현재 수강하고 있는 SK플래닛 T아카데미 ASAC 빅데이터 분석 & AI 전문가 양성과정 5기에서 기업 연계 프로젝트를 시작했습니다. 저는 국내 딥러닝 관련 스타트업 기업 팀에 참여해서 딥러닝 프로젝트를 진행하게 되었습니다. 주제는 Table Detection인데요.
이번 기업연계 프로젝트에서 저는 최신 논문을 직접 선정해서 리뷰하고 코드화, 서비스화를 할 예정입니다. 그래서 본격적인 프로젝트에 앞서, Microsoft가 2021년 발표한 PubTables-1m dataset 논문을 읽으면서 Table Detection의 전반적인 발전 흐름과 데이터 구성, 평가 지표에 대해서 짚어보는 시간을 가졌습니다.
논문을 읽으면서 궁금증이 생겨 DETR(Detection Transformer) 논문도 살펴보고, 트랜스포머 허깅페이스를 방문해 객체 탐지 pipeline으로 여러 가지 실험을 해보기도 했는데요. ( 포스팅 : https://smartest-suri.tistory.com/52 ) 이렇게 논문을 기반으로 딥러닝을 연구하고 아이디어를 확장해나가는 것이 되게..... 변태같이 재밌네요.........^__^
딥러닝 | Transformer Huggingface 탐방, pipline 가지고 놀기(객체 탐지)
Transformers지난번에 트랜스포머 논문을 처음부터 끝까지 열심히 읽고 리뷰를 포스팅했었습니다.https://smartest-suri.tistory.com/48 딥러닝 | Attention is all you need - 트랜스포머(2017) 논문 리뷰[참고] 본 포
smartest-suri.tistory.com
이번 PubTables-1m 논문 리뷰는 Table Detection의 발전 과정, 기본 아이디어와 중요 사항 등을 체크할 수 있었던 좋은 시간이었습니다. 그럼 리뷰 들어가겠습니다!
PubTables-1M: Towards comprehensive table extraction from unstructured documents
https://arxiv.org/pdf/2110.00061v3

