
RAG와 LC를 사용한 LLM의 긴 문맥 응용에 대한 가이드라인을 제공하겠다는 2024 최신 연구 논문.
최신 LLM의 max-token이 기하급수적으로 늘어나면서 Long-Context를 점점 더 잘 처리하고 있습니다. 예를 들어서 구글 Gemini 1.5의 경우 1백만 토큰까지 입력받을 수가 있고, LLama3.2 경량 모델의 경우 128K(12만8천) 토큰 입력이 가능합니다. 그래서 "RAG를 굳이 써야 될까?"라는 의문을 가진 사람도 있어요. RAG의 문제점이 많은데, 그냥 최신 LLM한테 문서를 통째로 주면 훨씬 더 일처리를 잘하니까 그렇죠. 그럼 RAG는 이제 쓸모가 없어질까?하는 의문도 들기 시작하고요.
하지만 입출력 token의 갯수에 비용이 비례하는 현재 상황에서 여전히 RAG는 cost efficiently하다는 커다란 메리트를 가지고 있고, 그래서 사람들은 연구개발을 계속하고 있습니다.
이러한 상황 속에서, 이 논문은 RAG와 Long-Context (LC) LLM을 포괄적으로 비교하여 각각의 장점을 활용할 수 있는 SELF-ROUTE라는 방법을 제안합니다.
바쁘신 분은 맨 아래
'논문 핵심 요약'만 보세요.
Abstract
We benchmark RAG and LC across various public datasets using three latest LLMs. Results reveal that when resourced sufficiently, LC consistently outperforms RAG in terms of average performance. However, RAG’s significantly lower cost remains a distinct advantage.
세 가지 최신 LLM을 사용하여 다양한 공개 데이터셋에서 RAG와 LC를 벤치마크한 결과, 충분한 자원이 있을 때 LC가 평균 성능 면에서 RAG를 일관되게 능가한다는 것을 확인, 그러나 RAG의 훨씬 낮은 비용은 여전히 독특한 이점
Based on this observation, we propose SELF-ROUTE, a simple yet effective method that routes queries to RAG or LC based on model self-reflection. SELFROUTE significantly reduces the computation cost while maintaining a comparable performance to LC.
이러한 관찰을 바탕으로, 저자들은 모델의 자체 반성을 통해 RAG나 LC로 쿼리를 라우팅하는 간단하면서도 효과적인 방법인 SELF-ROUTE를 제안. SELF-ROUTE는 계산 비용을 크게 줄이면서 LC와 유사한 성능을 유지함.
1 Introduction
Therefore, we are motivated to compare RAG and LC, evaluating both their performance and efficiency. (중략...) we find that LC consistently outperform RAG in almost all settings (when resourced sufficiently).
요즘 LLM의 max token이 기하급수적으로 늘어나면서, RAG와 Long-Context LLM을 성능과 효율성 면에서 비교하고 싶었다고 함. 그래서 비교를 해 봤더니, RAG를 쓰는 것보다, 그냥 LLM한테 통으로 문서를 줬을 때 오히려 성능이 훨씬 더 좋게 나왔다.
Despite the suboptimal performance, RAG remains relevant due to its significantly lower computational cost. In contrast to LC, RAG significantly decreases the input length to LLMs, leading to reduced costs, as LLM API pricing is typically based on the number of input tokens. Moreover, our analysis reveals that the predictions from LC and RAG are identical for over 60% of queries. For these queries, RAG can reduce cost without sacrificing performance.
그치만 RAG를 쓰면 입력 토큰이 확 줄어들기 때문에 비용 면에서 무척 효율적이라는 장점은 무시할수가 없는데, 연구를 통해 Long Context LLM과 RAG의 답변이 60%가량 일치한다는 사실을 발견했고, 연구진들은 이 정도면 RAG의 답변도 상당히 수준급이라고 생각한 모양. 이 정도면 비용 절감을 고려했을 때 RAG는 여전히 메리트 있다는 것.

[Figure 1]을 보면 LC(Long Context LLM), RAG를 붙인 LLM, 그리고 저자들이 제안하는 Self-Route의 성능과 비용을 최신 LLM 모델별로 비교할 수가 있다. LC가 가장 비싸고 성능이 좋으며, RAG를 붙인 LLM은 싸지만 성능이 LC의 60%정도 수준이고, Self-Route는 비용이 그 중간 어디쯤에 있으며 성능은 LC에 준한다는 것.
Our analysis serves as a starting point, inspiring future improvements of RAG, and as a empirical guide for building longcontext applications using RAG and LC.
