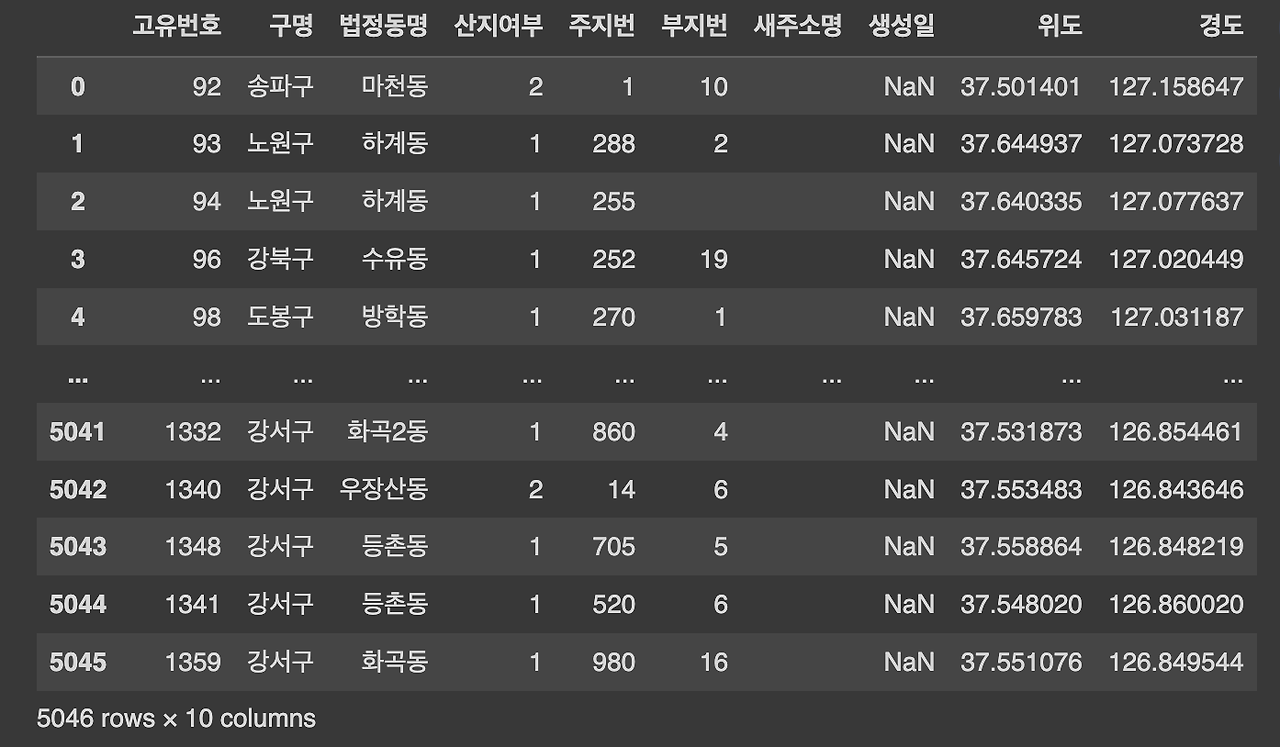
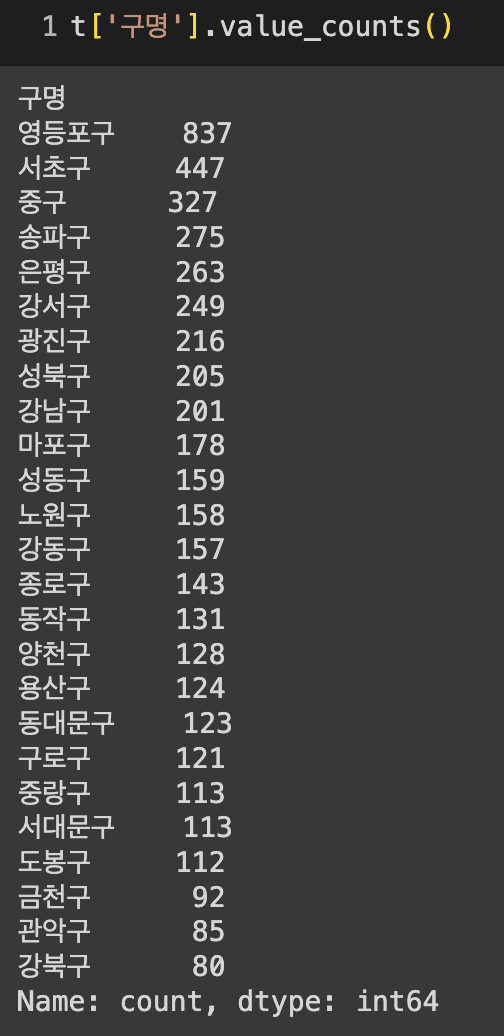
지난 글에서 서울특별시 공중화장실 공중데이터를 판다스 데이터프레임으로 만들고 간단히 정제작업을 해 보았는데요. 정제한 데이터프레임을 가지고 태블로를 이용해서 아주 간단히만 시각화 작업을 진행해 보았습니다.