0. 초록 Abstract

(중략) we develop a new, more comprehensive dataset for table extraction, called PubTables-1M. PubTables-1M contains nearly one million tables from scientific articles, supports multiple input modalities, and contains detailed header and location information for table structures, making it useful for a wide variety of modeling approaches.
(뭔들 아니겠냐만은...) Table detection task 분야에서 당시 가장 큰 문제가 되는 것은 '데이터'였고, 테이블 트랜스포머 팀은 그 해결방안으로 'PubTales-1M'(이하 펍테이블)이라는 데이터셋을 공개하는데요. 펍테이블은 과학 기사에서 추출한 약 1백만 여개의 테이블을 포함하며, multiple input modalities를 지원하는 데이터 셋입니다. 또한 표 구조에서 디테일한 header 정보나 위치 정보를 포함하고 있기 때문에 다양한 목적으로 사용될 수 있습니다.
It also addresses a significant source of ground truth inconsistency observed in prior datasets called oversegmentation, using a novel canonicalization procedure. We demonstrate that these improvements lead to a significant increase in training performance and a more reliable estimate of model performance at evaluation for table structure recognition.
특히 이전 데이터셋에서 흔히 발생하는 과분할, 과세분화(oversegmentation) 문제를 해결했다고 하는데요. 이를 위해 새로운 정규화 절차(canonicalization procedure)를 도입했습니다. 결과적으로 학습이 잘되고 모델 성능이 좋더라!라고,,, 모든 연구 논문의 빼놓을 수 없는 주장을 하고 있습니다. (ㅋㅋㅋㅋ)
Further, we show that transformer-based object detection models trained on PubTables-1M produce excellent results for all three tasks of detection, structure recognition, and functional analysis without the need for any special customization for these tasks.
테이블 트랜스포머 팀은 여기서 약간은 애매한 닉값을 하는데, 트랜스포머를 기반으로 한 object detection 모델을 가지고 테이블 탐지, 구조 인식, 기능 분석이라는 3가지 과업을 아주 잘 수행했다고 합니다. 후에 얘기하겠지만, 그냥 갖다 써서 실험만 했거든요. 데이터만 새로 생성했고 아쉽게도 새로운 모델 구조까지 제안하지는않습니다. 그래서 테이블 트랜스포머,,,,,,라고 명명하긴 조금 짜치지 않나.. 하는 생각을 감히 하기도 했는데요. 그래도 이렇게 새로 구축한 데이터셋으로 학습한 최신 pre-trained model card를 배포하고 있으니 어쨌든 닉값을 하기는 합니다!
배우는 입장에서... 기존의 문제점을 해결하기 위해 새로운 모델 구조를 제안하는 것이 가장 혁신적, 혁명적으로 느껴지긴 합니다. 시간과 노력같은 비용뿐만 아니라 창의적인 아이디어에 재능까지 필요한 일이기 때문이죠. 하지만 때론 이렇게 '데이터의 품질'을 향상시키는 것또한 근본적인 문제 해결의 한가지 방안이 될 수가 있습니다. 어쩌면 모델 구조 변경보다 더 나은 획기적인 성능 향상을 불러 오기도 하죠. 데이터셋 논문을 굳이 리뷰하는 이유도 이와 같은 이유에서입니다. (아, 짜친다고 한거 취소할게요)
1. 서론 Introduction
The problem of inferring a table’s structure from its presentation and converting it to a structured form is known as table extraction (TE). (중략...)
표의 구조를 추론하고 이를 구조화된 형태로 변환하는 문제를 표 추출(Table Extraction, TE)이라고 합니다. TE는 아래와 같이 세 가지 하위 작업으로 구성됩니다.
- 표 탐지 (Table Detection, TD)
- 표 구조 인식 (Table Structure Recognition, TSR)
- 기능 분석 (Functional Analysis, FA)
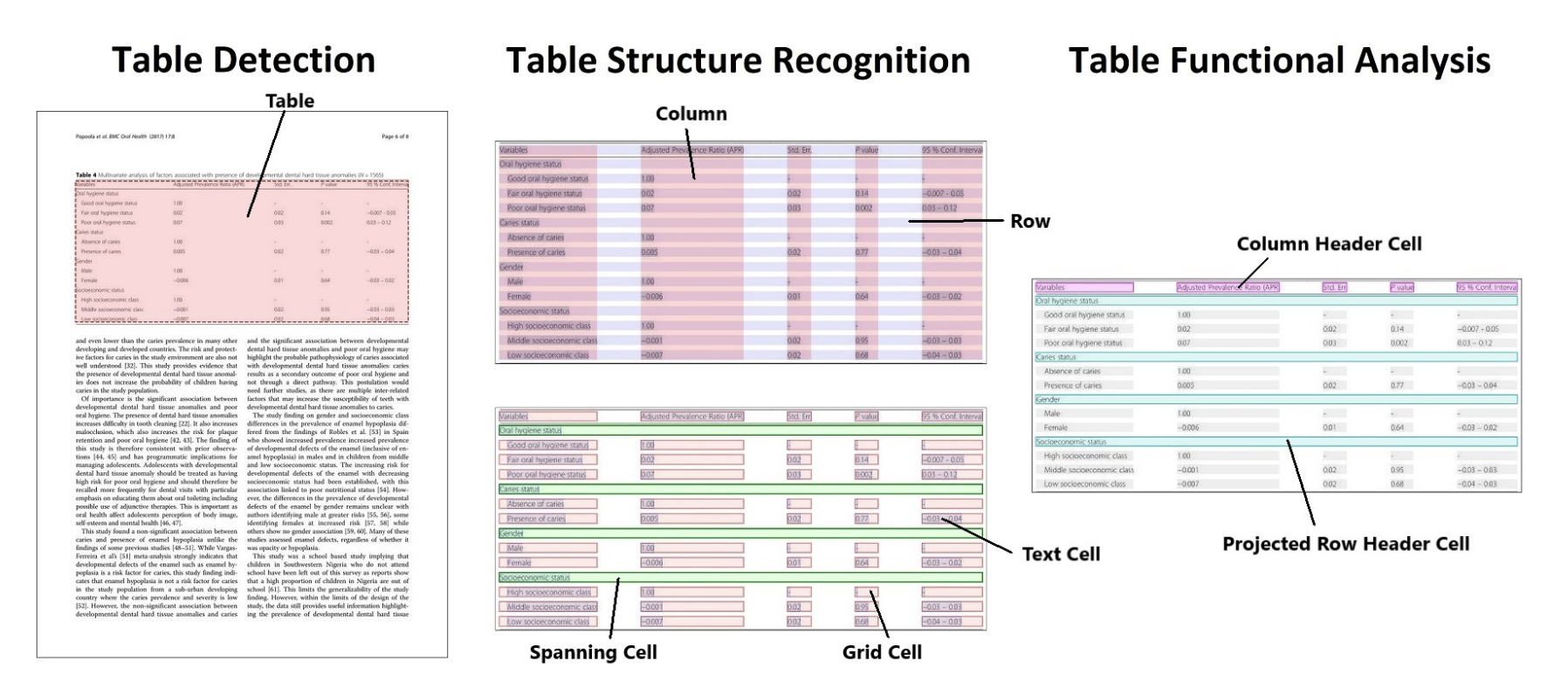
The primary advantage of DL methods is that they can learn to be more robust to the wide variety of table presentation formats. However, manually annotating tables for TSR is a difficult and time-consuming process [7].
딥러닝을 통한 TE는 다양한 표 형식을 탄탄(robust)하게 학습할 수 있다는 장점이 있습니다. 그런데 딥러닝 - 지도 학습(Supervised Learning) - 에는 labeling이 필요하잖아요? TSR(Table Structure Recognition)을 하려면 사람이 일일이 레이블링(annotating)을 해줘야 하는데, 이게 여간 번거로운 게 아니다 보니, 항상 데이터와 관련된 문제점이 존재했던 모양이에요. 아무래도 데이터 확보 자체가 쉽지 않았겠죠.
To overcome this, researchers have turned recently to crowd-sourcing to construct larger datasets [9,22,23]. These datasets are assembled from tables appearing in documents created by thousands of authors, where an annotation for each table’s structure and content is available in a markup format such as HTML, XML, or LaTeX.
문제 해결을 위해서 기존 연구진들은 크라우드 소싱이란 걸 활용해서 더 큰 데이터 세트를 구축했다고 합니다. 이렇게 만들어진 데이터셋은 각 표의 구조와 내용에 대한 annotation을 HTML, XML, LaTeX 같은 마크업 형식으로 제공하는 특징이 있는데요.
* 크라우드 소싱
- 전문가가 풀지 못한 문제를 대중이 풀다
- 군중(crowd)과 아웃소싱(outsourcing)의 합성어
- 비용 효율적이고 빠른 문제 해결을 가능하게 함
- 생산과 서비스의 과정에 소비자 혹은 대중을 참여시켜 더 나은 아이디어, 제품, 서비스를 만들고 수익을 참여자와 공유하고자하는 방법을 칭한다. [참고 : 기획재정부 시사경제용어사전]
While crowd-sourcing solves the problem of dataset size, repurposing annotations originally unintended for TE and automatically converting these to ground truth presents its own set of challenges with respect to completeness, consistency, and quality.
크라우드 소싱이 데이터셋의 사이즈 - 즉, 수량을 확보하는 데에는 도움이 되긴 했는데, 사실 이렇게 얻은 annotation이 애초에는 TE를 목적으로 한 게 아니었고, 그래서 TE용으로 적합하지가 않았습니다.
Another significant challenge for the use of crowdsourced annotations is that these structure annotations encoded in markup often exhibit an issue we refer to as oversegmentation. Oversegmentation occurs in a structure annotation when a spanning cell in a header is split into multiple grid cells.
특히 oversegmentation(과세분화) 문제가 있었습니다. 과세분화는 header(머리글)의 셀이 여러 격자 셀로 나뉘는 경우를 말합니다. 과세분화가 발생해도 보기에는 문제가 없어보입니다만, 딥러닝 모델 학습과 평가를 위한 정답 데이터로 사용될 때는 큰 문제가 될 수 있습니다.

