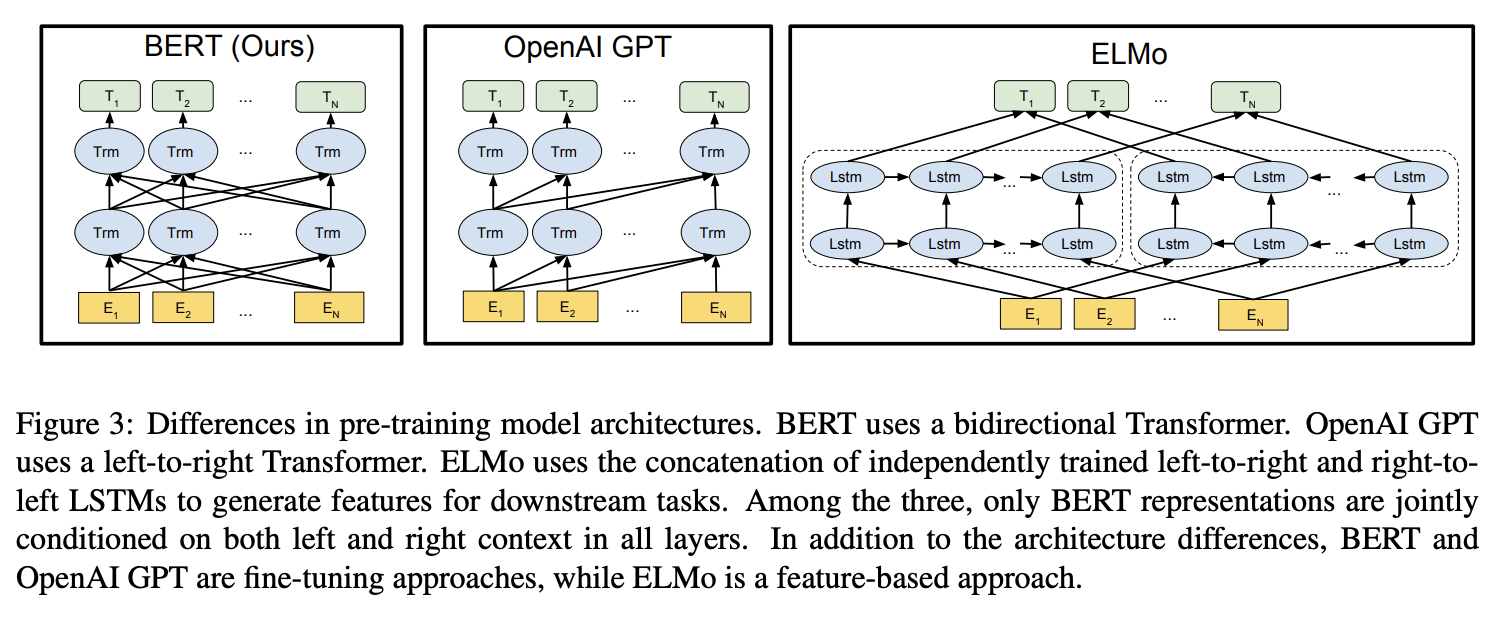
Feature-based 방법은 사전 학습된 언어 모델을 사용하여 텍스트 데이터를 처리한 후, 그 결과로 나온 특징(feature) 벡터를 다른 기계 학습 모델에 입력으로 사용하는 방법입니다. 따라서 전체 과정이 하나의 모델로 통합되어 한 번에 학습되고 예측되는 end-to-end 방식이라고 볼 수 없습니다. (대표적으로 ELMo)
Fine-tuning 방법은 사전 학습된 언어 모델을 특정 작업에 맞게 추가 학습시켜 사용하는 방식으로, 전체 과정을 하나의 모델로 통합하여 end-to-end 방식으로 학습과 예측을 수행합니다. (대표적으로 OpenAI GPT)
논문에서는 ELMo나 GPT같은 기존의 모델이 representation을 학습하기 위해 unidirectional - 단방향 언어모델을 사용하면서 사전 학습된 representation을 온전히 활용하지 못했고, 그래서 특히 파인튜닝 단계에서 문제가 많았다고 지적합니다.
부록 Figure 3.
The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training. For example, in OpenAI GPT, the authors use a left-to-right architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer (Vaswani et al., 2017). Such restrictions are sub-optimal for sentence-level tasks, and could be very harmful when applying fine-tuning based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions.
