Peft는 Parameter-Efficient Fine Tuning의 약자로, 말 그대로 파인튜닝을 조금 더 효율적으로 할 수 있는 방법론을 의미합니다. Peft를 실현할 수 있는 종류에는 다양한 것들이 있는데, 가장 대표적으로 사용되는 방법 중 하나로는 LoRA(로라)가 있습니다.
본 포스팅에서는 LoRA의 논문 핵심 파트를 가볍게 리뷰하고, peft와 unsloth, trl 라이브러리를 이용해서 로라방식의 LLM 파인튜닝을 직접 코드로 진행해 보겠습니다.
논문

LoRA는 2021년 발표된 마이크로소프트의 논문 [LoRA: Low-Rank Adaptation of Large Language Models]에서 제안한 효율적인 파인튜닝 방법입니다. 다양한 거대 모델에 적용할 수 있고, 논문에서는 언어 모델을 중심으로 설명을 합니다.
Abstract
논문의 초록에서는 다음과 같이 로라의 핵심을 짚어서 말해주고 있어요.

We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks.
- pretrained된 모델의 weight를 freeze한다.
- 학습 가능한 rank-decomposition, 즉 '분해된' 행렬을 트랜스포머 구조의 각 레이어마다 하나씩 주입한다.
- 이를 통해 downstream 태스크를 위해 파인튜닝할 때 트레이닝할 파라미터의 수를 획기적으로 줄일 수 있다.

Figure 1의 그림은 다들 많이 보셨을 것이라고 생각합니다. 파란색의 Pretrained Weights는 기존의 사전학습된 모델이 가지고 있던 웨이트맵을 의미하고, LoRA는 이는 수정할 수 없도록 freeze시킵니다. 대신 벡터 내적을 수행했을 때 W와 크기가 같아지는 주황색 A, B 행렬을 만들어서 트랜스포머 레이어 사이사이에 inject - 꽂아 넞어주고, 그 A, B 행렬을 트레이닝 시킵니다.
We hypothesize that the change in weights during model adaptation also has a low “intrinsic rank”, leading to our proposed Low-Rank Adaptation (LoRA) approach. LoRA allows us to train some dense layers in a neural network indirectly by optimizing rank decomposition matrices of the dense layers’ change during adaptation instead, while keeping the pre-trained weights frozen, as shown in Figure 1.
LoRA는 기존의 웨이트맵 행렬을 분해(rank decomposition)시켜서 기존의 freeze된 웨이트맵에 더해주는 방식으로 간접적으로 업데이트 합니다. 예를 들어서 W의 크기가 (10, 10)이고 분해된 행렬 A, B의 크기는 각각 (10, 2)와 (2, 10)이라고 해 봅시다.
- W의 파라미터 수는 10*10 = 100(개) 입니다.
- A와 B의 파라미터 수는 각각 20개씩으로 총합 40개입니다.
- LoRA를 사용하면 기존의 100개 파라미터는 freeze시키고, 대신 분해된 행렬(A, B)의 40개 파라미터만 트레이닝하면 됩니다. A, B를 행렬곱하면 (10, 10) 사이즈가 되므로 기존의 웨이트맵에 더해줄 수 있습니다. 따라서 학습시켜야 할 파라미터의 수가 full-finetuning에 비해서 줄어들게 되고, 리소스를 효율적으로 활용할 수 있습니다.
1. Introduction
논문의 서론(Introduction)에서는 아래와 같이 로라의 핵심 장점을 요약해서 말하고 있습니다.

- 사전 학습된 모델의 파라미터는 동결시키고, 필요한 task에 따라 A와 B만 학습시키면 되기 때문에, 사전학습된 거대 모델을 다양한 downstream에 더 잘 활용할 수 있습니다.
- LoRA를 사용하면 inject한 low-rank matrices만 최적화시키면 되기 때문에 학습이 매우 효율적이고, 진입에 대한 하드웨어 장벽을 최대 3배까지 낮춰 준다고 합니다.
- 기존의 fully fine-tuning과 비교했을 때 inference latency(input이 들어가서 모델이 예측을 하기까지 걸리는 시간)이 없는 장점이 있습니다 - 따라서 아주 간단한 선형 구조만으로 freeze된 기존의 웨이트와 새롭게 학습시킨 웨이트를 병합할 수 있습니다.