본인의 연구가 RAG의 향후 개선을 위한 출발점이자, RAG와 LC를 사용한 long-context 처리에 경험적인 가이드로서의 역할을 하기를 바란다고 함.
2 Related Work
입력 토큰 수가 많을수록 계산 비용이 기하급수적으로 증가하는 Transformer 구조의 한계 - 이를 해결하기 위해 프롬프트 압축, 모델 디스틸레이션, 단계별 모델 사용 등의 방법이 제안되어 왔음. 이후 Retrieval Augmented Generation (RAG)가 제안되었고, 최근에는 RAG의 정확성을 높이기 위해 검색 과정에 교정, 비판, 검증, 적응적 검색을 추가하는 방식이 연구됨.
Long-Context를 처리하는 LLM의 능력 평가를 위해 "LongBench", "∞Bench"와 같은 다양한 벤치마크가 제안되었으며, 이들 벤치마크는 여러 언어와 다양한 데이터셋을 포함해 긴 문맥에서의 모델 성능을 종합적으로 평가하도록 설계됨.
기존 연구에서 RAG와 LC를 비교한 결과, LC 모델이 RAG를 능가한다는 결론을 도출한 바 있음. 이 논문에서는 더 강력한 최신 LLM과 더 긴 문맥을 고려하여 다른 결과를 도출하고자 함. (Self-Route로 그 사이 절충안을 제시하는 것)
3 Benchmarking RAG versus LC
3.1 Datasets and metrics
평가 데이터
- LongBench - 21개의 데이터셋으로 구성, 평균 7천 개의 단어 포함
- ∞Bench - 더 긴 문맥을 포함해 평균 10만 개의 토큰을 포함
- 연구는 영어로 된 실제 데이터를 중심으로 하고, LongBench와 ∞Bench중에서 쿼리가 포함된 데이터셋만 사용하여 총 9개의 데이터셋을 평가에 사용
평가 지표(evaluation metrics)
- open-ended QA tasks - F1
- multichoice QA tasks - Accuracy
- summarization tasks - ROUGE
3.2 Models and Retrievers
- 세 가지 최신 LLM인 Gemini-1.5-Pro, GPT-4O, GPT-3.5-Turbo를 평가에 사용했으며 Retriever는 Contriever와 Dragon을 사용(청킹:300단어/top-5선택)
최신 모델을 써서 굉장히 마음에 든다
3.3 Benchmarking results
- 세 모델 모두에서 LC가 RAG보다 우수한 성능을 보였으며 특히 최신 모델일수록 성능 차이가 두드러졌음 - 이는 최신 LLM이 긴 문맥을 이해하는 능력이 뛰어나다는 것을 보여줌
- 다만, ∞Bench의 두 긴 문맥 데이터셋에서는 GPT-3.5-Turbo에서 RAG가 LC보다 우수한 성능을 보여 예외적인 결과를 보임 - 이는 이 데이터셋이 평균 147,000 단어로 이루어져 있어 모델의 최대 입력 크기를 크게 초과했기 때문
4 Self-Route
4.1 Motivation

X축은 RAG와 LC의 예측 점수 차이(𝑆_{RAG} - 𝑆_{LC})를 나타내며, 0을 기준으로 왼쪽은 LC 점수가 더 높고, 오른쪽은 RAG 점수가 더 높은 경우를 의미
그래프는 X축의 0에 상당히 집중되어 있어, 대다수의 쿼리에 대해 두 모델의 예측이 유사하게 나타난다는 것을 확인할 수 있음 - RAG and LC predictions are highly identical, for both correct and incorrect ones - 맞는 답변도 틀린 답변도 상당히 유사하다고 함
이러한 관찰을 통해 저자들은 대부분의 쿼리에 대해 비용 효율적인 RAG를 활용하고, RAG가 성능을 발휘하지 못하는 소수의 쿼리에만 LC를 적용하는 방식의 필요성을 느낌 - 이를 통해 전체 성능을 유지하면서도 계산 비용을 크게 절감할 수 있을 것으로 기대
4.2 Self-Route
SELF-ROUTE는 LLM 자체가 제공된 문맥을 통해 질문에 답할 수 있는지 스스로 반성하는 방식으로 쿼리를 라우팅 (SELF-ROUTE utilizes LLM itself to route queries based on self-reflection) - Self-Route는 아래 2단계로 작동함.
- RAG-and-Route 단계
- 쿼리와 검색된 청크들을 LLM에 제공하고, 쿼리에 답변할 수 있는지 여부를 예측하도록 요청
- 만약 답변할 수 있다면, 답변을 생성
- 일반적인 RAG와 차이점 : LLM은 다음의 프롬프트를 통해 답변을 거부할 수 있는 옵션을 가짐
(given the option to decline answering)- “Write unanswerable if the query can not be answered based on the provided text”.