단방향 모델은 문맥의 일부만을 참조할 수 있습니다. 예를 들어, OpenAI GPT는 디코더 특화 모델로, 자신의 이전 토큰까지만 참조할 수 있는 좌->우 단방향 아키텍처를 사용하여 출력을 생성하는 특징이 있습니다.
예를 들어 GPT가 QA(Question-Answering) 작업을 수행한다고 해 봅시다. QA 작업에서는 질문(Q)을 받아 문서(Context)의 어느 부분이 정답에 해당하는지를 알아내야 하고, 이 과정에서 정답의 앞뒤 문맥이 모두 중요하게 고려되어야 합니다. 하지만 GPT는 문서를 왼쪽->오른쪽 단방향으로만 읽기 때문에, 정답의 뒷부분에 있는 중요한 정보를 참조하기 어렵습니다. 따라서 QA 작업을 위한 fine-tuning을 수행할 때 전체 문맥을 이해하는 데 어려움이 있을 것이고, 그만큼 정확한 답을 찾아내도록 fine-tuning이 어려울 수 있다는 것이죠.
대놓고 OpenAI 저격하는거 꿀잼...
In this paper, we improve the fine-tuning based approaches by proposing BERT: Bidirectional Encoder Representations from Transformers. (중략) The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-to-right language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer.
In addition to the masked language model, we also use a“next sentence prediction” taskthat jointly pre-trains text-pair representations.
본 논문은 BERT를 통해 파인튜닝 기반 접근법을 개선하는데, 대표적으로 "MLM(Masked Language Model)"을 도입합니다.
입력 토큰에서 무작위로 마스킹을 한 다음,
'양방향' 문맥을 고려하여 마스킹한 부분을 예측하도록 학습을 시킵니다.
deep한 스트럭처를 실현합니다.
또한 BERT는 MLM 외에도 텍스트 쌍 표현을 공동으로 사전 학습하는 "NSP(Next Sentence Prediction)"를 함께 사용합니다.
3 버트 BERT
BERT는 크게 pre-training과 fine-tuning의 2스텝으로 이루어져 있는데요.
During pre-training, the model is trained on unlabeled dataover different pre-training tasks.
For finetuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters.
우선 버트는 라벨이 따로 없는 데이터로 '비지도 학습'을 통해 사전 학습(pre-training)을 합니다.
다음 파인튜닝 단계에서는 라벨이 있는 데이터로 '지도 학습'을 하면서 사전에 학습한 파라미터 전체를 업데이트하게 됩니다. 나의 다운스트림 태스크가 무엇이냐에 따라서 사용하는 데이터도 다를거고, 당연히 그에 따라 업데이트 되는 파라미터 값도 달라지겠죠.
A distinctive feature of BERT is its unified architecture across different tasks. There is minimal difference between the pre-trained architecture and the final downstream architecture.
BERT는 초록에서 살펴본 바와 같이 fine-tuned with just one additional output layer : 단 하나의 아웃풋 레이어만 추가해서 파인튜닝을 합니다. 그래서 다운스트림 태스크에 따른 파인튜닝 전후에 구조 차이가 거의 없는 편이고, 그만큼 다양한 NLP 작업에서 일관된 성능을 발휘할 수 있는 장점이 있습니다.
We primarily report results on two model sizes: BERT BASE (L=12, H=768, A=12, Total Parameters=110M) and BERT LARGE (L=24, H=1024, A=16, Total Parameters=340M).
버트에는 크게 두가지 사이즈의 모델이 있어요.
BERT BASE
768차원(H)을 12개의 벡터로 나눠서(64차원씩) 멀티헤드 어텐션수행(A)
인코더 블록 총 12번 반복(L)
BERT LARGE
1024차원(H)을 16개의 벡터로 나눠서(64차원씩)멀티헤드 어텐션수행(A)
인코더 블록 총 24번 반복(L)
바닐라 트랜스포머가 512차원을 8개의 벡터로 나눠서(64차원씩) 멀티헤드 어텐션 수행, 인코더 블록을 총 6번 반복(후 디코더를 사용)했던 것과 비교하면 버트는 그보다 훨씬 더 deep한 인코더를 구성했다고 볼 수 있고, 이로 인해 버트는 문맥 정보를 더욱 깊이 학습하게 되어 다양한 NLP작업에서 높은 성능을 발휘할 수 있게 됩니다. 논문 초록에서BERT가 deep한 bidirectional(both left and right) representations을 학습하도록 고안되었다고 한 이유를 여기서 찾아볼 수 있겠네요.