- LoRA는 prefix 기반 접근과 함께 사용될 수 있습니다.
2. Problem Statement
논문의 2장 PROBLEM STATEMENT에서는 수식과 함께 자세한 설명을 합니다.

로라 기법을 적용하지 않은 full fine-tuning에서는 pre-trained된 웨이트맵을 불러와서 목적함수를 업데이트하는 최대우도법(1)을 사용합니다. 즉, 최대우도법을 이용해 모델의 전체 파라미터 Φ 를 업데이트합니다. 저자들은 이렇게 모든 파라미터를 업데이트하는 방식보다 효율적인 LoRA를 제시하는데요. LoRA를 이용해 일부분의 파라미터만 업데이트하는 목적식은 다음과 같습니다.

기존의 model 파라미터인 를 이용해 forward를 진행하고 얻어지는 (기울기)를 이용해 backpropagation을 진행할 때, LoRA의 파라미터 를 이용합니다. 논문에 따르면 LoRA로 업데이트하는 파라미터 Θ 의 크기인 | Θ | 가 기존의 full fine-tuning으로 업데이트하는 파라미터 Φ 의 크기인 | Φ | 의 0.01%라고 합니다. 그만큼 훨씬 효율적으로 튜닝이 가능하며, 각 downstream task마다 다른 LoRA layer를 사용할 수 있기 때문에 목적에 맞는 파인튜닝된 모델을 효율적으로 생산할 수 있는 것입니다.
허깅페이스 & LoRA
저는 논문 뿐만 아니라 라이브러리 docs 보는 것도 아주 좋아하기 때문에 - 보기 좋게 정리가 잘 되어 있어서 특히 허깅페이스 좋아합니다 - 로라와 관련된 허깅페이스 문서들을 조금 더 살펴보도록 하겠습니다.
https://huggingface.co/docs/diffusers/training/lora
LoRA
This is experimental and the API may change in the future. LoRA (Low-Rank Adaptation of Large Language Models) is a popular and lightweight training technique that significantly reduces the number of trainable parameters. It works by inserting a smaller nu
huggingface.co
허깅페이스의 Diffuser Docs에서는 LoRA를 a popular and lightweight training technique that significantly reduces the number of trainable parameters라고 설명하고 있습니다. 또한 논문에서 미리 살펴본 바와 같이 It works by inserting a smaller number of new weights into the model and only these are trained - 적은 수의 새로운 웨이트맵을 Insert하고, 딱 그것들만 학습시킨다는 점을 짚어주고 있습니다.
로라는 가장 처음에 언어 모델에 고안되었지만, 그 확장성과 용이성으로 인해 많은 Diffusion 모델에 사용되고 있다고 합니다. 실제로 저도 Stable Diffusion을 파인튜닝하여 text-to-image 모델을 구현하는 데 로라 기법을 사용한 경험이 있습니다.
https://huggingface.co/docs/peft/conceptual_guides/adapter
