(*) 본 논문 리뷰 포스팅은 수리링이 직접 BERT 논문 원문을 처음부터 끝까지 읽고 작성했습니다. 포스팅을 참고하시는 경우 반드시 출처를 밝혀주시기를 미리 부탁드립니다. 감사합니다.

https://arxiv.org/pdf/1810.04805
본 논문 리뷰는 BERT 원문을 직접 읽고 버트의 핵심 아이디어와 구조에 대해서 살펴봅니다. 구체적인 실험과 학습 결과, 성능 지표 등에 대한 리뷰는 생략하는 점 양해 바랍니다.
초록 Abstract

- 트랜스포머의 인코더는 Recurrent(순차) 구조 없이 입력을 '통으로' 받습니다. 따라서 입력 시퀀스의 각 위치에서 왼쪽, 오른쪽 양방향(Bidirectional) 문맥을 모두 고려할 수 있습니다.
- 이와 반대로 디코더는 마스킹을 통해 현재 시점까지의 토큰들만을 참조하는 단방향(unidirectional)으로 작동합니다.
BERT는 Bidirectional Encoder Representations from Transformers의 약자로, 이름에서도 알 수 있듯 트랜스포머의 '인코더'에만 집중한 모델입니다. 따라서 양방향(Bidirectional) 문맥을 고려하여 언어를 잘 이해하도록 학습(pre-train)이 되었습니다.
이 때 BERT의 R(Representation)은 무슨 의미일까요? NLP 태스크에서 자주 언급되는 Word Representation은 인간의 언어를 다차원 벡터로 표현하여 컴퓨터가 이해할 수 있게 하는 작업이나 그 결과물을 의미합니다. BERT의 R(Representation) 역시 입력된 단어나 문장의 의미를 벡터 형태로 표현하여 모델이 해당 언어의 문맥과 의미를 이해할 수 있도록 하는 작업을 포함합니다. 본 포스팅에서는 따로 '표현'이라는 한국어로 직역하지 않고 그대로 reperesentation으로 표기할 것임을 미리 밝히겠습니다.
BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inferences, without substantial task-specific modifications.
초록에서는 BERT가 모든 레이어에서 deep한 bidirectional representations을 학습하기 위해 고안되었으며, 사전 학습이 완료된 BERT 모델에 딱 1개의 output layer만 추가해서 파인튜닝이 가능할 정도로 '파인튜닝이 쉽고 용이하다'고 강조하고 있습니다. 이를 통해 QA(Question-Answering)이나 Langue Inferences과 같은 다양한 작업을 수행할 수 있는 것이죠 :-)
1 서론 Introduction
There are two existing strategies for applying pre-trained language representations to downstream tasks: feature-based and fine-tuning. .... (중략) they use unidirectional language models to learn general language representations. We argue that current techniques restrict the power of the pre-trained representations, especially for the fine-tuning approaches.
사전 학습된 언어 representation을 다운스트림 작업에 적용하는 두 가지 기존 전략으로는 특징(feature-based) 기반 접근법과 파인튜닝 접근법이 있습니다.
- 딥러닝에서 다운스트림 태스크(downstream tasks)는 특히 사전 학습(pre-trained)된 모델에 Transfer Learning/Fine Tuning을 통해 수행하고자 하는 구체적인 하위 작업을 뜻합니다. 예를 들어, 자연어 처리 분야에서는 텍스트 분류, 감정 분석, 명명된 개체 인식(NER), 질문 응답(QA) 등이 다운스트림 작업에 해당할 수 있겠죠.