The first issue is that an oversegmented annotation contradicts the logical interpretation of the table that its presentation is meant to suggest. (중략....) would and does lead to ambiguous and inconsistent ground truth, due to there then being multiple possible valid interpretations for a table’s structure, such as in Fig. 3. This violates the standard modeling assumption that there is exactly one correct ground truth annotation for each table.
크게 표의 구조를 올바르게 해석하지 못하는 문제점, 표의 구조에 대해 여러 가지 해석을 내놓는 문제점이 발생할 수 있습니다. 그래서 ground truth가 애매 모호해지고, 1개의 정해진 정답이 있다는 가정을 위반하게 됩니다. 따라서 과세분화된 주석이 포함된 데이터셋은 학습 중 모순된 피드백을 제공하고 평가 시 실제 성능을 과소평가하게 만듭니다.
PubTables-1M (주요 내용)
We introduce a novel canonicalization procedure that corrects oversegmentation and whose goal is to ensure each table has a unique, unambiguous structure interpretation.
- 새로운 canonicalization(정규화) 방법을 통해 oversegmentation(과세분화) 문제를 바로잡고 하나의 테이블에 대해 명확한 하나의 구조 해석을 내놓도록 하는 방법을 보여준다고 합니다.
We show that data improvements alone lead to a significant increase in performance for TSR models, due both to improved training and a more reliable estimate of performance at evaluation.
- (새로운 모델 구조 제안 없이) 좋은 데이터를 쓰는 것만으로도 TSR(Table Structure Recognition) 과업에 얼마나 큰 성능 향상을 보일 수 있는지 보여준다고 합니다.
Finally, we apply the Detection Transformer (DETR) [2] for the first time to the tasks of TD, TSR, and FA, and demonstrate how with PubTables-1M all three tasks can be addressed with a transformer-based object detection framework without any special customization for these tasks.
- Detection Transformer(DETR)을 TD, TSR, FA 과업에 사용한 첫 사례로서, PubTables-1M 데이터랑 DETR이랑 같이 쓰면 얼마나 괜찮은지 보여준다고 합니다. (특별한 모델 변형이나 새로운 구조 제안은 없음 - 데이터셋이 중심이 되는 논문임을 확인)
2. 관련 연구 Related Work
해당 부분은 chat-gpt 4o를 통해 간단히 정리만 하고 넘어가도록 하겠습니다.
구조 인식 데이터셋
- ICDAR-2013: 표 탐지(TD), 표 구조 인식(TSR), 기능 분석(FA)을 모두 다루는 최초의 데이터셋으로, 규모는 작으며 TD와 TSR을 위한 248개의 표와 FA를 위한 92개의 표로 구성됨.
- 대규모 데이터셋: TableBank, SciTSR, PubTabNet, FinTabNet 등은 크라우드 소싱 주석을 사용하여 확장되었으나, 여전히 완전성, 경계 상자, 과세분화 문제를 가지고 있음.
모델링 접근법
- 일반 방법: 객체 탐지, 이미지-텍스트 변환, 그래프 기반 접근법 등이 사용됨.
- 문제점: 포괄적인 훈련 데이터의 부족으로 인해 기존 모델의 성능이 낮음.
- 특화된 방법: 다양한 경우를 처리하기 위해 맞춤형 파이프라인과 전문화된 방법이 사용되었으나, 아직 보편적이고 성능이 높은 솔루션은 존재하지 않음.
3. 데이터셋 PubTables-1M
마이크로소프트는 PubTables-1M 개발을 위해 수백만 개의 공개 과학 기사를 제공하는 PMCOA 코퍼스 선택했습니다. 각 기사는 기사 내용을 시각적으로 보여주는 PDF 파일, 내용 설명과 요소의 계층적 구성을 제공하는 XML 파일로 구성되는데요. 각 표의 내용과 구조는 표준 HTML 태그를 사용합니다.
- 하지만 이것도 역시 애초에 TE 모델링의 레이블로 의도하고 만든 데이터가 아니었기 때문에
- 예를 들어서 두 문서가 같은 표를 가지고 있을 때에 두 문서 간의 직접적인 대응 관계를 알 수도 없고, 문서 내에서 표의 공간적 위치도 특별히 제공되지 않는 한계점이 발생했습니다.
- 또 품질 측면에서도 완벽하지 못했는데
- 예를 들어서 주석이 달린 텍스트 내용이 PDF에 표시된 텍스트 내용과 정확히 일치한다고 보장할 수도 없었고, 가끔 일부 라벨(row header 등)은 아예 주석 처리되지 않기도 했습니다.
논문에서는 이러한 문제점을 어떻게 해결해서 PubTables-1M 데이터셋을 구축했는지 아래와 같이 단계별로 나누어 설명합니다.
[3. 1.] Alignment
PDF와 XML의 텍스트 내용을 일치시켜서 대응관계를 만들어주는 단계