Adapters
Adapter-based methods add extra trainable parameters after the attention and fully-connected layers of a frozen pretrained model to reduce memory-usage and speed up training. The method varies depending on the adapter, it could simply be an extra added lay
huggingface.co
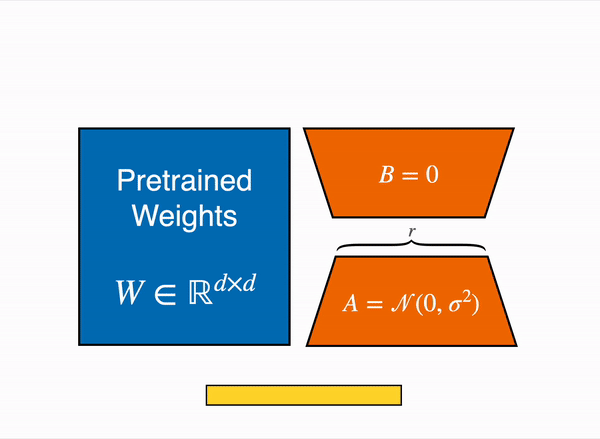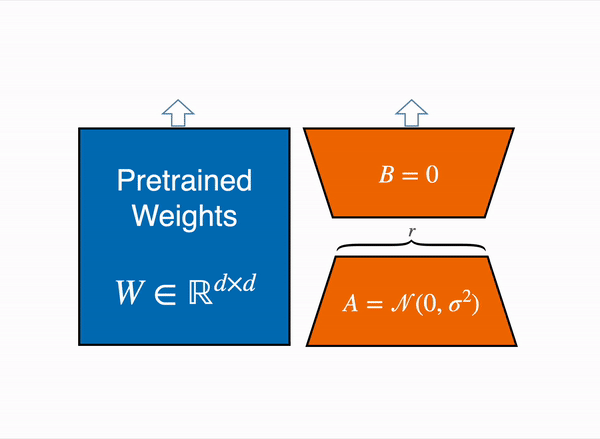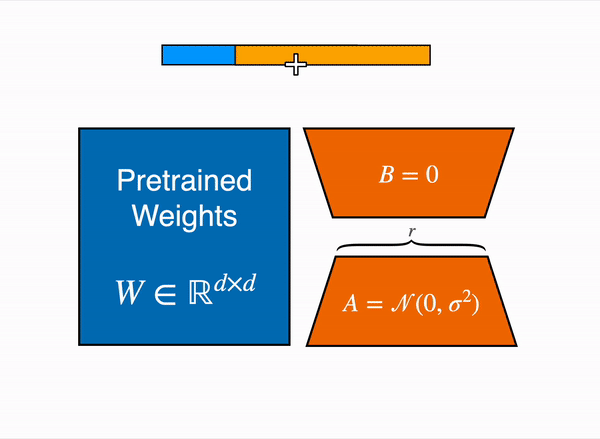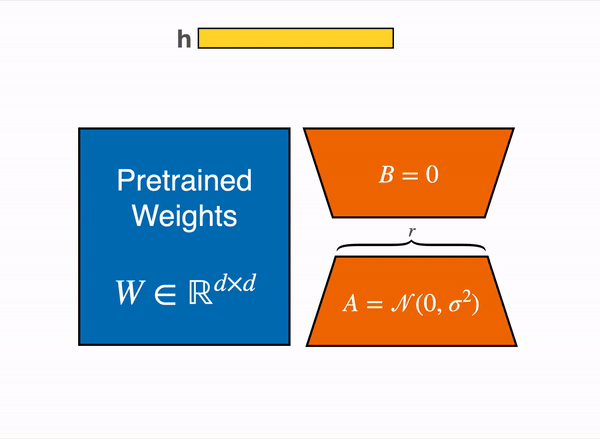
허깅페이스의 PEFT docs 페이지의 'Adapters'에서도 LoRA에 관해 이야기하고 있습니다. 위 애니메이션은 우리가 논문에서 살펴보았던 LoRA의 행렬 분해 방식을 잘 보여주고 있습니다.
In principle, LoRA can be applied to any subset of weight matrices in a neural network to reduce the number of trainable parameters. However, for simplicity and further parameter efficiency, LoRA is typically only applied to the attention blocks in Transformer models. The resulting number of trainable parameters in a LoRA model depends on the size of the update matrices, which is determined mainly by the rank r and the shape of the original weight matrix.
이론적으로 LoRA는 neural-network 구조를 가지는 모델의 어떤 부분에든지 적용될 수 있지만, 간소화와 파라미터 효율성을 고려하여 보통 트랜스포머 구조의 attention layer에 적용되는 것이 일반적이라고 합니다. 나중에 코드에서 다시 살펴보겠지만, 분해된 행렬의 사이즈를 정의하는 하이퍼 파라미터로는 rank r이 있습니다. Figure 1 이미지의 주황색 부분에 잘 보면 r이라고 써있습니다 :)

r의 값이 작을수록 계산은 쉽고 빠르겠지만 downstream task에 따른 디테일한 학습이 어려울 수 있고, r의 값이 클수록 디테일한 파라미터 업데이트가 가능하지만 그만큼 분해 행렬의 파라미터 수도 많아지므로 계산량이 늘어납니다. 따라서 주어진 Task에 따라 적절한 r값을 찾아내고 설정하는 것이 모델러의 중요한 임무중 하나라고 할 수 있겠습니다.
unsloth
huggingface 공식 peft docs 페이지, unsloth 공식 깃허브, 허깅페이스 블로그 글 - 총 3가지 레퍼런스를 참고하여 최신 LLaMA 3.1-8B 모델을 직접 LoRA 방식으로 파인튜닝 해보도록 하겠습니다.