- Feature-based 방법은 사전 학습된 언어 모델을 사용하여 텍스트 데이터를 처리한 후, 그 결과로 나온 특징(feature) 벡터를 다른 기계 학습 모델에 입력으로 사용하는 방법입니다. 따라서 전체 과정이 하나의 모델로 통합되어 한 번에 학습되고 예측되는 end-to-end 방식이라고 볼 수 없습니다. (대표적으로 ELMo)
- Fine-tuning 방법은 사전 학습된 언어 모델을 특정 작업에 맞게 추가 학습시켜 사용하는 방식으로, 전체 과정을 하나의 모델로 통합하여 end-to-end 방식으로 학습과 예측을 수행합니다. (대표적으로 OpenAI GPT)
논문에서는 ELMo나 GPT같은 기존의 모델이 representation을 학습하기 위해 unidirectional - 단방향 언어모델을 사용하면서 사전 학습된 representation을 온전히 활용하지 못했고, 그래서 특히 파인튜닝 단계에서 문제가 많았다고 지적합니다.
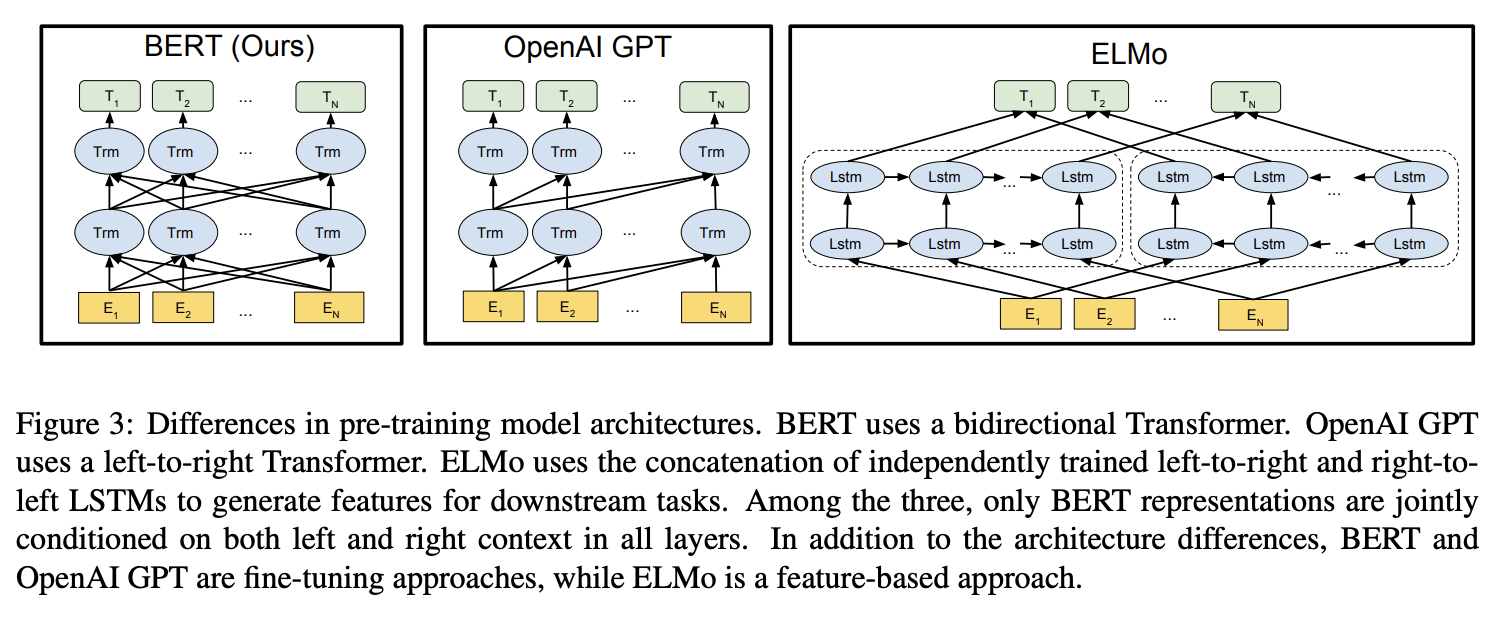
The major limitation is that standard language models are unidirectional, and this limits the choice of architectures that can be used during pre-training. For example, in OpenAI GPT, the authors use a left-to-right architecture, where every token can only attend to previous tokens in the self-attention layers of the Transformer (Vaswani et al., 2017). Such restrictions are sub-optimal for sentence-level tasks, and could be very harmful when applying fine-tuning based approaches to token-level tasks such as question answering, where it is crucial to incorporate context from both directions.