- PDF 문서에 있는 모든 문자에 대해 bounding box 처리를 합니다. ([xmin, ymin, xmax, ymax]의 공간적 위치로 표시)
- XML 태그에서 표의 텍스트를 추출합니다. (예) coffee 추출
- PDF 문서의 bounding box를 합쳐 일치하는 문자열이 있는지 확인하고, 만약 있다면 align을 시켜줍니다. 이 때 Needleman-Wunsch 알고리즘을 사용합니다. (예) 합쳐서 coffee가 되는 부분이 있는지 확인 -> 발견시 align
- 이 과정을 통해 PDF 문서의 텍스트와 XML/HTML에서 추출한 표 내용 텍스트를 서로 pairing(alinging) 하게 됩니다.
Needleman-Wunsh 알고리즘 (간단히)
: 두 시퀀스를 비교하여 최적의 정렬을 찾는 알고리즘으로, 주로 생물유전학에서 사용됨. 본 데이터셋에서는 PDF 문서의 텍스트 시퀀스와 XML/HTML 텍스트 시퀀스를 정렬하여, 두 문서 간의 텍스트 대응 관계를 확립하고 각 텍스트의 위치 정보를 연결하기 위해 사용되었음.
[3. 2.] Completion
Alignment 이후 표 전체와 각 행, 열에 bounding box를 쳐서
spatial annotation(공간 주석)을 '완성(Completion)'하는 단계

