Dice Score
U-Net 코드화 작업을 통해 image segmentation에서 흔히 사용되는 'dice score'라는 평가 지표와 친숙해지게 되었습니다. 다이스 스코어는 아래와 같은 수식을 통해 계산합니다.

Dice Score는 Precision과 Recall 점수를 나타내는 F1-Score와 비슷합니다. 민감도와 정밀도중에 무엇이 좋고 나쁜지는 까봐야 아는 것도 똑같고요.

도식화하면 위와 같은 그림으로 나타낼 수 있어요. 여기서 X와 Y는 각각 true value와 predicted value라고 생각하면 되겠습니다. Image segmentation에서 Dice score는 predicted value와 true value 간의 유사성을 측정할 수 있는 포괄적인 평가 방식인 거죠.
예측한 마스크와 실제 마스크가 정확하게 일치하는 경우 dice score는 1의 값을 가지게 되고, 전혀 일치하지 않는 경우 0의 값을 가지게 됩니다. 따라서 계산된 dice score는 범위 [0, 1] 사이의 값을 가지게 되고, 마치 accuracy처럼 1에 가까운 값을 가지게 될수록 모델이 학습을 잘했다고 판단하게 됩니다.
문제 상황
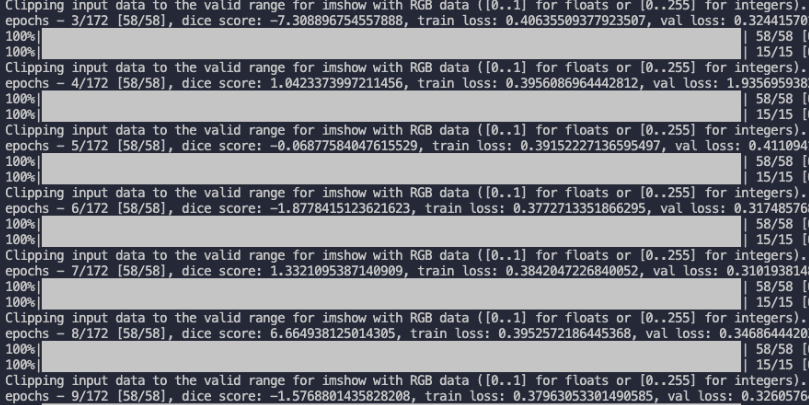
그런데 코드 작업을 하면서, 아래와 같이 dice score가 범위 [0, 1]를 벗어난 값을 가지게 되는 것을 확인하게 되었습니다.
https://www.kaggle.com/datasets/faizalkarim/flood-area-segmentation
Flood Area Segmentation
Segment the flooded area.
www.kaggle.com
저는 U-Net을 코드 구현하면서 kaggle의 Flood Area Segmentation 데이터를 가지고 작업중이었는데요. Kaggle에서 다른사람들이 쓴 코드는 어떤지 확인을 한 번 해 보았습니다.
다른 사람 코드 1
https://www.kaggle.com/code/gon213/flood-area-by-gontech

Dice score가 0, 1 사이로 제대로 나오고 있군요.
다른 사람 코드 2
https://www.kaggle.com/code/hugolearn/practice-image-segmentation-with-u-net/notebook