단방향 모델은 문맥의 일부만을 참조할 수 있습니다. 예를 들어, OpenAI GPT는 디코더 특화 모델로, 자신의 이전 토큰까지만 참조할 수 있는 좌->우 단방향 아키텍처를 사용하여 출력을 생성하는 특징이 있습니다.
- 예를 들어 GPT가 QA(Question-Answering) 작업을 수행한다고 해 봅시다. QA 작업에서는 질문(Q)을 받아 문서(Context)의 어느 부분이 정답에 해당하는지를 알아내야 하고, 이 과정에서 정답의 앞뒤 문맥이 모두 중요하게 고려되어야 합니다. 하지만 GPT는 문서를 왼쪽->오른쪽 단방향으로만 읽기 때문에, 정답의 뒷부분에 있는 중요한 정보를 참조하기 어렵습니다. 따라서 QA 작업을 위한 fine-tuning을 수행할 때 전체 문맥을 이해하는 데 어려움이 있을 것이고, 그만큼 정확한 답을 찾아내도록 fine-tuning이 어려울 수 있다는 것이죠.
대놓고 OpenAI 저격하는거 꿀잼...
In this paper, we improve the fine-tuning based approaches by proposing BERT: Bidirectional Encoder Representations from Transformers. (중략) The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-to-right language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer.
In addition to the masked language model, we also use a “next sentence prediction” task that jointly pre-trains text-pair representations.
본 논문은 BERT를 통해 파인튜닝 기반 접근법을 개선하는데, 대표적으로 "MLM(Masked Language Model)"을 도입합니다.
- 입력 토큰에서 무작위로 마스킹을 한 다음,
- '양방향' 문맥을 고려하여 마스킹한 부분을 예측하도록 학습을 시킵니다.
- deep한 스트럭처를 실현합니다.
또한 BERT는 MLM 외에도 텍스트 쌍 표현을 공동으로 사전 학습하는 "NSP(Next Sentence Prediction)"를 함께 사용합니다.
3 버트 BERT
BERT는 크게 pre-training과 fine-tuning의 2스텝으로 이루어져 있는데요.
During pre-training, the model is trained on unlabeled data over different pre-training tasks.
For finetuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models, even though they are initialized with the same pre-trained parameters.
- 우선 버트는 라벨이 따로 없는 데이터로 '비지도 학습'을 통해 사전 학습(pre-training)을 합니다.
- 다음 파인튜닝 단계에서는 라벨이 있는 데이터로 '지도 학습'을 하면서 사전에 학습한 파라미터 전체를 업데이트하게 됩니다. 나의 다운스트림 태스크가 무엇이냐에 따라서 사용하는 데이터도 다를거고, 당연히 그에 따라 업데이트 되는 파라미터 값도 달라지겠죠.
A distinctive feature of BERT is its unified architecture across different tasks. There is minimal difference between the pre-trained architecture and the final downstream architecture.
BERT는 초록에서 살펴본 바와 같이 fine-tuned with just one additional output layer : 단 하나의 아웃풋 레이어만 추가해서 파인튜닝을 합니다. 그래서 다운스트림 태스크에 따른 파인튜닝 전후에 구조 차이가 거의 없는 편이고, 그만큼 다양한 NLP 작업에서 일관된 성능을 발휘할 수 있는 장점이 있습니다.
We primarily report results on two model sizes: BERT BASE (L=12, H=768, A=12, Total Parameters=110M) and BERT LARGE (L=24, H=1024, A=16, Total Parameters=340M).
버트에는 크게 두가지 사이즈의 모델이 있어요.