BERT BASE was chosen to have the same model size as OpenAI GPT for comparison purposes. Critically, however, the BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
논문에서 계속 OPENAI GPT와의 비교를 하면서 우리는 양방향이고 쟤네는 단방향이라 우리가 더 좋다!는 뉘앙스의 문장이 빈번하게 나오는데요. (ㅋㅋㅋㅋ) BERT와 GPT는 애초에 타겟하는 목적이 다르기 때문에, 무엇이 더 좋고 나쁘다고 비교할 문제는 아닌것 같고, 저는 각자가 목적에 맞는 구조를 알맞게 잘 선택한 것으로 이해했습니다.
[CLS] is a special symbol added in front of every input example, and [SEP] is a special separator token.
To make BERT handle a variety of down-stream tasks, our input representation is able to unambiguously represent both a single sentence and a pair of sentences (e.g., h Question, Answeri) in one token sequence. We use WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary.
BERT는 fine-tuning을 통해 다양한 다운스트림 task를 수행할 수 있도록 input representation으로 하나의 문장(a single sentence)을 받을 수도 있고, 한 쌍의 문장(a pair of sentence)을 받을 수도 있도록 설계되었습니다. 토큰 임베딩을 위해서는 30,000개의 토큰 어휘를 가진 WordPiece 임베딩(Wu et al., 2016)을 사용하구요.
The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways. First, we separate them with a special token ([SEP]). Second, we add a learned embedding to every token indicating whether it belongs to sentence A or sentence B.
모든 시퀀스는 다음과 같이 구성되어 있습니다.
첫 번째 토큰 : 분류 작업에 필요한 토큰 [CLS]
첫 번째 문장(A) 토큰
가운데 [SEP] 토큰 : 두 문장을 구분하는 역할
두 번째 문장(B) 토큰
마지막 [SEP] 토큰 : 시퀀스의 끝을 알려주는 역할
이 때 각 토큰이 문장 A에 속하는지 B에 속하는지 구별할 수 있는 Segment Embeddings 작업이 추가 수행됩니다. 아래 Figure 2에서 이 부분을 조금더 시각화해서 살펴볼 수 있습니다.
트랜스포머가 Token Embedding과 Positional Encoding 정보를 더해서 입력값을 완성하는 것에서 나아가 BERT는 Segment Embeddings까지 한 번 더 더해주게 됩니다. [SEP] 토큰을 기준으로 각 토큰이 문장 A에 속하는지 B에 속하는지를 구분하는 것이죠.
이 작업은 이어서 자세히 살펴볼 문장 예측(NSP)을 위해 사용됩니다.
3-1. Pre-training BERT
BERT의 Pre-training의 핵심 unsupervised-task, MLM과 NSP를 살펴봅시다.
[1] Masked LM(MLM) : 마스킹된 언어 모델
In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. (중략) In all of our experiments, we mask 15% of all WordPiece tokens in each sequence at random.In contrast to denoising auto-encoders (Vincent et al., 2008), we only predict the masked words rather than reconstructing the entire input.
MLM은 deep bidirectional representation을 가능하게 하기 위해서 input tokens의 15%를 무작위로 랜덤 마스킹하고, 그 부분을 예측하도록 학습을 시키는 과정을 의미합니다.
Although this allows us to obtain a bidirectional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, we do not always replace “masked” words with the actual [MASK] token. The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time.
그런데, 문제가 있습니다. 우리가 downstream 태스크를 위해 BERT를 파인튜닝할 때, 파인튜닝용으로 준비한 데이터에 15%를 지켜 마스킹이 준비되어있기는 아무래도 어렵겠죠. 따라서 pre-training data와 fine-tuning 데이터가 서로 일치하지 않는 문제점이 발생할 수가 있습니다.
따라서 버트는 input tokens의 15%를 무작위로 선택한 다음, 선택된 i번째 토큰을
80% 확률로 진짜 마스크 토큰([MASK])으로 대체합니다. 예를 들어 '감자'를 [MASK]로 대체하고 이를 예측하도록 학습시킵니다.
10% 확률로 무작위 토큰으로 대체합니다. 예를 들어 '감자'를 '생선'으로 바꾸어 버립니다.
10% 확률로 원래 토큰을 그대로 둡니다. 예를 들어 '감자'를 그냥 그대로 '감자'로 둡니다.
부록 A - Additional Details for BERT
The advantage of this procedure is that the Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token.