대시보드 구성 방법
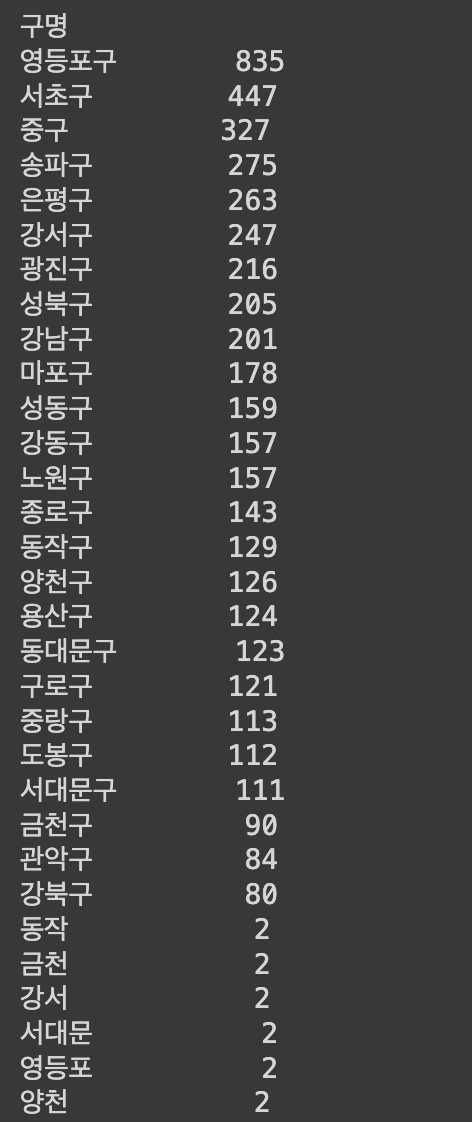
- 서울시의 25개 구별 공중화장실 수 합계를 계산하여 그 수를 비교할 수 있도록 시각화했습니다.
- 대시보드의 왼쪽에는 지도를 배치하여 화장실의 수를 원의 크기와 색깔로 직관적으로 파악할 수 있도록 구성했습니다
- 지도를 확대하면 보이지 않는 레이블을 모두 확인할 수 있어요.
- 화장실 수가 많을수록 원의 크기가 큽니다.
- 화장실 수가 많을수록 원의 색깔이 진합니다.
- 대시보드의 오른쪽에는 가로막대그래프를 배치하여 수치별로 좀더 직관적인 비교가 가능하도록 구성했습니다.
- 오른쪽의 비교 파라미터를 이용해서 비교선을 100단위로 조절하면서 이동시킬 수 있어요.
- 비교선을 움직이면서 비교선을 기준으로 색깔이 바뀌는 것을 확인할 수 있어요.
지하철
지하철
public.tableau.com
클릭하시면 태블로 퍼블릭 웹사이트에서 인터렉티브하게 직접 결과를 조절해 보실 수 있습니다.
<시각화 이후 생각해볼만한 것들>
1. 구별 화장실 수와 구별 면적의 관계는 어떻게 되는가?
2. 구별 화장실 수와 지하철 역의 개수의 상관관계가 있는가?
3. 구별 화장실 수와 구별 인구 수의 관계는 어떻게 되는가? 인구와 구별 화장실 총 수는 비례하는가?
4. 서울특별시 구별 장애인 화장실 데이터를 따로 구할 수 있는가? 구할 수 있다면, 전체 화장실과 장애인 화장실의 비율을 비교해 보자.
5. 상업 단지와 화장실 수의 상관관계가 있는가?
6. 관광 구역과 화장실 수의 상관관계가 있는가?