- BERT BASE
- 768차원(H)을 12개의 벡터로 나눠서(64차원씩) 멀티헤드 어텐션수행(A)
- 인코더 블록 총 12번 반복(L)
- BERT LARGE
- 1024차원(H)을 16개의 벡터로 나눠서(64차원씩)멀티헤드 어텐션수행(A)
- 인코더 블록 총 24번 반복(L)
바닐라 트랜스포머가 512차원을 8개의 벡터로 나눠서(64차원씩) 멀티헤드 어텐션 수행, 인코더 블록을 총 6번 반복(후 디코더를 사용)했던 것과 비교하면 버트는 그보다 훨씬 더 deep한 인코더를 구성했다고 볼 수 있고, 이로 인해 버트는 문맥 정보를 더욱 깊이 학습하게 되어 다양한 NLP작업에서 높은 성능을 발휘할 수 있게 됩니다. 논문 초록에서 BERT가 deep한 bidirectional(both left and right) representations을 학습하도록 고안되었다고 한 이유를 여기서 찾아볼 수 있겠네요.
BERT BASE was chosen to have the same model size as OpenAI GPT for comparison purposes. Critically, however, the BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
논문에서 계속 OPENAI GPT와의 비교를 하면서 우리는 양방향이고 쟤네는 단방향이라 우리가 더 좋다!는 뉘앙스의 문장이 빈번하게 나오는데요. (ㅋㅋㅋㅋ) BERT와 GPT는 애초에 타겟하는 목적이 다르기 때문에, 무엇이 더 좋고 나쁘다고 비교할 문제는 아닌것 같고, 저는 각자가 목적에 맞는 구조를 알맞게 잘 선택한 것으로 이해했습니다.

To make BERT handle a variety of down-stream tasks, our input representation is able to unambiguously represent both a single sentence and a pair of sentences (e.g., h Question, Answeri) in one token sequence. We use WordPiece embeddings (Wu et al., 2016) with a 30,000 token vocabulary.
BERT는 fine-tuning을 통해 다양한 다운스트림 task를 수행할 수 있도록 input representation으로 하나의 문장(a single sentence)을 받을 수도 있고, 한 쌍의 문장(a pair of sentence)을 받을 수도 있도록 설계되었습니다. 토큰 임베딩을 위해서는 30,000개의 토큰 어휘를 가진 WordPiece 임베딩(Wu et al., 2016)을 사용하구요.
The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks. Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways. First, we separate them with a special token ([SEP]). Second, we add a learned embedding to every token indicating whether it belongs to sentence A or sentence B.
모든 시퀀스는 다음과 같이 구성되어 있습니다.
- 첫 번째 토큰 : 분류 작업에 필요한 토큰 [CLS]
- 첫 번째 문장(A) 토큰
- 가운데 [SEP] 토큰 : 두 문장을 구분하는 역할
- 두 번째 문장(B) 토큰
- 마지막 [SEP] 토큰 : 시퀀스의 끝을 알려주는 역할
이 때 각 토큰이 문장 A에 속하는지 B에 속하는지 구별할 수 있는 Segment Embeddings 작업이 추가 수행됩니다. 아래 Figure 2에서 이 부분을 조금더 시각화해서 살펴볼 수 있습니다.

트랜스포머가 Token Embedding과 Positional Encoding 정보를 더해서 입력값을 완성하는 것에서 나아가 BERT는 Segment Embeddings까지 한 번 더 더해주게 됩니다. [SEP] 토큰을 기준으로 각 토큰이 문장 A에 속하는지 B에 속하는지를 구분하는 것이죠.
이 작업은 이어서 자세히 살펴볼 문장 예측(NSP)을 위해 사용됩니다.
3-1. Pre-training BERT
BERT의 Pre-training의 핵심 unsupervised-task, MLM과 NSP를 살펴봅시다.
[1] Masked LM(MLM) : 마스킹된 언어 모델
In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens. (중략) In all of our experiments, we mask 15% of all WordPiece tokens in each sequence at random. In contrast to denoising auto-encoders (Vincent et al., 2008), we only predict the masked words rather than reconstructing the entire input.
MLM은 deep bidirectional representation을 가능하게 하기 위해서 input tokens의 15%를 무작위로 랜덤 마스킹하고, 그 부분을 예측하도록 학습을 시키는 과정을 의미합니다.