부록에 따르면 이러한 방법을 사용함으로써 인코더가 예측할 단어나 무작위로 대체된 단어를 알지 못해, 모든 입력 토큰의 문맥을 이해하도록 상황이 강제되는 이점이 있다고 합니다. 즉, 항상 [MASK] 토큰에만 의존하지 않고 문맥을 기반으로 예측할 수 있는 능력을 기르고, 파인튜닝 데이터에 [MASK] 토큰이 등장하지 않아도 문제가 없도록 설계한 것입니다.
[2] Next Sentence Prediction(NSP) : 다음 문장 예측
Many important downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling.
질의응답(QA)나 자연어 추론(NLI) 같은 작업에서는 '두 문장의 관계'를 파악할 필요성이 있습니다. 그런데 기존의 language modeling은 주로 다음 단어를 예측하거나, 문장 내에서 단어의 순서와 패턴을 학습하는 등의 작업을 중점적으로 수행합니다. 두 문장 사이의 관계를 파악하는 것과는 거리가 멀죠. 그래서 BERT는 QA나 NLI같은 다양한 downstream task를 수행할 수 있도록, 모델이 두 문장 사이의 관계를 파악할 수 있도록 pre-train을 시켰습니다.
In order to train a model that understands sentence relationships, we pre-train for a binarized next sentence prediction task that can be trivially generated from any monolingual corpus.
BERT에서 NSP(Next Sentence Prediction)는 입력 시퀀스 내에서 문장 A와 문장 B가 서로 연속된 문장인지 아닌지를 판단하는 이진 분류(binary classification) 작업입니다. 주어진 두 문장이 실제로 연속된 문장(True)인지, 아니면 무작위로 선택된 다른 문장(False)인지를 예측합니다. NSP는 monolingual corpus(단일 언어 코퍼스) - 한 가지 언어로 된 텍스트 데이터 집합 내에서 학습이 가능합니다.
이 때, 앞서 살펴본 [CLS] 토큰이 바로 다음 문장 예측(NSP)에 사용되는 토큰이구요. MLM의 경우 입력 시퀀스 내에서 선택된 15%의 토큰이 80%의 확률로 마스킹되지만, NSP의 경우 모든 입력 시퀀스에 대해서 100% 수행이 됩니다.
Specifically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext). As we show in Figure 1, C is used for next sentence prediction (NSP).5 Despite its simplicity, we demonstrate in Section 5.1 that pre-training towards this task is very beneficial to both QA and NLI.
50%의 입력 시퀀스는 실제로 문장 A와 문장 B가 연속된 문장으로 구성되며, 레이블 IsNext(True)를 가집니다.
나머지 50%의 입력 시퀀스는 무작위로 선택된 문장으로 구성되며, 레이블 NotNext(False)를 가집니다.
부록 A - Additional Details for BERT
어찌 보면 굉장히 단순한 작업이지만, NSP 작업을 통해 BERT는 두 문장 간의 관계를 이해하는 능력을 학습하게 되고, 이로 인해 QA(Question Answering)나 NLI(Natural Language Inference)와 같은 다운스트림 작업을 더 잘 수행하게 된다고 하네요.
The NSP task is closely related to representationlearning objectives used in Jernite et al. (2017) and Logeswaran and Lee (2018). However, in prior work, only sentence embeddings are transferred to down-stream tasks, where BERT transfers all parameters to initialize end-task model parameters
이 부분은 - BERT의 NSP task가 이전 연구 (Jernite et al., 2017; Logeswaran and Lee, 2018)에서 영감을 받기는 했지만, 두 문장 사이의 관계를 파악하도록 CLI 토큰을 사용한 것은 BERT의 독창적인 아이디어다 - 정도로 이해하고 넘어가겠습니다.
3-2. Fine-tuning BERT
For each task, we simply plug in the task-specific inputs and outputs into BERT and finetune all the parameters end-to-end.
BERT의 파인튜닝(fine-tuning)은 사전 학습된 모델의 모든 파라미터를 end-to-end 방식으로 업데이트합니다.
At the input, sentence A and sentence B from pre-training are analogous to (1) sentence pairs in paraphrasing, (2) hypothesis-premise pairs in entailment, (3) question-passage pairs in question answering, and (4) a degenerate text-∅ pair in text classification or sequence tagging.
BERT의 사전 학습에서 사용된 문장 A와 문장 B의 구조는 파인튜닝을 통해 다양한 다운스트림 작업에 적용될 수 있어요. 예를 들어서,
Paraphrasing: 두 문장이 서로 같은 의미를 전달하는지 평가할 수 있습니다.