- 표 (entire table)
- 표의 경계 상자는 모든 텍스트 셀 경계 상자의 합집합(union)으로 정의됩니다.
- 행 (row)
- 가로 : 각 행의 xmin과 xmax(가로 길이)는 표의 xmin과 xmax로 정의하여 모든 행이 동일한 수평 길이를 갖도록 합니다.
- 세로 : 각 행의 ymin과 ymax(세로 길이)는 해당 행에서 시작하거나 끝나는 모든 셀의 텍스트 셀 경계 상자의 합집합으로 정의됩니다.
- 열 (column)
- 가로 : 각 열의 ymin과 ymax는 표의 ymin과 ymax로 정의하여 모든 열이 동일한 수직 길이를 갖도록 합니다.
- 세로 : 각 열 n의 xmin과 xmax는 해당 열에서 시작하거나 끝나는 모든 셀의 텍스트 셀 경계 상자의 합집합으로 정의됩니다.
- 그리드 셀 (grid cell)
- 그리드 셀은 해당 셀의 행 경계 상자와 열 경계 상자의 합집합(교차 부분 - intersection)으로 정의됩니다. 빈 셀에도 그리드 셀이 정의됩니다.
[3. 3.] Canonicalization
oversegmentation을 바로잡는 단계


canonicalization을 검색하면 '정규화, 표준화, 정상화'정도로 번역이 되는데요. 제가 느끼기에 제일 직관적인 번역은 '정상화'라고 생각했습니다. 논문에 따르면, 간단히 말해 canonicalization이란 특정 조건 하에서 인접한 셀을 병합하는 것을 의미합니다. 아래 사진을 보면 이해가 빠른데요.


이렇게 과세분화된 셀(a)을 서로 병합해서 Canonical(b) - 정상, 표준으로 되돌려놓는 작업을 의미합니다.
알고리즘 파트는 간단히만 정리하고 넘어가도록 하겠습니다.
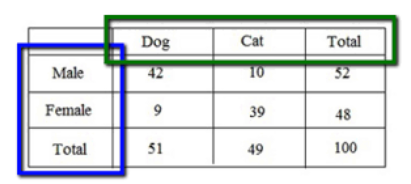
- Wang 모델에 따르면 모든 표의 header(머리말)은 트리 구조를 따릅니다.
- 표의 각 열(column)은 열 헤더 트리의 고유한 리프 노드에, 각 행(row)은 행 헤더 트리의 고유한 리프 노드에 해당합니다.
- 열이나 행 헤더가 부분적으로 주석 처리되거나 주변에 빈 셀이 있는 경우 이를 확장하여 추가적인 열이나 행을 포함시키는 확장 단계를 거칩니다.
- 열 헤더와 행 헤더의 인접한 빈 셀들을 재귀적으로 병합하여 일관성을 유지합니다.
- 마지막으로, 부모 셀과 자식 셀 사이에 빈 그리드 셀이 있는 경우, 빈 셀을 자식 셀과 병합하는 등의 구조 보완 단계를 거칩니다.
[3. 4.] Limitation
3.3. canonicalization의 한계를 언급