- "제공된 텍스트에 기반해 쿼리를 답변할 수 없다면 'unanswerable'을 출력해라."
- 답변이 가능하다고 판단된 쿼리들에 대해서는 RAG 예측을 최종 답변으로 수락함
- 답변이 불가능하다고 판단된 쿼리들에 대해서는 두 번째 단계로 진행하여, 긴 문맥 LLM을 사용하여 최종 예측을 얻습니다. (providing the full context to the long-context LLMs to obtain the final prediction)
- 대부분의 쿼리는 1단계에서 해결 가능 (e.g., 82% for Gemini-1.5-Pro)
- LC 예측 단계
- 1단계에서 "답변 불가"로 분류된 쿼리에 대해서는 긴 문맥 LLM에 전체 문맥을 제공하여 답변을 생성
4.3 Results
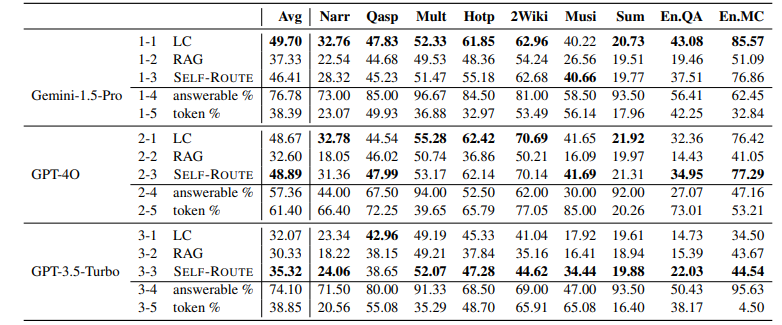
모든 모델이 쿼리의 절반 이상을 RAG로 라우팅했으며, Gemini-1.5-Pro의 경우 응답 가능 비율이 81.74%에 달했음 → 이는 대부분의 쿼리를 LC 없이 RAG로 응답할 수 있음을 의미함함
높은 응답 가능 비율 덕분에 사용된 토큰 수가 크게 감소 (Table 1에서 1-5, 2-5, 3-5 token% 부분 확인)
5 Analysis
5.1 Ablations of k
RAG와 SELF-ROUTE는 쿼리 시 최상위 k개의 텍스트 청크를 검색하여 사용하는데, k 값이 증가할수록 성능이 향상되지만, 비용도 함께 증가함. 해당 연구의 경우 k=5에서 비용이 최소화 되었지만, 맡은 task와 dataset에 따라 이 부분은 직접 실험해야 할듯.
5.3 Different retrievers
연구에서 사용한 검색기 Contriever와 Dragon 모두에 대해 일관된 결과가 나왔음
논문 핵심 요약
- RAG를 쓰되, 답을 찾을 수 없는 경우에는 ‘unanswerable’이라고 답하도록 프롬프팅을 함. (1단계) ⭐
- 1단계에서 ‘unanswerable’을 뱉는 경우는 많지 않음. 모든 모델이 쿼리의 절반 이상을 RAG로 라우팅했으며, Gemini-1.5-Pro의 경우 응답 가능 비율이 81.74%에 달했음.
- 만약 unanswerable이 출력되면? 리트리버로 검색된 context가 아닌 전체 full context를 LLM에게 던짐. (2단계)
- 그러니까 1차적으로는 일반적인 RAG를 쓰고, RAG가 제대로 안 돌아가는 경우에만 2단계로 가는 것
- 요즘 LLM max token이 기하급수적으로 늘어서 이게 가능함. 확인해 보니 사실 RAG를 안 쓰는게 오히려 성능은 더 좋음. 다만 이렇게 하는 이유는 RAG를 썼을 때 input token 수가 확 줄어들면서 cost friendly하기 때문이다.
'Data Science > DL 딥러닝' 카테고리의 다른 글
| 딥러닝 | Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG(2024) 논문 리뷰 (3) | 2024.10.30 |
|---|---|
| 딥러닝 | Improving Retrieval Augmented Language Model with Self-Reasoning(2024) 논문 리뷰 (0) | 2024.10.29 |
| 딥러닝 | RAG(2021) 논문 리뷰 (0) | 2024.08.05 |
| 딥러닝 | 효율적인 파인튜닝에 관한 고찰 - LoRA(2021) 논문 리뷰, peft, unsloth (0) | 2024.08.01 |
| 딥러닝 | RAG 활용 pdf파일 검색 챗봇시스템 구현하기 (4) | 2024.07.24 |