Entailment: 문장 A는 가설(hypothesis), 문장 B는 전제(premise)일 때, 이 두 문장이 포함 관계에 있는지 판단할 수 있습니다.
Question Answering: 문장 A는 질문(question), 문장 B는 답변을 포함한 문맥(context)일 때, 문맥에서 질문에 대한 답을 찾는 질의응답 작업을 수행할 수 있습니다.
Text Classification or Sequence Tagging: 문장 A는 텍스트, 문장 B는 빈 값(∅)일 때, 단일 문장 분류 작업이나 시퀀스 태깅 작업을 수행할 수 있습니다.
At the output, the token representations are fed into an output layer for tokenlevel tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.
출력 단계에서는 2가지 작업이 이루어집니다.
Token-Level Tasks (토큰 레벨 작업)
입력 시퀀스의 각 토큰에 대해 BERT는 벡터 representation을 생성하고, 이 벡터는 각 토큰의 의미와 문맥 정보를 담고 있습니다. 이 representation이 출력 레이어로 전달되면 Sequence Tagging (시퀀스 태깅)이나 Question Answering (질문 응답) 등의 다운스트림 태스크를 수행할 수 있습니다.
Sequence Tagging (시퀀스 태깅): 예를 들어, 입력 문장에서 각 단어를 명사, 동사 등으로 태깅하는 작업입니다. "I am eating an apple"라는 문장이 주어지면, 각 단어에 대해 'I: PRON', 'am: VERB', 'eating: VERB', 'an: DET', 'apple: NOUN'와 같이 태깅합니다.
Question Answering (질문 응답): 문맥 내에서 질문에 대한 답을 찾는 작업입니다. 예를 들어, "What is the color of the sky?"라는 질문이 주어졌을 때, "The sky is blue"라는 문맥에서 "blue"라는 단어를 찾아내는 작업입니다.
Sentence-Level Tasks (문장 레벨 작업)
BERT에서 입력 시퀀스의 첫 번째 토큰인 [CLS] 토큰이 벡터로 변환되고, 이 벡터는 입력 시퀀스 전체를 대표하는 의미를 담고 있습니다. 이 CLS representation이 출력 레이어로 전달되면 entailment 또는 sentiment analysis 등의 문장 전체에 대한 예측을 수행할 수 있습니다.
Entailment (포함 관계 판단): 두 문장이 포함 관계에 있는지 판단하는 작업입니다. 예를 들어, "The cat is on the mat" (전제)와 "There is a cat on the mat" (가설)가 주어졌을 때, 포함 관계(True/False)를 예측합니다.
Sentiment Analysis (감정 분석): 입력 문장의 감정이 긍정적인지 부정적인지 분류하는 작업입니다. 예를 들어, "I love this movie"라는 문장이 주어졌을 때, 감정이 긍정적인지 부정적인지 예측합니다.
Compared to pre-training, fine-tuning is relatively inexpensive.
사전 학습에 비해 파인튜닝은 상대적으로 굉장히 비용 효율적이고, 논문의 모든 결과는 단일 Cloud TPU에서 최대 1시간, GPU에서는 몇 시간 내에 재현할 수 있다고 하네요.
마무리
BERT 논문을 리뷰하면서 언어 모델의 사전 학습과 전이 학습이 자연어 처리에서 얼마나 중요한 역할을 하는지 깊이 이해할 수 있었습니다. 특히, BERT가 문맥을 이해하는 인코더를 구현하기 위해 양방향 아키텍처, MLM, NSP 작업을 적절히 고안하고 배치한 점이 무척 인상깊었어요. 자본과 기술력 뿐만 아니라 창의적이고 새로운 아이디어로 인공지능 혁신을 이어가는 모델들을 리뷰할 때마다 경이로움을 느끼게 됩니다.
저는 Long-Context를 처리해야 하는 LLM / QA task 솔루션 개발이라는 과제를 맡으면서 버트 논문을 리뷰하게 되었는데요. 최신 QA task들은 Long-Context를 처리하기 위해 버트 기반의 인코더 중심 모델뿐만 아니라 RAG 기술을 적용한 GPT 기반 디코더 중심 모델을 사용하고 있기도 한다는 사실을 알았습니다. 따라서 다음 논문 리뷰로는 OpenAI의 ChatGPT 초기 모델을 선정하여 구조를 파악해보려고 합니다.