Although this allows us to obtain a bidirectional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To mitigate this, we do not always replace “masked” words with the actual [MASK] token.
The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time.
그런데, 문제가 있습니다. 우리가 downstream 태스크를 위해 BERT를 파인튜닝할 때, 파인튜닝용으로 준비한 데이터에 15%를 지켜 마스킹이 준비되어있기는 아무래도 어렵겠죠. 따라서 pre-training data와 fine-tuning 데이터가 서로 일치하지 않는 문제점이 발생할 수가 있습니다.
- 따라서 버트는 input tokens의 15%를 무작위로 선택한 다음, 선택된 i번째 토큰을
- 80% 확률로 진짜 마스크 토큰([MASK])으로 대체합니다. 예를 들어 '감자'를 [MASK]로 대체하고 이를 예측하도록 학습시킵니다.
- 10% 확률로 무작위 토큰으로 대체합니다. 예를 들어 '감자'를 '생선'으로 바꾸어 버립니다.
- 10% 확률로 원래 토큰을 그대로 둡니다. 예를 들어 '감자'를 그냥 그대로 '감자'로 둡니다.

The advantage of this procedure is that the Transformer encoder does not know which words it will be asked to predict or which have been replaced by random words, so it is forced to keep a distributional contextual representation of every input token.
부록에 따르면 이러한 방법을 사용함으로써 인코더가 예측할 단어나 무작위로 대체된 단어를 알지 못해, 모든 입력 토큰의 문맥을 이해하도록 상황이 강제되는 이점이 있다고 합니다. 즉, 항상 [MASK] 토큰에만 의존하지 않고 문맥을 기반으로 예측할 수 있는 능력을 기르고, 파인튜닝 데이터에 [MASK] 토큰이 등장하지 않아도 문제가 없도록 설계한 것입니다.
[2] Next Sentence Prediction(NSP) : 다음 문장 예측
Many important downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling.
질의응답(QA)나 자연어 추론(NLI) 같은 작업에서는 '두 문장의 관계'를 파악할 필요성이 있습니다. 그런데 기존의 language modeling은 주로 다음 단어를 예측하거나, 문장 내에서 단어의 순서와 패턴을 학습하는 등의 작업을 중점적으로 수행합니다. 두 문장 사이의 관계를 파악하는 것과는 거리가 멀죠. 그래서 BERT는 QA나 NLI같은 다양한 downstream task를 수행할 수 있도록, 모델이 두 문장 사이의 관계를 파악할 수 있도록 pre-train을 시켰습니다.
In order to train a model that understands sentence relationships, we pre-train for a binarized next sentence prediction task that can be trivially generated from any monolingual corpus.
BERT에서 NSP(Next Sentence Prediction)는 입력 시퀀스 내에서 문장 A와 문장 B가 서로 연속된 문장인지 아닌지를 판단하는 이진 분류(binary classification) 작업입니다. 주어진 두 문장이 실제로 연속된 문장(True)인지, 아니면 무작위로 선택된 다른 문장(False)인지를 예측합니다. NSP는 monolingual corpus(단일 언어 코퍼스) - 한 가지 언어로 된 텍스트 데이터 집합 내에서 학습이 가능합니다.
이 때, 앞서 살펴본 [CLS] 토큰이 바로 다음 문장 예측(NSP)에 사용되는 토큰이구요. MLM의 경우 입력 시퀀스 내에서 선택된 15%의 토큰이 80%의 확률로 마스킹되지만, NSP의 경우 모든 입력 시퀀스에 대해서 100% 수행이 됩니다.
Specifically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext). As we show in Figure 1, C is used for next sentence prediction (NSP).5 Despite its simplicity, we demonstrate in Section 5.1 that pre-training towards this task is very beneficial to both QA and NLI.
- 50%의 입력 시퀀스는 실제로 문장 A와 문장 B가 연속된 문장으로 구성되며, 레이블 IsNext(True)를 가집니다.