7. 공공화장실 중에서 지하철 역 화장실의 개수를 특정할 수 있는가? 있다면 그 비율은 어떻게 되는가?
8. 지하철 역 화장실 개수를 구할 수 있다면, 지하철 노선별 유동인구 데이터와 병합하여 화장실의 갯수가 적절하게 비치되어 있는지 비교해보자.
여기까지입니다 :-) 좀더 생각해볼 수 있을것 같지만 본격적인 개인 EDA 프로젝트 준비를 위해서 이번엔 이정도로 간단히만 포스팅을 마치려고 합니다. 쉽고 짧은 작업이었지만 맘에드는 공공데이터를 구하고, 정제하고, 시각화 후 생각해볼거리 도출까지 은근 시간이 걸렸네요. 다음엔 더 능숙하고 멋진 프로젝트를 가져와서 공유해보겠습니다. 감사합니다. :)
(+) 판다스 데이터프레임 CSV파일로 내보내기 한 후 태블로에 불러온 과정
t.to_csv("toilet_df.csv")
먼저 to_csv() 메소드를 통해 간단하게 csv파일로 내보내기를 해주었습니다. 저는 구글 코랩에서 실습을 진행했습니다.

구글 코랩의 왼쪽 파일메뉴에서 간단하게 바로 다운로드를 해서 다운로드 폴더에 넣어 주었는데요. 로컬 환경에 따로 다운로드하지않고 태블로 퍼블릭 환경에서 구글 드라이브를 연동해서 바로 오픈해도 됩니다.
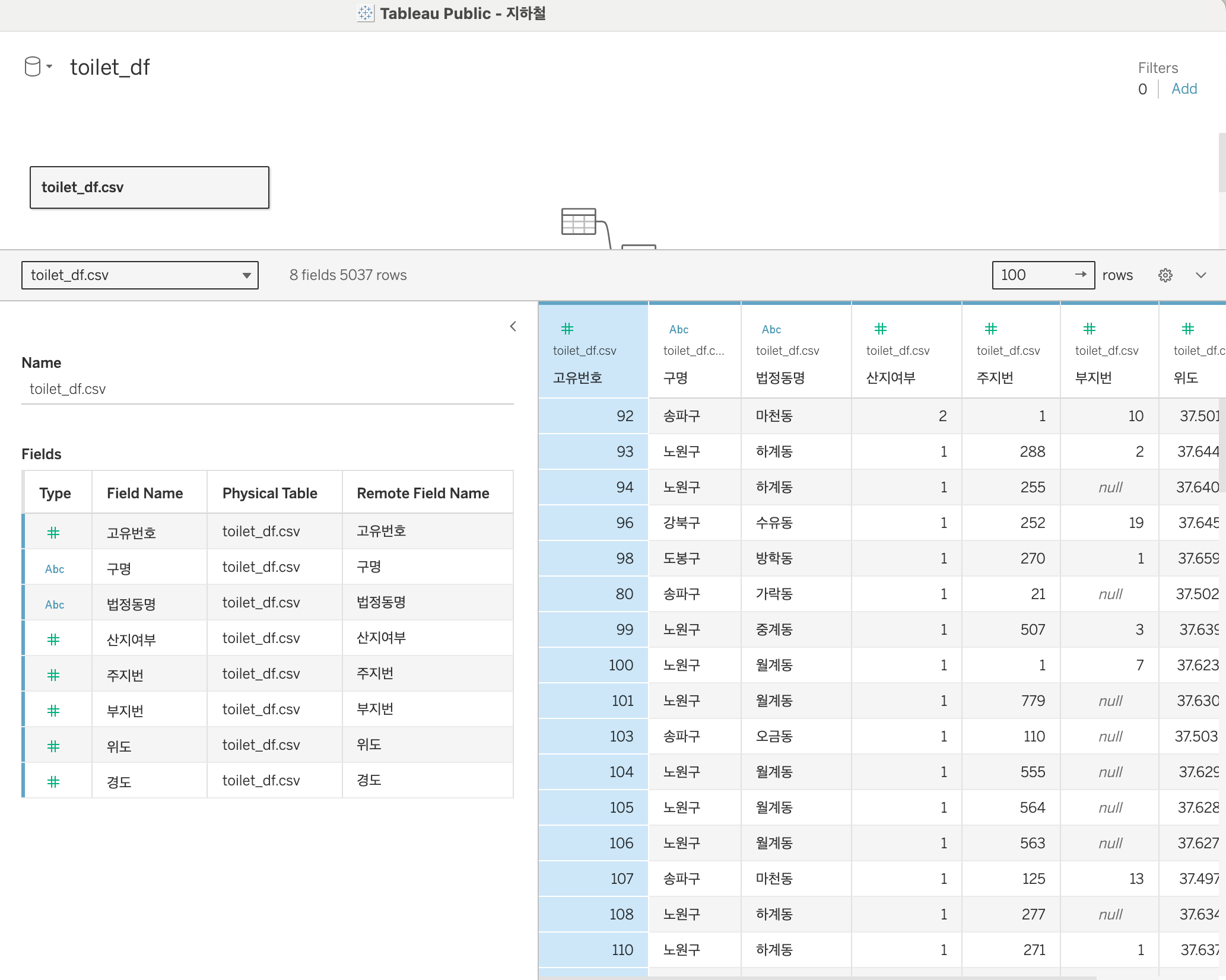
태블로 퍼블릭 프로그램을 실행하고 로컬 환경에 다운로드한 toilet_df.csv 파일을 오픈했습니다.