- https://huggingface.co/docs/peft/package_reference/lora
- https://github.com/unslothai/
- https://huggingface.co/blog/Andyrasika/finetune-unsloth-qlora
Unsloth AI
Our mission is to make LLMs for everyone 🦥. Unsloth AI has 6 repositories available. Follow their code on GitHub.
github.com
Unsloth는 대형 언어 모델(LLM)들의 파인튜닝과 훈련을 가속화하고 메모리 사용을 최적화하기 위한 오픈 소스 라이브러리입니다. 특히 Llama, Mistral, Phi, Gemma 등의 LLM 모델들을 2-5배 빠르게 훈련시키고 메모리 사용량을 최대 80%까지 줄일 수 있습니다. 실제로 사용해본 결과, 지인짜 빠르고 편리합니다. 강추...
위 공식 깃허브에서 Finetune for Free 아래의 Llama 3.1 (8B) Free Notebooks 코드를 클릭하면 Colab 코드가 실행됩니다. 저는 코랩 코드를 참고하여 로컬 On-Premise GPU에서 진행하였습니다. 저처럼 로컬에서 진행하시는 경우 공식 깃허브를 참고하여 unsloth 라이브러리를 사용하기 위한 환경설정과 다운로드를 완료한 뒤에 코드를 실행하시기 바랍니다.
LoraConfig
먼저 간단하게 peft 라이브러리에서 설정할 수 있는 LoRA Configuration 하이퍼파라미터 3가지만 짚고 넘어가 보겠습니다.

- r (int) — Lora attention dimension (the “rank”)
- 위에서 살펴본 r - rank decomposition의 r값을 설정, r이 클수록 분해 행렬의 사이즈가 커집니다.
- 예를 들어, 만약 원래의 파라미터 행렬이 m×n 크기라면, A m×r, B는 r×n 크기가 됩니다.
- lora_alpha (int) — The alpha parameter for Lora scaling
- lora_alpha는 직접적으로 로라 페이퍼 원문에서 언급된 적은 없지만 중요한 역할을 하는 하이퍼파라미터입니다. lora_alpha 파라미터는 low-rank decomposition 행렬이 기존의 고정된(weight-frozen) 모델 파라미터에 합쳐질 때, 그 비율을 결정합니다. 즉, 분해된 저차원 행렬의 영향을 원래 모델에 얼마나 반영할지를 조절하는 것이 바로 lora_alpha 파라미터입니다.
- 참고한 허깅페이스 블로그에서는 the strength of the applied LoRA라고 설명하고 있습니다.
- lora_dropout (float) — The dropout probability for Lora layers.
Unsloth 이용 llama3.1-8B 파인튜닝 (QA task)
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = Noneunsloth 라이브러리의 FastLanguageModel 클래스를 이용하여 라마3.1-8B모델을 불러올텐데요.
load_in_4bit = False # 4비트로 양자화된 모델을 불러올 경우 True로 설정 -> 조금 더 빨라짐
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit
)저는 load_in_4bit을 False로 설정하고 양자화되지 않은 기본 라마3.1-8B을 불러왔습니다. 코랩 T4 등의 작은 GPU로 실행하시는 경우 이 값을 True로 설정하셔서 가볍게 돌리시는 것을 추천합니다.
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 1004,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)위에서 살펴본 LoRA 관련 하이퍼파라미터들이 보입니다.
새로운 하이퍼파라미터로 use_rslora가 있는데요. RsLoRA는 LoRA 방식의 변형으로, 랭크를 안정화시키는 기법을 통해 효과적으로 파인튜닝을 할 수 있는 방법이라고 합니다. RsLoRA는 학습 과정 중에 랭크를 동적으로 조절하여 최적화하는데, 고정된 랭크를 사용하는 기존 LoRA 방식에 비해 더 나은 성능을 도출할 수 있다고 하네요. 저는 우선 False로 설정했고, 나중에 True로 변환하여 성능을 비교해보고자 하였습니다. 또한 코랩과 같은 제한된 환경에서 실행하는 경우에도 False로 설정하는것이 낫겠습니다.