- Canonicalization의 목표는 모든 표 구조 주석에 적용 가능한 것이지만, Algorithm 1은 PMCOA 데이터셋의 주석을 위해 특별히 설계된 것으로, 다른 데이터셋의 표를 Canonicalization하려면 추가적인 가정이 필요하며, 이는 이 연구의 범위를 벗어남을 밝힘.
- Canonicalization은 오류 없는 주석을 보장하지 않음.
- Canonicalization 이후에도 남아 있는 문제들은 다음 단계인 3.5. Quality control을 통해 해결하고자 함.
[3. 5.] Quality control
품질 관리를 통해 데이터의 명확성과 일관성을 높이는 단계


- overlapping rows or overlapping columns -> 데이터 폐기 처리
- 원본 XML 주석과 PDF에서 추출한 텍스트 간의 편집 거리를 비교 -> 셀 평균 편집 거리가 0.05를 넘는 표는 오류로 간주하여 폐기
- PDF 텍스트를 정답 데이터로 간주 -> 각 단어가 표 내부의 그리드 셀과 겹치는 비율이 0.9 미만인 표 폐기
- 객체 수가 100개를 초과하는 표 폐기
- PubTables-1M은 셀 수준에서 주석을 검증하여 일관성을 보장하는 최초의 데이터셋임을 강조
[3. 6.] Dataset statistics and splits
데이터 통계와 수를 나타내는부분으로, 자세한 리뷰 생략
- TSR 데이터셋
- 훈련용 표: 758,849개
- 검증용 표: 94,959개
- 테스트용 표: 93,834개
- TD 데이터셋
- 훈련용 페이지: 460,589개
- 검증용 페이지: 57,591개
- 테스트용 페이지: 57,125개
4. 제안 모델 Proposed Model
본 논문은 표의 구성 성분을 6개의 객체 클래스로 분류해서 이미지에서 찾아낸 다음 경계 상자로 표시하는 모델링을 수행했습니다. 6개의 객체 클래스는 아래와 같습니다.
- table 표 전체
- table row 행
- table column 열
- table column header 행 헤더(머리말)
- table projected row header 열 헤더(머리말)
- table spanning cell 확장 셀
- The intersection of each pair of table column and table row objects can be considered to form a seventh implicit class, table grid cell. -> 모든 행렬의 교차 부분은 'grid cell'이라는 7번째 추가 object로 간주할 수 있음

To demonstrate the proposed dataset and the object detection modeling approach, we apply the Detection Transformer (DETR) [2] to all three TE tasks. We train one DETR model for TD and one DETR model for both TSR and FA. For comparison, we also train a Faster R-CNN [16] model for the same tasks.
TD, TSR+FA 2가지 과업에 DETR을 이용해 학습을 시키고, Faster-R CNN과 성능을 비교합니다.
All models use a ResNet-18 backbone pretrained on ImageNet with the first few layers frozen. We avoid custom engineering the models and training procedures for each task, using default settings wherever possible to allow the data to drive the result.
- 모든 모델은 ResNet-18 사전학습 백본 사용, 초반의 몇 레이어는 freeze
- 모델 커스터마이징을 안 한 이유 : 데이터가 결과를 주도하도록 하기 위해 (이해는 하지만 개인적으로 아쉬운 부분)
5. 실험 Experiments


Faster R-CNN, DETR 성능을 비교해 본 결과 DETR의 성능가 더 좋았으며, Canonical 데이터의 중요성을 강조하고 있습니다.
평가 지표 (metrics)
For assessing TSR performance, we report the table content accuracy metric (AccCont), which is the percentage of tables whose text content matches the ground truth exactly for every cell, as well as several metrics for partial table correctness, which use different strategies to give credit for correct cells when not all cells are correct. For partial correctness, we use the F-score of the standard adjacent cell content metric [5] and the recently proposed GriTS metrics [19].
- TSR 성능 평가 : 각 셀의 텍스트 내용이 정답과 정확히 일치하는 표의 비율 AccCont
- 부분적 정확도 평가 : 표준 인접 셀 내용 지표의 F-score와 최근 제안된 GriTS 지표
GriTS