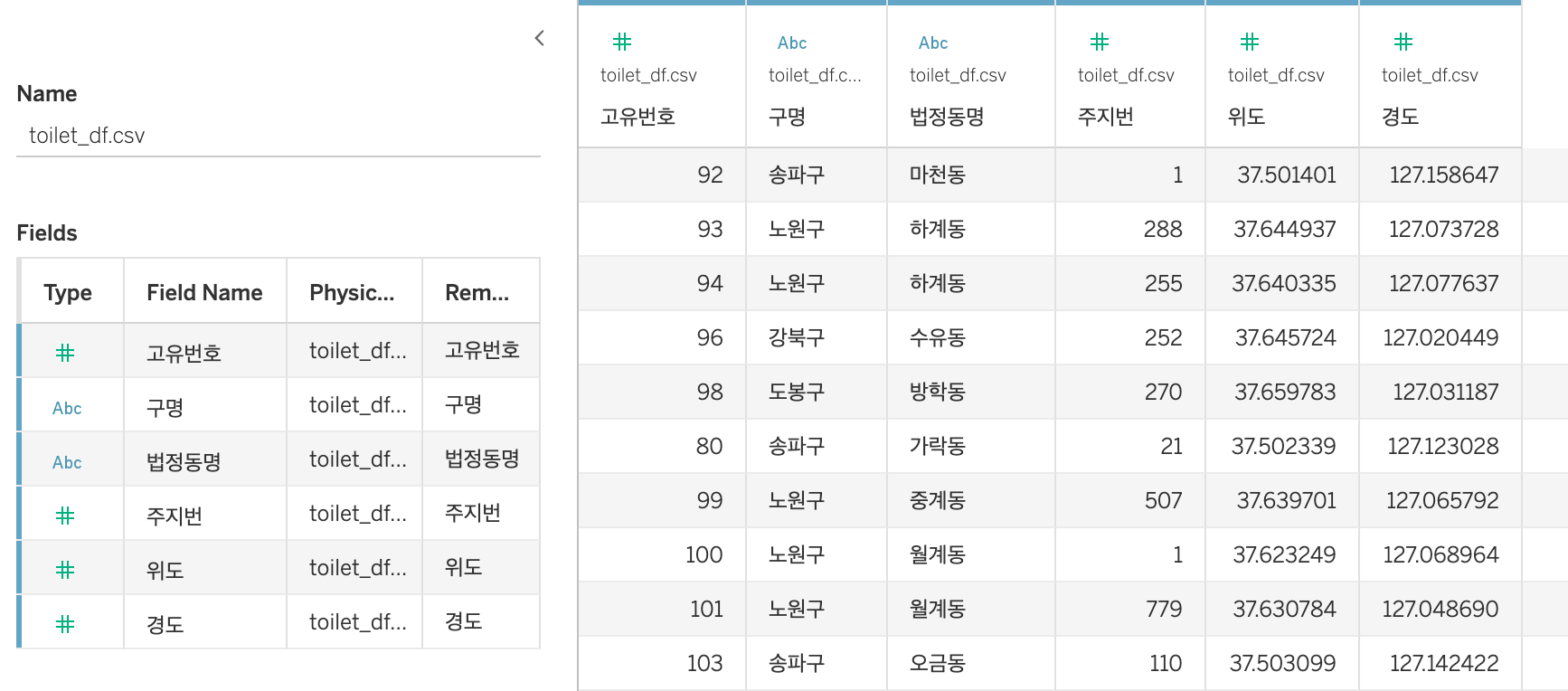
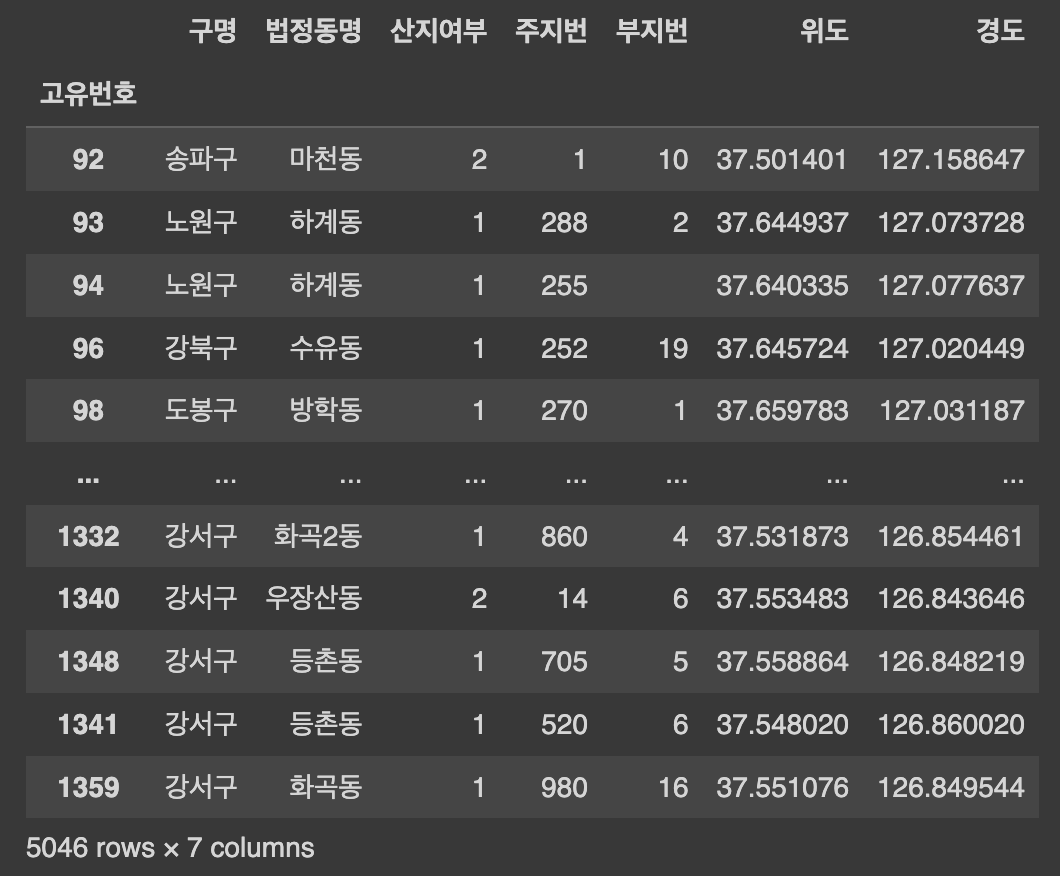
따로 사용하지 않을 예정인 산지, 부지번 컬럼은 숨기기(Hide) 해주었습니다. 이후 시트 2개에서 작업을 하고 대시보드 1개에서 두개를 합쳐주는 방식으로 간단히 끝을 내주었습니다.
'Data Science > ML 머신러닝' 카테고리의 다른 글
| ML | 캐글 Kaggle 신용카드 데이터 EDA + 모델링 실습 (0) | 2024.05.10 |
|---|---|
| ML | 파이썬 scikitlearn XGBoost 래퍼 클래스 - XGBoostClassifier (0) | 2024.05.08 |
| ML | 파이썬 XGBoost API 사용하여 위스콘신 유방암 예측하기 (0) | 2024.05.08 |
| EDA | 서울특별시 공중화장실 01 _ pandas를 이용한 공공데이터 정제, 전처리하기 (1) | 2024.04.16 |
| 웹크롤링 | 연금복권720+ 당첨 데이터 분석해보기 (파이썬 requests, BeautifulSoup) (1) | 2024.04.13 |