또한 loftq_config의 경우 모델의 백본 가중치를 양자화하고 LoRA 계층을 초기화하는 방법을 정의한다고 합니다. 저는 모델을 로드할 때 load_in_4bit을 False로 두어 양자화되지 않은 기본 모델을 로드했으며, loftq_config 역시 None으로 설정하여 모델의 백본 가중치를 양자화하지 않는 것으로 설정하였습니다.
from datasets import load_dataset
dataset = load_dataset("ruslanmv/ai-medical-chatbot", split = "train")
prompt = """You are a professional medical doctor. Based on the below context, generate answer for the question.
### Description:
{}
### Patient:
{}
### Doctor:
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
instructions = examples["Description"]
inputs = examples["Patient"]
outputs = examples["Doctor"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# Must add EOS_TOKEN, otherwise your generation will go on forever!
text = prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
pass
dataset = dataset.train_test_split(test_size=0.01)
dataset_train = dataset['train']
dataset_test = dataset['test']
dataset_train = dataset_train.map(formatting_prompts_func, batched = True,)
dataset_test = dataset_test.map(formatting_prompts_func, batched = True,)저는 허깅페이스에서 medical chatbot QA task용으로 준비된 데이터셋을 사용해서 위와같이 전처리과정을 거쳤습니다. train 데이터는 총 254,346개이며 test 데이터는 총 2,570개가 있습니다.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset_train,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
num_train_epochs = 1,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 1004,
output_dir = "outputs",
),
)다음으로 trl 라이브러리의 SFTTrainer 클래스를 사용해서 superfised fine tuning(SFT)을 진행합니다.
- per_device_train_batch_size: 각 디바이스(예: GPU)당 훈련에 사용할 배치 크기- 모델이 한 번의 훈련 스텝에서 처리할 데이터 샘플의 수를 의미. 크기가 클수록 더 많은 메모리가 필요하며, 일반적으로 크기가 클수록 더 나은 일반화 성능을 제공함.
- gradient_accumulation_steps: 그래디언트 누적 단계의 수
- warmup_steps: 학습률이 선형적으로 증가하는 워밍업 스텝 수 - 모델이 학습 초반에 너무 큰 학습률로 인해 불안정해지는 것을 방지하는 역할. 초기에는 낮은 학습률로 시작하여 점진적으로 증가시키도록 함.
- is_bfloat16_supported()
- is_bfloat16_supported() : Unsloth 라이브러리에서 제공하는 함수 - 현재 사용 중인 하드웨어가 bfloat16(Brain Floating Point 16) 정밀도를 지원하는지 여부를 확인하는 역할
- bfloat16이 지원되는 경우, 이를 사용하여 메모리 사용량을 줄이고 훈련 속도를 높이는 것이 가능 (지원되지 않는 경우, fp16 또는 fp32를 사용)
- fp16과 bf16은 상호 배타적인 설정으로 동시에 사용할 수 없음
- logging_steps : 로그를 기록할 스텝 간격
- optim : 사용할 옵티마이저의 종류 ("adamw_8bit"는 AdamW 옵티마이저를 8비트 정밀도로 사용하여 메모리 효율성을 높이고 계산 비용을 줄임)
- weight_decay : 가중치 감쇠(L2 정규화) 계수 (모델의 복잡성을 줄이고 과적합을 방지하기 위해 가중치 값을 점진적으로 감소시키는 역할)
- lr_scheduler_type: 학습률 스케줄러의 유형 (linear는 학습률을 선형적으로 감소)
- output_dir : 훈련 결과를 저장할 디렉토리 경로
trainer_stats = trainer.train()
학습이 완료되었습니다.
def inference_i(i):
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
question = dataset_test[i]['Description']
inputs = tokenizer(
[
prompt.format(
"Answer the question truthfully, you are a medical professional.", # instruction
question, # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 1024, use_cache = True)
tokenizer.batch_decode(outputs)
predict = tokenizer.batch_decode(outputs)[0].split("###")[-1]
truth = dataset_test[i]['Doctor']
print("-----------------------")
print(f"question : {question}")
print("-----------------------")
print(f"inference : {predict}")
print("-----------------------")
print(f"label answer : {truth}")
print("-----------------------")
return question, predict, truth위와 같이 dataset_test의 i번째 데이터에 대해 inference를 수행할 수 있는 함수를 직접 작성했구요.
question, predict, truth = inference_i(0)요런식으로 실행하면 question, inference 결과, 기존의 label answer값을 확인할 수 있습니다.
question : High BP, have consistent cough with chest pain, traces of blood in phlegm. Normal chest x-ray, on BP medicines. Cause?