요건 저랑 다른 데이터셋 (Carvana dataset) 사용하는 다른사람 코드인데, 보시면 dice score가 음수값이 나옵니다. 더 보면 -5가 나오기도 하고요... 그런데 다들 코드 잘썼다고 칭찬만 하고 이부분을 지적하는 사람이 없더라고요.
문제 해결
Dice score를 정확하게 계산하기 위해서 저는 아래와 같은 방법을 적용해서 문제를 해결했습니다 :) 참고로 제가 다루고 있는 데이터는 '홍수가 난 부분'과 '아닌 부분'으로 binary label을 가집니다.
1. 수식 변경
def dice_score(pred: torch.Tensor, mask: torch.Tensor, threshold: float = 0.5, smooth: float = 1e-6):
# 시그모이드 적용 후 임계값을 통해 이진화
pred = torch.sigmoid(pred)
pred = (pred > threshold).float()
# 마스크가 float 타입인지 확인
mask = mask.float()
# 교집합과 합집합 계산
intersection = (pred * mask).sum(dim=[1, 2, 3])
union = pred.sum(dim=[1, 2, 3]) + mask.sum(dim=[1, 2, 3])
# Dice score 계산
dice = (2. * intersection + smooth) / (union + smooth)
# 배치의 평균 Dice score 반환
return dice.mean().item()처음에는 intersection과 union만 계산했는데, 0.5의 threshold와 smooth값을 추가해서 dice score를 정밀하게 계산했습니다.
2. 데이터 정규화
먼저 가지고 있는 Image와 Mask 데이터의 픽셀값이 0과 1 사이의 수치로 들어와 있는 것을 확인했습니다. 이후 Image data에만 Normalization transform을 적용해주었습니다. (기존에는 정규화를 아예 안했습니다.)
class Mydataset(Dataset):
def __init__(self, root_dir='flood/', train=True, image_transforms=None, mask_transforms=None):
super(Mydataset, self).__init__()
self.train = train
self.image_transforms = image_transforms
self.mask_transforms = mask_transforms
# 파일 경로 지정
file_path = os.path.join(root_dir, 'train')
file_mask_path = os.path.join(root_dir, 'masked')
# 이미지 리스트 생성
self.images = sorted([os.path.join(file_path, img) for img in os.listdir(file_path)])
self.masks = sorted([os.path.join(file_mask_path, mask) for mask in os.listdir(file_mask_path)])
# train, valid 데이터 분리
split_ratio = int(len(self.images) * 0.8)
if train:
self.images = self.images[:split_ratio]
self.masks = self.masks[:split_ratio] # train은 80%
else:
self.images = self.images[split_ratio:]
self.masks = self.masks[split_ratio:] # valid는 20%
def __getitem__(self, index: int):
original = Image.open(self.images[index]).convert('RGB') # index 번째의 이미지를 RGB 형식으로 열음
masked = Image.open(self.masks[index]).convert('L') # 얘는 마스크를 L(grayscale) 형식으로 열음
if self.image_transforms: # 나중에 image augmentation에 사용됨
original = self.image_transforms(original)
if self.mask_transforms: # 나중에 image augmentation에 사용됨
masked = self.mask_transforms(masked)
return {'img': original, 'mask': masked} # transform이 적용된 후 텐서를 반환
def __len__(self):
return len(self.images) # 이미지의 파일 수를 반환함 -> train = True라면 train 데이터셋의 크기를, False라면 valid 데이터셋의 크기를 반환
# ------------------------ data loader 정의하기 ------------------------ #
width = 360
height = 240
batch_size = 4
n_workers = 2
# 이미지만 정규화!
image_transforms = T.Compose([
T.Resize((width, height)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 마스크는 정규화 안할거임
mask_transforms = T.Compose([
T.Resize((width, height)),
T.ToTensor()
])
train_dataset = Mydataset(root_dir = "flood/",
train = True, # train 용 지정
image_transforms = image_transforms,
mask_transforms = mask_transforms)
valid_dataset = Mydataset(root_dir = "flood/",
train = False, # valid 용 지정
image_transforms = image_transforms,
mask_transforms = mask_transforms)
train_dataset_loader = DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True,
num_workers = n_workers)
valid_dataset_loader = DataLoader(dataset = valid_dataset,
batch_size = batch_size,
shuffle = True,
num_workers = n_workers)

이후 Dice Score 값이 [0, 1] 범위로 잘 계산되는 것을 확인할 수 있었습니다.
감사합니다 :)
'Data Science > DL 딥러닝' 카테고리의 다른 글
| 딥러닝 | Microsoft 테이블 트랜스포머 PubTables-1m(2021) 논문 리뷰 (0) | 2024.07.04 |
|---|---|
| 딥러닝 | Transformer Huggingface 탐방, pipline 가지고 놀기(객체 탐지) (1) | 2024.07.02 |
| 딥러닝 | U-Net(2015) 논문 리뷰 02 _ PyTorch 코드 구현 (1) | 2024.06.30 |
| 딥러닝 | U-Net(2015) 논문 리뷰 (0) | 2024.06.27 |
| 딥러닝 | 트랜스포머(2017) 논문 리뷰 - Attention is all you need (0) | 2024.06.21 |