- 나머지 50%의 입력 시퀀스는 무작위로 선택된 문장으로 구성되며, 레이블 NotNext(False)를 가집니다.

어찌 보면 굉장히 단순한 작업이지만, NSP 작업을 통해 BERT는 두 문장 간의 관계를 이해하는 능력을 학습하게 되고, 이로 인해 QA(Question Answering)나 NLI(Natural Language Inference)와 같은 다운스트림 작업을 더 잘 수행하게 된다고 하네요.
The NSP task is closely related to representationlearning objectives used in Jernite et al. (2017) and Logeswaran and Lee (2018). However, in prior work, only sentence embeddings are transferred to down-stream tasks, where BERT transfers all parameters to initialize end-task model parameters
이 부분은 - BERT의 NSP task가 이전 연구 (Jernite et al., 2017; Logeswaran and Lee, 2018)에서 영감을 받기는 했지만, 두 문장 사이의 관계를 파악하도록 CLI 토큰을 사용한 것은 BERT의 독창적인 아이디어다 - 정도로 이해하고 넘어가겠습니다.
3-2. Fine-tuning BERT
For each task, we simply plug in the task-specific inputs and outputs into BERT and finetune all the parameters end-to-end.
BERT의 파인튜닝(fine-tuning)은 사전 학습된 모델의 모든 파라미터를 end-to-end 방식으로 업데이트합니다.
At the input, sentence A and sentence B from pre-training are analogous to
(1) sentence pairs in paraphrasing,
(2) hypothesis-premise pairs in entailment,
(3) question-passage pairs in question answering, and
(4) a degenerate text-∅ pair in text classification or sequence tagging.
BERT의 사전 학습에서 사용된 문장 A와 문장 B의 구조는 파인튜닝을 통해 다양한 다운스트림 작업에 적용될 수 있어요. 예를 들어서,
- Paraphrasing: 두 문장이 서로 같은 의미를 전달하는지 평가할 수 있습니다.
- Entailment: 문장 A는 가설(hypothesis), 문장 B는 전제(premise)일 때, 이 두 문장이 포함 관계에 있는지 판단할 수 있습니다.
- Question Answering: 문장 A는 질문(question), 문장 B는 답변을 포함한 문맥(context)일 때, 문맥에서 질문에 대한 답을 찾는 질의응답 작업을 수행할 수 있습니다.
- Text Classification or Sequence Tagging: 문장 A는 텍스트, 문장 B는 빈 값(∅)일 때, 단일 문장 분류 작업이나 시퀀스 태깅 작업을 수행할 수 있습니다.

At the output, the token representations are fed into an output layer for tokenlevel tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as entailment or sentiment analysis.
출력 단계에서는 2가지 작업이 이루어집니다.
- Token-Level Tasks (토큰 레벨 작업)
- 입력 시퀀스의 각 토큰에 대해 BERT는 벡터 representation을 생성하고, 이 벡터는 각 토큰의 의미와 문맥 정보를 담고 있습니다. 이 representation이 출력 레이어로 전달되면 Sequence Tagging (시퀀스 태깅)이나 Question Answering (질문 응답) 등의 다운스트림 태스크를 수행할 수 있습니다.
- Sequence Tagging (시퀀스 태깅): 예를 들어, 입력 문장에서 각 단어를 명사, 동사 등으로 태깅하는 작업입니다. "I am eating an apple"라는 문장이 주어지면, 각 단어에 대해 'I: PRON', 'am: VERB', 'eating: VERB', 'an: DET', 'apple: NOUN'와 같이 태깅합니다.
- Question Answering (질문 응답): 문맥 내에서 질문에 대한 답을 찾는 작업입니다. 예를 들어, "What is the color of the sky?"라는 질문이 주어졌을 때, "The sky is blue"라는 문맥에서 "blue"라는 단어를 찾아내는 작업입니다.
- 입력 시퀀스의 각 토큰에 대해 BERT는 벡터 representation을 생성하고, 이 벡터는 각 토큰의 의미와 문맥 정보를 담고 있습니다. 이 representation이 출력 레이어로 전달되면 Sequence Tagging (시퀀스 태깅)이나 Question Answering (질문 응답) 등의 다운스트림 태스크를 수행할 수 있습니다.