GriTS(이하 그리츠) 수식을 확인해 보니, F-score와 같은 것이라고 해석해도 무방할 것 같습니다. Image Segmentation에서 자주 사용되는 Dice Score와도 일맥상통하구요.
Compared to other metrics for TSR, this formulation better captures the two-dimensional structure and ordering of cells of a table when comparing tables.
다른 지표랑 비교했을 때 그리츠는 표를 비교할 때 표의 이차원 구조와 셀의 순서를 더 잘 반영하고, 기타 등등 여러 장점이 있다고 하네요.
AccCont
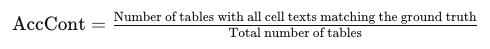
AccCont는 논문에 수식이 따로 없길래, gpt 4o한테 수식을 써달라고 했더니, 이렇게 써주네요 (ㅋㅋㅋㅋㅋ) 나름 직관적입니다. 일반적인 Accuracy(정확도) 개념과 거의 유사하다고 봐도 무방할 것 같습니다.
6. 결론 Conclusion
- 비정형 문서의 표 추출을 위한 새로운 데이터셋인 PubTables-1M을 소개
- 과세분화 문제를 해결하기 위해 새로운 정형화 절차를 제안, 이를 통해 모델 성능이 크게 향상됨을 입증
- DETR을 사용하여 표 추출 작업에서 최첨단 성능을 달성할 수 있음을 보임
(7장 Future Work는 생략하겠습니다.)
마무리
https://github.com/microsoft/table-transformer
GitHub - microsoft/table-transformer: Table Transformer (TATR) is a deep learning model for extracting tables from unstructured
Table Transformer (TATR) is a deep learning model for extracting tables from unstructured documents (PDFs and images). This is also the official repository for the PubTables-1M dataset and GriTS ev...
github.com

테이블 트랜스포머 팀 최신 뉴스(깃허브)에 따르면, PubTables-1M과 다른 데이터셋을 가지고 학습한 pre-trained model TATR-v1.1을 공개했다고 밝히고 있습니다. (2023년 8월 22일자)
https://huggingface.co/bsmock/TATR-v1.1-All
bsmock/TATR-v1.1-All · Hugging Face
Model Card for TATR-v1.1-All This repo contains the model weights for TATR (Table Transformer) v1.1, trained on the PubTables-1M and FinTabNet.c datasets, using the training details in the paper: "Aligning benchmark datasets for table structure recognition
huggingface.co
해당 허깅페이스 페이지에 가면 모델 카드를 확인하실 수 있는데요.

추후 해당 모델을 사용해서 직접 Table Detection을 실행해본 뒤 추가 포스팅을 하도록 하겠습니다.
이번 테이블 트랜스포머 논문 리뷰를 통해 Table Detection을 수행할 때 필요한 데이터의 특성, 레이블링 방법, 생소한 평가지표까지 전체적인 흐름을 파악할 수 있었습니다. 본 논문은 2021년 발표된 '데이터셋' 중심 논문인 만큼, 다음 번에는 새로운 '모델 구조'를 제안하는 최신 논문을 리뷰하고 코드로 구현하는 작업을 수행해보고자 합니다.
수리링의 Table Detection 정복 과정을 지켜봐 주세요!

감사합니다 :-)
'Data Science > DL 딥러닝' 카테고리의 다른 글
| 딥러닝 | BERT(2019) 논문 리뷰 (7) | 2024.07.22 |
|---|---|
| 딥러닝 | 트랜스포머 positional encoding 코드 구현 (문제 해결) (0) | 2024.07.06 |
| 딥러닝 | Transformer Huggingface 탐방, pipline 가지고 놀기(객체 탐지) (1) | 2024.07.02 |
| 딥러닝 | 평가지표 dice score 범위가 [0, 1]을 벗어나는 경우 (오류 해결) (1) | 2024.07.02 |
| 딥러닝 | U-Net(2015) 논문 리뷰 02 _ PyTorch 코드 구현 (1) | 2024.06.30 |




