[데이터셋의 답변 예시] label answer : Hello there, In addition to the possibilities of asthma, chest infection which have been ruled out by X Ray etc, another possibility is GERD(gastro esophageal reflux disease/gastritis). You might need to take a course of pantoprazole/omeprazole , if that is the case. It is possible that the stress(you said you were worried about your brother's son) could have caused GERD/gastritis.
1. I would advise you to have frequent small meals.
2. Avoid spicy,deep fried,fatty food and carbonated beverages.
3.Do relaxation exercises/meditation.
4. Avoid sleeping/lying down immediately after a meal. Wait for 2 hours before lying down after a meal.
5.Avoid smoking/alcohol. Hope this helps.
Please let me know if you need any further advise. Regards, Dr.Divya Kuttikrishnan
위와 같은 질문을 던졌을 때, 파인튜닝한 llama3.1-8B모델은 아래와 같이 답변했습니다.
Hello, Thanks for writing to us. Chest pain with cough is very serious and needs to be investigated. Chest X-ray is a very basic investigation and needs to be followed by a CT scan of the chest. CT scan is a very important investigation and will help in identifying the cause of the chest pain. If the CT scan is normal, then you need to get an ECG and echocardiogram done. These will help in identifying the cause of the chest pain. I hope this helps. Take care. Regards, Dr. Rakesh Kumar, General & Family Physician
데이터셋의 예시 답변과 비교하면 풍부함이 조금 떨어지긴 하나, medical QA로서의 의무는 어느정도 수행하고 있다고 평가할 수 있을 것 같습니다. 그렇다면 파인튜닝을 하나도 거치지 않은 기본 llama3.1-8B모델은 같은 질문에 대해서 어떻게 대답할까요?

medical QA datset으로 파인튜닝한 모델에 비하면 기본 모델은 medical QA보다는 LLM스러운 조금 더 일반적이고 풍부한 대답을 보여주는 것 같습니다. 솔직히 파인튜닝 안한게 더 나아보입니다. 인삿말이나 마무리말 정도는 프롬프팅으로도 충분히 구현할 수 있으니까요. 파인튜닝이 반드시 성공적으로 끝나는 것은 아니다-라는 좋은 예시가 되겠습니다...(ㅋㅋㅋㅋ)
파인튜닝을 통해 기본 백본 모델보다 나은 결과를 도출하기 위해서는 하이퍼파라미터 튜닝과 최적화 과정을 거쳐야 할 것으로 생각되구요. 또 제가 의학 전문가가 아니다보니 퀄리티 측면에서 무엇이 더 낫다고 평하기 조금 애매한 부분이 있어서, 실제 프로젝트에서는 도메인 관련한 전문가와의 협업이 필수적으로 요구될 것으로 생각됩니다.
파인튜닝을 통해 downstream task에 적용할 수 있는 더 나은 모델을 만드는 과정은 제가 지금 구축하고 있는 실제 LLM 프로젝트에서 조금더 고민해보는것으로 하고, 본 포스팅은 이정도로 마무리를 하겠습니다 :-) 본 포스팅을 통해 LoRA, Peft, Unsloth를 통한 효율적인 파라미터 튜닝 방법에 대해 고찰해볼 수 있는 좋은 기회였습니다.
감사합니다 :)
'Data Science > DL 딥러닝' 카테고리의 다른 글
| 딥러닝 | Improving Retrieval Augmented Language Model with Self-Reasoning(2024) 논문 리뷰 (0) | 2024.10.29 |
|---|---|
| 딥러닝 | RAG(2021) 논문 리뷰 (0) | 2024.08.05 |
| 딥러닝 | RAG 활용 pdf파일 검색 챗봇시스템 구현하기 (4) | 2024.07.24 |
| 딥러닝 | BERT(2019) 논문 리뷰 (7) | 2024.07.22 |
| 딥러닝 | 트랜스포머 positional encoding 코드 구현 (문제 해결) (0) | 2024.07.06 |