- Sentence-Level Tasks (문장 레벨 작업)
- BERT에서 입력 시퀀스의 첫 번째 토큰인 [CLS] 토큰이 벡터로 변환되고, 이 벡터는 입력 시퀀스 전체를 대표하는 의미를 담고 있습니다. 이 CLS representation이 출력 레이어로 전달되면 entailment 또는 sentiment analysis 등의 문장 전체에 대한 예측을 수행할 수 있습니다.
- Entailment (포함 관계 판단): 두 문장이 포함 관계에 있는지 판단하는 작업입니다. 예를 들어, "The cat is on the mat" (전제)와 "There is a cat on the mat" (가설)가 주어졌을 때, 포함 관계(True/False)를 예측합니다.
- Sentiment Analysis (감정 분석): 입력 문장의 감정이 긍정적인지 부정적인지 분류하는 작업입니다. 예를 들어, "I love this movie"라는 문장이 주어졌을 때, 감정이 긍정적인지 부정적인지 예측합니다.
- BERT에서 입력 시퀀스의 첫 번째 토큰인 [CLS] 토큰이 벡터로 변환되고, 이 벡터는 입력 시퀀스 전체를 대표하는 의미를 담고 있습니다. 이 CLS representation이 출력 레이어로 전달되면 entailment 또는 sentiment analysis 등의 문장 전체에 대한 예측을 수행할 수 있습니다.
Compared to pre-training, fine-tuning is relatively inexpensive.
사전 학습에 비해 파인튜닝은 상대적으로 굉장히 비용 효율적이고, 논문의 모든 결과는 단일 Cloud TPU에서 최대 1시간, GPU에서는 몇 시간 내에 재현할 수 있다고 하네요.
마무리
BERT 논문을 리뷰하면서 언어 모델의 사전 학습과 전이 학습이 자연어 처리에서 얼마나 중요한 역할을 하는지 깊이 이해할 수 있었습니다. 특히, BERT가 문맥을 이해하는 인코더를 구현하기 위해 양방향 아키텍처, MLM, NSP 작업을 적절히 고안하고 배치한 점이 무척 인상깊었어요. 자본과 기술력 뿐만 아니라 창의적이고 새로운 아이디어로 인공지능 혁신을 이어가는 모델들을 리뷰할 때마다 경이로움을 느끼게 됩니다.
저는 Long-Context를 처리해야 하는 LLM / QA task 솔루션 개발이라는 과제를 맡으면서 버트 논문을 리뷰하게 되었는데요. 최신 QA task들은 Long-Context를 처리하기 위해 버트 기반의 인코더 중심 모델뿐만 아니라 RAG 기술을 적용한 GPT 기반 디코더 중심 모델을 사용하고 있기도 한다는 사실을 알았습니다. 따라서 다음 논문 리뷰로는 OpenAI의 ChatGPT 초기 모델을 선정하여 구조를 파악해보려고 합니다.
이것으로 BERT 논문 리뷰를 마치겠습니다. 읽어주셔서 감사합니다 :-)
'Data Science > DL 딥러닝' 카테고리의 다른 글
| 딥러닝 | 효율적인 파인튜닝에 관한 고찰 - LoRA(2021) 논문 리뷰, peft, unsloth (0) | 2024.08.01 |
|---|---|
| 딥러닝 | RAG 활용 pdf파일 검색 챗봇시스템 구현하기 (4) | 2024.07.24 |
| 딥러닝 | 트랜스포머 positional encoding 코드 구현 (문제 해결) (0) | 2024.07.06 |
| 딥러닝 | Microsoft 테이블 트랜스포머 PubTables-1m(2021) 논문 리뷰 (0) | 2024.07.04 |
| 딥러닝 | Transformer Huggingface 탐방, pipline 가지고 놀기(객체 탐지) (1) | 2024.07.02 |